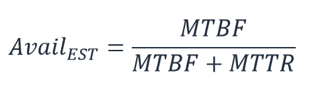Resilient Architectures are resilient when the solution has high availability, fault tolerance and MTTR and MT. #resilient
Knowlege
- API creation and management : [[API Gateway]], REST API
- AWS managed services with appropriate use cases: AWS Transfer Family, Amazon [[SQS]],[[Secrets Manager]].
- [[Caching]] Strategies
- Design principles for microservices: stateless workloads compared with stateful workloads.
- Event-driven architectures.
- Horizontal scaling and vertical scaling.
- How to appropriately use edge accelerators: CloudFront [[CDN]].
- Load Balancing Concepts.
- Multi-tier architectures.
- Queuing and messaging concepts: publish-subscribe.
- Serverless technologies and patterns: AWS [[Lambda]] and AWS [[Fargate]].
- Storage types with associated characteristics: Object, File, Block.
- The orchestration of containers: [[ECS]], [[EKS]].
- When to use read replicas.
- Workflow orchestration: AWS Step Functions. 16. Skills:
- Designing event-driven, microservices, and multi-tier architectures based on requirements.
- Determining scaling strategies for components used in an architectural design.
- Determining the AWS services for components used in an architecture design.
- Determining the AWS services required to achieve loose coupling based on requirements.
- Determining when to use containers.
- Determining when to use serverless technologies and patterns.
- Recommending appropriate compute, storage, networking, and database technologies based on requirements.
- Using purpose-built AWS services for workloads.
- AWS Global Infrastructure: [[AZ]], Regions, Route 53.
- AWS managed services with appropriate use cases: [[Comprehend]], [[Polly]].
- Basic networking concepts: Route tables.
- Disaster Recovery strategies: Backup and restore, pilot light, warm standby, active-active failover, recovery point objective [[RPO]], recovery time objective [[RTO]]
- Distributed design patterns.
- Failover strategies.
- Immutable infrastructure.
- Load balancing concepts: [[ALB]].
- Proxy concepts: [[RDS#RDS Proxy]] .
- Service quotas and throttling.
- Storage options and characteristics: Durability, replication.
- Workload visibility: AWS [[X-Ray]].
- Skills:
- Determining automation strategies to ensure infrastructure integrity.
- Determining the AWS services required to provide a highly available and fault-tolerant architecture across AWS Regions and AZ.
- Identifying metrics based on business requirements to deliver a highly available solution.
- Implementing designs to mitigate single points of failure.
- Implementing strategies to ensure the durability and availability of data.
- Selecting an appropriate [[DR]] strategy to meet business requirements.
- Using AWS services that improve the reliability of legacy applications and applications not built for the cloud.
- Using purpose-built AWS services for workloads.
Availability quantitatively measure resiliency.