{kind=link}
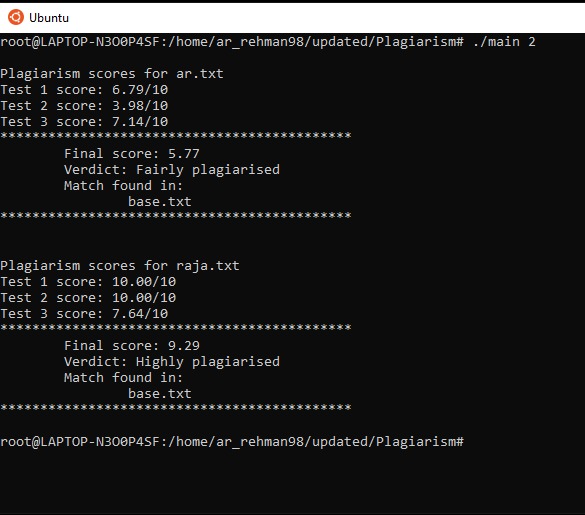
Uses naive methods to detect observable plagiarism in text files.
Target file's word count is matched with each individual textfile's token counts in the database folder to find a high degree of similarity in the tokens and their frequency of use.
A direct match of consecutive tokens (or ngrams) was performed to detect similarity in patterns and neighbourhood of tokens. The value of N for the N-Gram generation was varied and a cumulative result was obtained by a weighted average over all of the results.
Cosine of the angle between the vectors obtained from the target and the base text files is computed to estimate the simiilarity in the token vectors of both the files.
1. Place all the reference text files in the database directory.
2. Place all the text files required to be checked in the target directory.
3. (Optional) Edit the stopwords.txt text file as per requirement, to add words which are to be ignored in the analysis.
4. Change the database and target_folder variables with the actual location of them.
5. Compile run.cpp in C++11 (or above), with the command g++ run.cpp -std=c++11.
6. Run the generated executable with the command ./a.out (in Linux environment).