Replies: 3 comments 19 replies
-
|
There's been some work done during the ICESat-2 Hackweek 2023 to benchmark reading ICESat-2 ATL03 data from an s3 bucket using different libraries and file formats. See:
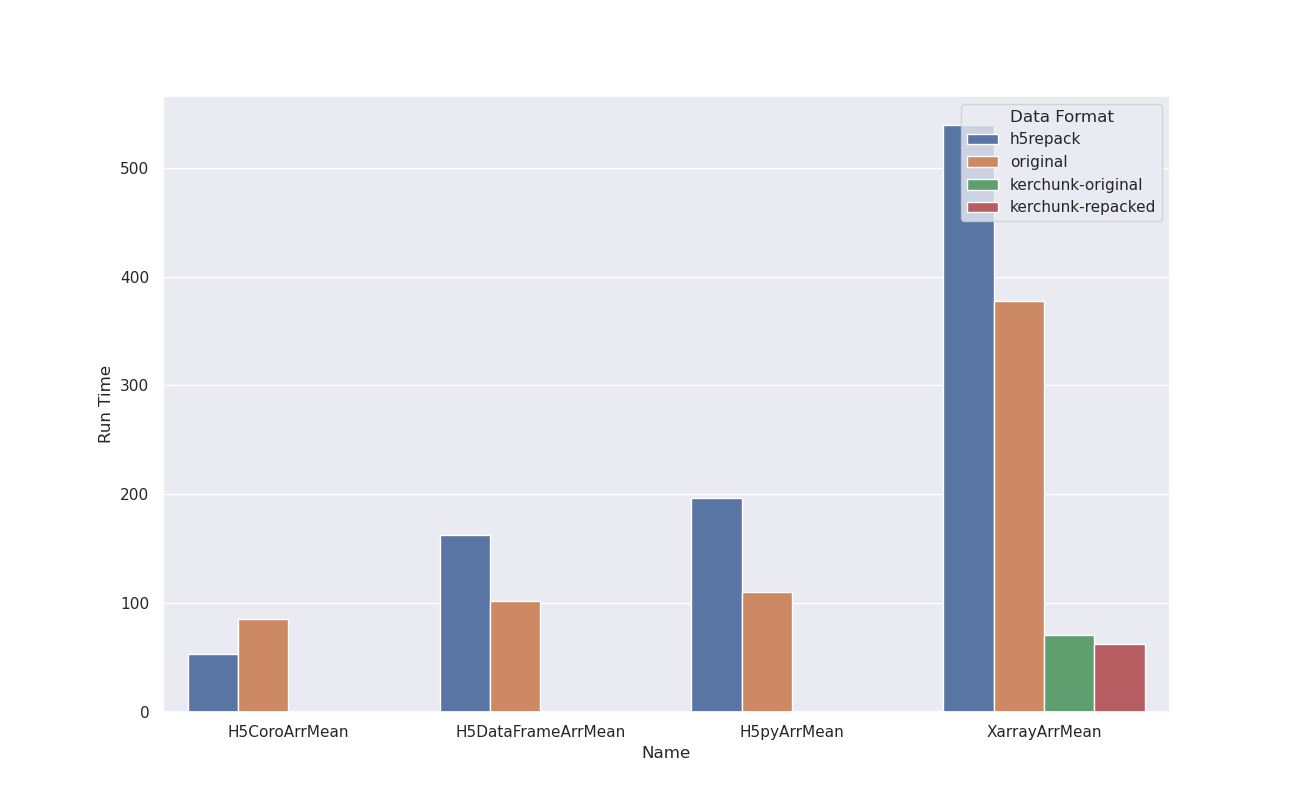
Preliminary results from ICESAT-2HackWeek/h5cloud@1f34411:
Observations:
Caveats: Note that the above ATL03 dataset is a non-gridded point-cloud-like dataset, and may not apply to other HDF5 data structures, so be careful when generalizing this to all HDF5 data files. Next stepsSome of these are outlined by @abarciauskas-bgse at ICESAT-2HackWeek/h5cloud#18:
|
Beta Was this translation helpful? Give feedback.
-
|
@alex-s-gardner As far as I am aware (although I haven't dug into the underlying library modules used, xarray, h5coro, gedi_subsetter and h5py) no multithreading was used. I do know that the tests were run on a cryocloud JupyterHub instance with an allocated 32-40GB Memory and 4-8 CPU. |
Beta Was this translation helpful? Give feedback.
-
|
Just wanted to add that h5coro implements multithreading under the hood. That is one of the two major advantages it has over h5py. The other is that it caches the structure of the file as it traverses it, I suppose building a sort of "on the fly" internal kerchunk. |
Beta Was this translation helpful? Give feedback.
-
|
Hidefix also does parallell reading, as well as some parallell decoding (which turns out to be a significant part of xarray load time). |
Beta Was this translation helpful? Give feedback.
-
|
(there is also talk about parallelising decoding in zarr/numcodecs, particularly for GPUs, but this is not yet ready; obviously this is less relevant in dask workflows) |
Beta Was this translation helpful? Give feedback.
-
|
Thanks to @jonm3D we now have a tool to rapidly visualize HDF/NetCDF file's structure https://github.com/jonm3D/h5xray. This tool will be very handy when we get to benchmark access to HDF data in cloud storage. |
Beta Was this translation helpful? Give feedback.
-
Cloud optimized HDF5 works!Well, seems like cloud-optimized HDF5 is indeed possible and the mixed numbers we initially got were the result of not understanding the default IO and caching behavior of There are some caveats, Exhibit A)Using h5py to calculate a mean (~47000000 data points) in a 7GB file in-region (us-west-2)
Observations
Exhibit B)Doing the same operation using Xarray, in-region access on the same 7GB file
Observations
Now let's see what happens when we try to do the same operation over 2 files but this time out of region... Exhibit C)Out of region access
Observations
We are working on a set of recommendations specifically for ICESat-2 data and we'll share more findings once we have the document ready. |



Beta Was this translation helpful? Give feedback.
-
Well, kerchunk hopes to decode once, so that reading the created reference set is one-step and doesn't access the constituent data files. Yes, we've had to spend quite some effort getting concatenation in the presence of different CF time "units" fields right. |
Beta Was this translation helpful? Give feedback.
-
|
Yes certainly kerchunk is a major performance enhancement, but I'm hoping to convince our data center friends here that even if you can, perhaps you shouldn't when it comes to HDF in the cloud. |
Beta Was this translation helpful? Give feedback.
-
|
Of course, if straight-to-zarr is an option, that's different. Or using normal time units. Or at the very least having a consistent epoch... Data centres do still seem to like using the most established format and conventions, and also the ability to just download some part of the data as self-contained, self-describing files. |
Beta Was this translation helpful? Give feedback.
-
|
Hopefully this was not interpreted as a critique to Xarray decoding, I think the overall objective of this topic is to understand different access patterns and their tradeoffs when it comes to accessing archival data in the cloud. I see cloud-optimized HDF5 as a multiplier for approaches like kerchunk or even pangeo-forge pipelines (if they have to transform HDF to Zarr). If used, generating the references for kerchunk can benefit from already consolidated metadata in the HDF5 file, anecdotally I noticed a ~5x improvement (PR coming to kerchunk). I also wonder if we should copy/follow up this valuable conversation on this thread in Pangeo |
Beta Was this translation helpful? Give feedback.
-
Looking forward to it :) |
Beta Was this translation helpful? Give feedback.
-
|
Hi, Great results! Have you attempted to use xarray and dask with the processes scheduler? I'm experimenting with this, but for some unknown reason, the volume of data (Total Req) is huge, leading to longer processing times. For instance: import xarray
import dask
import fsspec
dask.config.set(scheduler="processes")
URL = "..."
fs = fsspec.open(URL, cache_type="blockcache", block_size=8*1024*1024)
ds = xarray.open_dataset(
fs.open(),
engine="h5netcdf",
driver_kwds={
"page_buf_size": 32*1024*1024,
"rdcc_nbytes": 8*1024*1024
}).chunk({...}) # align with file chunking
ds["variable"].mean().compute(num_workers=8) |
Beta Was this translation helpful? Give feedback.
-
|
The best caching scheme for HDF5 is usually "first", especially if you set the block size big enough to contain all front matter of the file. Of course, the processes cannot share this in-memory cache, so it may well not be doing too much that is helpful for you. You might also want to try "blockcache::" prepended to your URL for (shared) on-disk block caching, but you would need to create your store directory first ( |
Beta Was this translation helpful? Give feedback.
-
Maybe this is what's happening, I'd try using Martin's suggestion for a shared cache on disk. Another thing, the |
Beta Was this translation helpful? Give feedback.
-
|
Thank you both for the insightful comments. Indeed, utilizing the "first" caching scheme improves things, but the volume of data read remains huge when employing Dask processes. I will experiment with the disk-shared cache and provide feedback if I make any progress. While HDF5 paged aggregation notably enhances performance, it appears from the numbers you've presented that there is a substantial increase in Total Req Bytes for all Exhibits, which can be exacerbated in some cases, such as process parallelism. Anyway, a lot of interesting stuff happening :) |
Beta Was this translation helpful? Give feedback.
-
|
@zequihg50 I forgot to mention, the total requested bytes in the graph is a bit misleading because fsspec logs do not track cache hits (PR coming!) meaning the actual requested bytes is way less than the ones in the charts I posted. |
Beta Was this translation helpful? Give feedback.
-
Based on the latest discussions on Openscapes about HDF in the cloud, I think there should be a more in-depth study of the state of things, in a way a "follow up" to this post from Matt Rocklin https://matthewrocklin.com/blog/work/2018/02/06/hdf-in-the-cloud
earthaccessusesfsspecfor IO but the HDF libraries usually used to read these files(h5py,pyhdf) were not designed for concurrent access via python file-like objects and IO latency for data in the cloud is really problematic. Here is a list of some of the access patterns used for HDF data in remote storage systems:earthaccessuses, it works but is really slow(not necessarily fsspec's fault), see: h5py sequential reads in the cloud it may also run into deadlock issues when multiple files are accessed.no stand-alone client librarynew development!!, H5Coro has a stand alone client and could be a great drop-in replacement for H5Py on certain casesIdeally we could come up with a better understanding of these access patterns: their capabilities, bottlenecks and potential workarounds.
Beta Was this translation helpful? Give feedback.
All reactions