 est une application web permettant d'explorer et comparer de façon ludique les clichés d'un observatoire photographique du paysage.
est une application web permettant d'explorer et comparer de façon ludique les clichés d'un observatoire photographique du paysage.
Un observatoire photographique du paysage (OPP) est un outil de gestion territoriale dont le principe consiste à photographier régulièrement le même point de vue. Les séries photographiques ainsi obtenues nous aident à mieux percevoir les évolutions paysagères.
Cette application a été développée par l'Entente Interdépartementale des Causses et des Cévennes dans le but de valoriser de façon ludique nos clichés et ceux de nos partenaires. Le code source est publié ici afin de favoriser les réutilisations.
Découvrez en action avec les données de notre OPP : observatoire.causses-et-cevennes.fr/opp
Cette application nécessite uniquement une exécution côté client. Autrement dit, un simple navigateur internet récent suffit à son fonctionnement. Le déploiement côté serveur se limite donc au dépôt des fichiers statiques et il n'est pas nécessaire de configurer une base de donnée côté serveur.
Le développement repose sur les technologies web traditionnelles et en particulier sur la librairie Javascript Leaflet qui est ici utilisée à la fois pour l'affichage de la carte et des photos. Le choix a été fait de ne pas utiliser de framework. Comme souvent avec les programmes javascript, les données alimentant l'application doivent être au format JSON.
L'application est prévue pour être, autant que possible, personnalisable et réutilisable avec tout type d'OPP. Néanmoins, des efforts restent à faire pour pouvoir s'adapter à toute la diversité des OPPs existants et de nombreuses améliorations sont envisageables. Si vous êtes intéressé pour contribuer au développement de cet outil par l'intermédiaire de ressources humaines ou financières contactez nous à observatoire@causses-et-cevennes.fr
Le guide ci-dessous décrit les différentes étapes de déploiement. Il est destiné à des personnes compétentes en informatique mais qui ne sont pas nécessairement des développeurs web. Ainsi, le guide se veut didactique mais aborde de nombreuses notions qu'il vous faudra peut-être approfondir par ailleurs. D'une manière générale nous cherchons à maintenir un déploiement qui soit le plus simple et accessible possible, mais la préparation des données et un préalable important qui peut nécessiter beaucoup de travail.
Avant de déployer l’application vous devez au préalable disposer d'une base de données structurée de votre OPP. C'est à dire à minima de fichiers tableurs répertoriant toutes les informations relatives aux points de vue et faisant l’inventaire de vos photos. Voici ci dessous un exemple de modèle relationnel pour l'organisation des données.
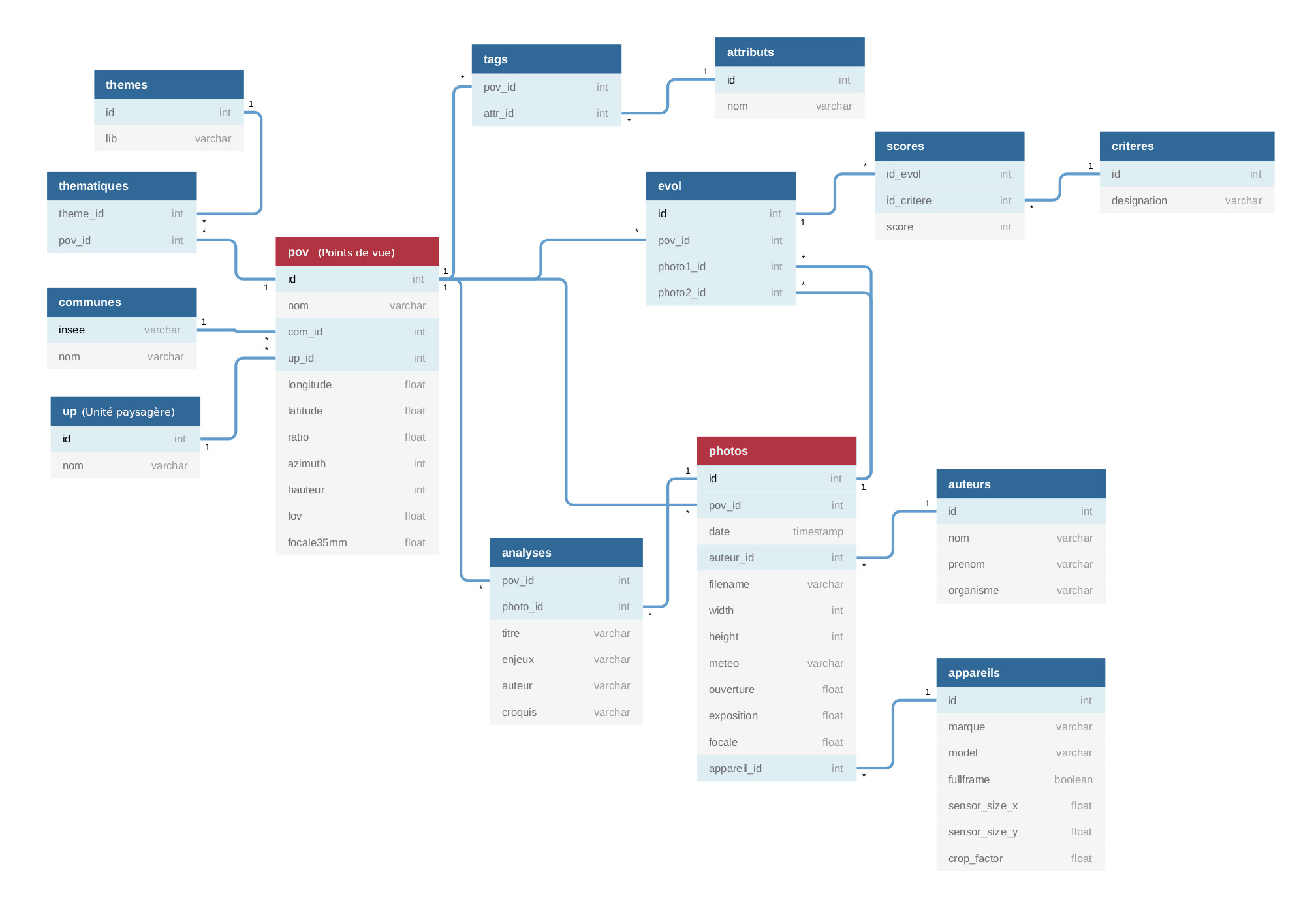
Cette structuration n'est pas requise en l'état pour le fonctionnement de l'application. Le schéma contribue ici uniquement à apporter une vue d'ensemble des données typiques d'un OPP, il peut servir d'inspiration pour la mise en place d'une base de données relationnelle côté serveur.
Pour alimenter l'application, à minima deux tables sont requises (en rouge sur le schéma) : la liste des points de vue de l'itinéraire photographique et la liste de toutes les photos pour tous les points de vue. Il est indispensable de bien distinguer les deux tableaux.
L'approche la plus simple consiste donc à préparer uniquement ces deux tableaux dans un logiciel tableur. Dans ce cas, vous pouvez prévoir d'intégrer directement dans ces tables toutes les données relationnelles que vous souhaitez valoriser. Par exemple le nom de la commune peut être intégré directement dans la table des points de vue. Les noms et prénoms du photographe directement dans la table des photos etc. Il est aussi possible de maintenir un modèle relationnel avec des tables séparées puis d'opérer des jointures SQL à posteriori. Quelque soit l'approche choisie, pour que les données puissent être consommées par l'application elles devront être transposées au format geojson (cf. section création du fichier GeoJSON). La méthode qui sera préférée pour l'écriture du geojson peut orienter la façon dont vous allez décider de structurer votre base de données.
Dans tous les cas, pour ces deux tables, certaines informations sont indispensables au bon fonctionnement de l'application, et doivent obligatoirement être présentes.
Table des points de vue
-
Numéro unique : permet d'identifier sans ambiguïté un point de vue
-
Longitude et latitude : les coordonnées géographiques du point. Elles doivent être exprimées en degrés décimaux (proscrire les notations en degrés minutes secondes). Un degré vaut très approximativement 100km, donc compter quatre chiffres après la virgule pour une précision de 10m.
-
Ratio : rapport entre la largeur et la hauteur de l'image. Le ratio est un attribut du point de vue car toutes le photos doivent respecter ces proportions même si leur résolution pixel diffère au fil du temps. Cette donnée est indispensable pour afficher la photo dans son canevas sans déformation et pour garantir l'alignement des photos d'une série dans laquelle le ratio effectif peut varier sensiblement.
Tables des photos
-
Numéro du point de vue : le numéro du point de vue doit obligatoirement apparaître dans la table des photos car c'est lui qui permet de faire le lien entre les deux tables.
-
Date : la date de la prise de vue sera utilisée comme identifiant unique de la photo au sein d'un même point de vue. Pour représenter vos dates utilisez le format anglo-saxon (
yyyy-mm-dd) qui a l'avantage de permettre le tri par ordre chronologique. Il n'est pas nécessaire d'inclure des champs séparés pour l'année, le mois et le jour, ces valeurs seront automatiquement dérivées de la date. -
Fichier : la table des photos doit absolument contenir des informations permettant de déterminer le chemin d'accès vers le fichier image correspondant. Calculer le chemin dépend de l'arborescence des dossiers que vous allez déployer pour le stockage des photos. Par exemple :
photos/{NUM}/{DATE}/{FILENAME}.jpg: ici les variables requises pour construire le chemin sontNUM,DATEetFILENAMEphotos/{YEAR}/{FILENAME}.jpg: ici une organisation sensiblement différentephotos/{NUM}_{DATE}_{NOM}.jpg: dans cet exemple il n'y a pas de sous dossier, c'est le nom du fichier en lui même qui est composé par des variables séparées par un underscorewww.mastructure.fr/opp/{NUM}/{DATE}: ici le chemin sera une url spécifique
A vous donc de déterminer et inclure les variables nécessaires au calcul des chemins ou url et de nommer vos fichiers photos en suivant des règles de formatage strictes permettant leur détermination de façon logique, par exemple :
{NUM}_{DATE}_{NOM}.jpg
Les noms de certains champs requis sont prédéfinis : NUM, LON, LAT, RATIO pour la table des points de vue et DATE pour les photos. Ces champs doivent être présents dans vos données et nommés tel quel en respectant les majuscules.
Au delà de ces champs requis, vous aurez certainement besoin d'afficher d'autres informations. A vous d'inclure dans votre base toutes les données que vous jugerez utiles et nécessaires, il n'y a aucune restriction ni contrainte sur le nom des champs. La façon dont ces champs seront affichés sera définie dans un second temps via des fichiers de configuration, ce qui offre une grande flexibilité. Ci-dessous quelques exemples de données potentiellement utiles :
Table des points de vue
-
Des informations de localisation :
-
nom / lieu-dit : un nom d'usage pour le point de vue, il s'agit souvent du lieu-dit
-
commune : le nom de la commune où se trouve le point
-
unité paysagère : le secteur paysager d'appartenance du point de vue
-
-
Des données relatives à la prise de vue :
-
azimut : angle de visée en degré. Si le champs
AZIMUTHest présent alors il sera automatiquement utilisé pour l'affichage d'une rose des vents indiquant l'orientation du point de vue. -
hauteur : hauteur du pieds en cm
-
champ de vision (Field Of View) : largeur du champs horizontal en degrés
-
focal 35mm : la focale équivalente pour un capteur de 35mm
-
-
Des éléments d'analyse :
-
thème(s) : la ou les thématiques suivies par cette vue
-
descriptif : descriptif de la photo
-
enjeux : listing des enjeux identifiés
-
Table des photos
-
Des informations sur l'auteur :
-
nom / prénom : permet de pouvoir renseigner les mentions de droit d'auteur
-
organisme : structure d'appartenance du photographe
-
-
Des données relatives à la prise de vue :
-
ouverture : Valeur d'ouverture du diaphragme exprimée par le dénominateur de la fraction simplifiée focale / diamètre d'ouverture
-
exposition / vitesse : Temps d'exposition en fraction de seconde (valeur du dénominateur)
-
focale : Valeur de la distance focale utilisée en mm (cette donnée n'a de sens que si l'on connait la taille du capteur utilisé)
-
appareil : la référence de l'appareil photo utilisé dont dépend notamment la taille du capteur et le crop factor
-
largeur / hauteur : la résolution en pixels de la photo
-
L'utilitaire exiftool peut vous aider à dresser la liste des photos en extrayant automatiquement les métadonnées qu'elles contiennent (date, coordonnées GPS, focale ...). Ci dessous un exemple de commande :
exiftool.exe -r -csv -n -FileName -FileSize -FileType -CreateDate -ImageWidth -ImageHeight -Orientation -Aperture -ExposureTime -FocalLength -FocalLengthIn35mmFormat -FOV -HyperfocalDistance -ISO -GPSLatitude -GPSLatitudeRef -GPSLongitude -GPSLongitudeRef "INPUT_FOLDER" > output.csv
Options :
-r recursive folders scan
-n get coordinates as signed decimal degrees
Il est préférable de maintenir les photos dans leur résolution initiale pour préserver leur niveau de détail. Néanmoins, dans un contexte web, des solutions doivent être adoptées afin de limiter au maximum les temps d'affichage. La première option consiste à optimiser la compression jpeg pour réduire le poids des fichiers, la seconde s'appuie sur la mise en place d'un tuilage permettant de découper l'image suivant un ensemble de grilles adaptées au niveau de zoom de l'affichage.
L'application d'une compression jpeg est la meilleurs solution pour réduire le poids d'une image et accélérer son temps de transfert. Néanmoins, il peut être difficile de déterminer le meilleur compromis entre poids et qualité de l'image. De façon conventionnelle, un facteur de compression de 75% (pourcentage de qualité) est un bon point de départ pour un usage web, il ne serait pas raisonnable de viser un taux plus élevé. En revanche une compression plus forte (60 à 70%) peut s'envisager.
Par ailleurs, pour offrir la meilleur expérience utilisateur possible, il est souhaitable de générer des jpeg dits progressifs. En effet, ce format intègre des versions en basse résolution de la photo qui seront chargées en priorité par le navigateur web. Ainsi, le navigateur peut afficher rapidement une image qui sera ensuite progressivement affinée au fur et à mesure que le téléchargement progresse. Les jpeg non progressifs se chargent quand à eux par bandes horizontales du haut vers le bas ce qui peut imposer un délai important avant affichage de l'image complète. L'unique contrepartie des jpeg progressifs est que le poids des fichiers augmentent sensiblement.
L'utilitaire Imagemagick peut être utilisé pour convertir toutes vos photos en jpeg progressif en un seule commande.
Exemple de traitement par lot de tous les fichiers jpg d'un dossier sur une machine Linux
for file in *.jpg; do magick $file -interlace plane -strip -quality 75% ./progressive/$file; done;Equivalent sous Windows:
for %f in (*.jpg) do magick %f -interlace plane -strip -quality 75% ./progressive/%fWindows Powershell:
foreach ($f in Get-ChildItem "." -filter *.jpg) { magick $f -interlace plane -strip -quality 75% ./progressive/$f }Options :
-
-interlace plane: création d'un jpg progressif -
-strip: suppression des données exif (peut contribuer à réduire sensiblement le poids des fichiers)
D'autres options sont à considérer pour optimiser le poids des images :
-
-gaussian-blur 0.05: ajoute un très léger flou à l'image ce qui permet d'écrêter les hautes fréquences de l'image et ainsi d'améliorer fortement les performances de l'algorithme de compression. La réduction de la taille du fichier est de l'ordre de 20 à 30% ce qui est considérable. La décision d'appliquer ou non un flou doit donc être mûrement réfléchie, ci-dessous une comparaison illustre, à titre indicatif, l'impact d'un flou de 0.05 sur une image ici zoomée à 125%. Dans un contexte web ce niveau d'altération semble raisonnable et le gain de poids améliorera considérablement la réactivité de l'application, encore une fois il s'agit de trouver un juste milieu.
-
-sampling-factor 4:2:0: réduit le résolution chromatique de moitié ce qui permet un gain sensible de poids pour un impact très peu perceptible par l'oeil humain. Voir Wikipedia pour plus d'explication sur ce paramètre. A noter qu'il semble que4:2:0soit déjà la valeur par défaut utilisée par ImageMagick (la documentation n'est pas explicite à ce sujet). Cette option peut être combinée avec l'option-define jpeg:dct-method=floatqui permet un calcul plus précis mais sensiblement plus lent (source).
Traiter un grand nombre de photos implique de choisir un taux de compression commun et donc de décider d'un compromis. Des images comportant beaucoup de détails supportent plus facilement une forte compression (50 à 60%) alors qu'un gradient de bleu dans un ciel nécessitera une très faible compression (85 - 90%), la vision humaine étant très sensible aux variations de teinte dans les zones homogènes. L'efficacité d'une compression jpeg est en réalité très dépendante de la composition de l'image et ce qui rend le résultat final difficilement prédictible. Certaines stratégies peuvent être mise en place pour essayer de déterminer le facteur de compression optimal pour une image donnée :
-
La comparaison des courbes représentant respectivement l'évolution du poids du fichier et l'évolution de la qualité visuelle de l'image en fonction du taux de compression permet de mieux comprendre l'effet de la compression.
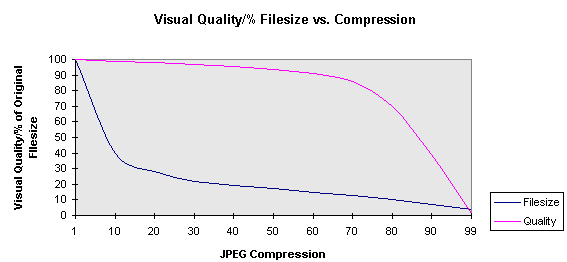
On observe que le poids du fichier diminue très rapidement pour des pourcentages de compression faible (10 à 20% ou 80 à 100% si on exprime la valeur en pourcentage de qualité) alors que l'impact sur la qualité de l'image est très faible. Par la suite le gain de poids est beaucoup plus modéré alors que la qualité de l'image se dégrade rapidement. On peut donc rechercher la valeur de compression optimale en appliquant successivement des taux de compression de plus en plus fort. L'optimum est atteint quand le gain de poids par rapport l'itération précédente tombe en dessous d'un seuil donné, c'est à dire quand la nouvelle compression se conclue par réduction mineure du poids du fichier mais un impact probablement significatif sur la qualité de l'image. Ce genre de procédure peut facilement être automatisée.
-
D'autres méthodes s'appuie également sur une approche itérative mais cette fois un mesurant un indicateur de la qualité visuelle d'une image, comme par exemple l'indicateur SSIM. L'idée est de déterminer le taux compression le plus fort permettant de maintenir l'indicateur de qualité visuelle au dessus d'un seuil donné. Cette approche est bien plus précise que la méthode précédente car la qualité est cette fois mesurée et non présagée. L'utilitaire jpeg-recompress peut être utilisé pour ce travail. Pour autant cette approche automatique n'apporte pas nécessaire une grande plus-value. Par exemple avec un jeu de donnée test, en visant une qualité dite moyenne on obtient des taux de compression optimum majoritairement entre 70 et 75%, ce qui correspond au taux généralement préconisés. Néanmoins pour certaines photos l'optimum est significativement plus haut ou plus bas, aussi il peut être intéressant d'exécuter l'outil pour identifier ces fichiers.
La questions des débits de connexion devrait aussi être prise en compte dans la réflexion. Plus les temps de téléchargement des photos seront courts et plus l'application sera agréable à utiliser. Or le débit de téléchargement est très variable d'un utilisateur à l'autre pouvant aller de 1Mbit/s pour les cas les plus défavorables à 30Mbit/s avec la fibre. Prenons par exemple une connexion plutôt faible de 2Mbit/s, un octet valant 8 bits le débit est de 0.25Mo/s. Pour télécharger une photo de 4Mo il faudra donc 16 secondes ce qui est considérable. Bien entendu il s'agit d'un exemple défavorable mais ces débits se rencontrent encore fréquemment. Par ailleurs l'utilisateur lambda affichera en peu de temps plusieurs points de vue ou bien naviguera rapidement entre les différentes photos d'un point de vue, générant ainsi de nombreuses requêtes. Il faut savoir qu'une requête lancée ne sera pas stoppée par le navigateur web même si la photo n'a plus besoin d'être affichée à l'écran. C'est une stratégie des navigateurs web qui consiste à toujours préférer aller au bout du téléchargement d'une ressource de façon à pouvoir la mettre en cache pour la suite. Or l'utilisateur doit partager son débit entre les différentes ressources en cours de téléchargement, donc si deux photos sont affichées simultanément cela double leur durée de téléchargement et plus l'utilisateur aura de requêtes en cours, plus les temps de téléchargement augmenteront. On a donc tout intérêt à ce qu'un téléchargement se termine le plus rapidement possible de façon à ne pas encombrer la bande passante et permettre aux dernières photos demandées de s'afficher rapidement. En revanche côté serveur, peu de chance de saturer la bande passante à moins d'avoir des milliers d'utilisateurs connectés simultanément.
Le tuilage consiste à découper la photo en un ensemble de tuiles de 256 pixels suivant une pyramide de zoom permettant d'adapter la résolution de l'image en fonction du niveau de zoom. En effet, pour les vues d'ensemble une faible résolution suffit alors que les vues de détail nécessiteront la résolution maximale mais sur une petite zone de l'image seulement. Avec le tuilage l'utilisateur ne télécharge que les parties de l'images nécessaires, dans une résolution adaptée. La photo peut donc s'afficher très rapidement car, à tout moment, le nombre de tuiles nécessaires pour remplir la fenêtre de visualisation est réduit et constitue une faible quantité de données à transférer. De plus le téléchargement des tuiles se lance de façon asynchrone ce qui fait gagner du temps lorsqu'il s'agit de transférer de nombreux fichiers de petite taille.
Pour autant, l'intérêt du tuilage se pose compte-tenu de l'avènement de la fibre et sachant que même avec des photos de plus de 20Mpx le poids compressé n'excédera pas 5 à 6 Mo. La réalisation d'un tuilage pourrait paraître disproportionnée.
La librairie Leaflet étant adaptée à l'affichage de données cartographiques tuilées, il est possible de détourner cette fonctionnalité pour des photos tuilées. Côté base de donnée, il est nécessaire d'inclure dans la table des photos les informations concernant la résolution originale de l'image via l'ajout des propriétés WIDTH et HEIGHT.
La préparation des tuiles nécessite un traitement préalable qui peut être réalisé à l'aide du script Python voppTiler.py. Dans un premier temps il faut installer Python puis le package Pillow avec la commande pip3 install pillow. Pour l'exécution du programme, tous les paramètres optionnels peuvent être laissés par défaut : indiquer la source de l'image à traiter est suffisant. Exemple de commande pour traiter l'ensemble d'un dossier :
Linux :
for file in *.jpg; do python3 voppTiler.py $file -d TILES -c; done;Windows :
for %f in (*.jpg) do python3 voppTiler.py %f -d TILES -cWindows Powershell:
foreach ($f in Get-ChildItem "." -filter *.jpg) { python3 voppTiler.py $f -d TILES -c }Pour référence, l'ensemble des paramètres disponibles sont décrit ci-dessous :
-
source: nom du fichier image à tuiler -
-d: dossier de destination des tuiles. Les tuiles générées sont toujours placées dans un nouveau dossier du même nom que l'image. Par défaut ce dernier est placé dans le même dossier que l'image, ce paramètre permet de spécifier un autre dossier de destination. A noter qu'en complément des tuiles l'outil génère également un fichier json décrivant le tuilage. -
-kext: définie si le dossier, du même nom que l'image, qui contiendra les tuiles doit aussi inclure l'extension du fichier dans son nom (par défaut cette dernière est exclue). -
-s: taille des tuiles, par défaut 256px. Doit être constant pour toutes les photos. -
-o: nombre de pixels de recouvrement entre 2 tuiles, par défaut 0. Cette option étend la taille des tuiles de la valeur spécifiée sur la droite et vers le bas. Peut être utile pour résoudre des problèmes d'affichage où les tuiles n'apparaissent pas parfaitement jointive (cf. rapport de bug Leaflet), dans ce cas un pixel de recouvrement sera suffisant. Doit être constant pour toutes les photos. -
-i: taille initiale utilisée comme référence pour calculer le tuilage. Deux valeurs sont possibles :-
TILESIZE: (valeur par défaut) au niveau de zoom minimum, l'image est représentée par une unique tuile de 256px. Le plus grand des côtés de l'image couvre l'intégralité des 256px. Les niveaux de zoom suivant sont calculés en respectant cette règle ainsi, quelque soit la résolution originale de l'image son plus grand côté couvre toujours l'intégralité de la grille. La pyramide de zoom est constante : 256, 512, 1024, 2048, 4096, 8192 ... Cette méthode facilite la comparaison d'images de résolution différentes mais en contrepartie la photo n'est jamais présentée directement dans sa résolution originale. Par exemple une image de 5616 pixels de large sera représentée au niveau de zoom 5 par 4096 pixels (sous-échantillonnage) puis 8192 pixels au niveau suivant (sur-échantillonnage). Du fait du sur-échantillonnage, le poids total des tuiles excède toujours le poids initial de l'image. Le sur-échantillonnage pourrait être réduit en choisissant un meilleur candidat pour la taille des tuiles, mais il ne sera pas possible d'aligner correctement 2 images dont le tuilage diffère ce qui limite la comparaison. -
IMAGESIZE: le niveau de zoom maximum est déterminé en fonction du nombre minimum de tuiles nécessaire pour couvrir la résolution originale de l'image, les niveaux de zoom précédant sont calculés en fonction de cette référence. Par exemple pour une image de 5616 pixels de large il faut 22 tuiles de 256px ce qui donne alors la pyramide suivante : 5632, 2816, 1536, 768, 512, 256. Cette méthode permet de respecter la résolution originale de l'image mais en contrepartie chaque niveau de zoom impose une marge dans les deux directions. Dans notre exemple les largeurs effectives de l'image seront : 5616, 2808, 1404, 702, 351, 175,5. Cette méthode ne peut pas être utilisée pour comparer des photos de résolutions différentes.
-
-
-t: template utilisé pour construire l'arborescence des fichiers, par défaut{z}_{x}_{y}, cela signifie que toutes les tuiles seront dans le même dossier et nommées par les composantes de leur coordonnée séparées par un underscore (ex:0_0_0.jpg). Pour les tuilages générant énormément de fichiers il peut être préférable de les ventiler dans des sous-dossiers, par exemple{z}/{x}_{y}pour 2 niveaux ou bien{z}/{x}/{y}pour 3 niveaux. -
-c: précise si les tuiles incomplètes doivent être coupées ou bien maintenue dans leur taille initiale -
-z: facteur de zoom, par défaut 2. Ne pas modifier. -
-f: format des tuiles (jpg ou png), par défaut jpg -
-q: qualité de la compression jpeg, par défaut 75 -
-r: algorithme de ré-échantillonnage, par défaut lanczos
Les vignettes ou thumbnails sont des versions basse résolution des photographies qui seront utilisées à des fins de prévisualisation dans la ligne de temps. Pour les générer par lot il est possible d'utiliser l'utilitaire ImageMagick. La commande ci-dessous illustre la création de vignettes dont le plus grand des côtés n'excédera pas 512px :
Linux :
for file in *.jpg; do magick $file -thumbnail 512x512 ./THUMBS/$file; done;Windows :
for %f in (*.jpg) do magick %f -thumbnail 512x512 ./THUMBS/%fWindows Powershell:
foreach ($f in Get-ChildItem "." -filter *.jpg) { magick $f -thumbnail 512x512 ./THUMBS/$f }Autre exemple Powershell permettant de traiter un ensemble de sous dossiers en créant automatiquement le dossier de destination
foreach ($d in Get-ChildItem -Directory) {
New-Item -path $d -name "thumbs" -ItemType "directory"
foreach ($f in Get-ChildItem $d -filter *.jpg) {
$name = $f.name
convert $f -thumbnail 512x512 $d/thumbs/$name
}
}Il peut être souhaitable d'ajouter les mentions de droit d'auteur à travers l'application d'un filigrane (watermark) sur la photo. Le script voopWatermark.py peut être utilisé pour réaliser cette tâche sur l'ensemble des clichés en s'appuyant sur la base de données des photos pour renseigner le nom de l'auteur.
Exemple de commande :
python voppWatermarker.py photos.csv inFolder outFolder "{FILENAME}.jpg" "© {YEAR} {AUTEUR}" -c 255 255 255 255 -bg 0 0 0 150 -ff arial -fs 20 -pos bottomright -pad 10 -mg 10Description des paramètres:
-
datafile: nom du fichier csv de la table des photos -
source: nom du dossier contenant les photos à traiter -
destination: nom du dossier de destination pour les photos marquées -
filename-template: le template permettant de construire les noms de fichier à partir des données de la table des photos -
watermark-template: le template à appliquer pour construire la mention de copyright à partir des données de la table des photos -
-c: couleur RGBA du texte de la marque. Par défaut en blanc (255 255 255 255) -
-bg: couleur RGBA de l'arrière plan de la marque. Par défaut en noir avec transparence (0 0 0 150) -
-ff: la police d'écriture de la marque. Doit correspondre au nom du fichier .ttf ciblé, par défaut arial. C'est ici que l'on peut choisir les variantes de police en gras, italique ... -
-fs: la taille de la police exprimée en millième de la hauteur de la photo. Par exemple pour une photo de 2500px de hauteur, une valeur de 20 correspondra à une taille de police de 50px, soit 2% de la hauteur de l'image. Exprimée la valeur de cette façon permet de pouvoir obtenir des tailles de police proportionnellement équivalentes pour des photos de dimensions variables. Valeur par défaut : 20. -
-pos: position du copyright, choix parmi les valeurstopleft,topright,bottomleft,bottomright -
-pad: la valeur de padding, c'est à dire de la marge entre le texte et les limites de son arrière plan. Exprimée en millième de la hauteur de la photo, valeur par défaut : 10. -
-mg: valeur de la marge entre les bords de l'image et la position de la marque. Exprimée en millième de la hauteur de la photo, valeur par défaut : 10.
Quelque soit la façon dont les données seront stockées (simple tableur ou système d'information), elles devront être transmises à l'application au format GeoJSON. Le GeoJSON est un format d'échange de données géographiques s'appuyant sur la notation utilisée en javascript pour décrire des objets. C'est donc un format de choix pour alimenter des applications web codées en javascript.
Un JSON est un fichier textuel balisé dans lequel les données sont présentées sous la forme d'un couple clé : valeur. Par rapport à des données tabulaires classiques, la clé représente en fait le nom de la colonne, c'est pourquoi on dit que c'est un format auto-descriptif. Autre particularité, il est possible de structurer les données de façon hiérarchique ce qui n'est pas possible avec des tableaux en deux dimensions. Le Format GeoJSON quand à lui, définit simplement un cadre général et partagé pour écrire des données géographiques en JSON :
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties" : {},
"geometry": {
"type": "Point",
"coordinates": []
}
}
]
}L'attribut features représente la liste des géométries et de leurs propriétés. Dans notre cas il s'agira de la liste des points de vue avec toutes les données associées dont la liste des photos, ce qui donne par exemple le modèle suivant :
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"NUM": 1,
"NOM": "La Garde Guérin",
"COMMUNE": "Prévenchère",
"THEME": "Développement touristique",
"RATIO": 1.5,
"PHOTOS": [
{
"AUTEUR": "HEBRAUD Frédéric",
"FILENAME": "001_2014_CAUE34_6_D48_MTL_LaGardeGuérin.jpg",
"DATE": "2014-06-14"
},
{
"AUTEUR": "HEBRAUD Frédéric",
"FILENAME": "001_2017_CAUE34_6_D48_MTL_LaGardeGuérin.jpg",
"DATE": "2017-06-29"
}
]
},
"geometry": {
"type": "Point",
"coordinates": [
3.93487,
44.47815
]
}
}
]
}Notez comment la relation entre la table des points de vue et la table des photos aboutit à une relation hiérarchique dans le JSON. Cette particularité est requise pour le bon fonctionnement de l'application. Pour le reste des propriétés, vous êtes libre de structurer l'information comme bon vous semble. Il s'agit ici d'un exemple minimaliste, le fichier GeoJSON peut contenir l'intégralité de votre base de données.
Bien que les fichiers GeoJSON soient relativement lisibles par les humains, il est absolument proscrit d'essayer de les écrire à la main, il faut nécessairement passer par l'intermédiaire d'un programme. Plusieurs solutions sont possibles selon le contexte :
-
Le logiciel QGIS peut être utilisé pour créer des GeoJSON à partir de formats de données géographiques traditionnels type Shapefile ou Geopackage. Dans notre cas, ce n'est pas une option possible car la structure du fichier GeoJSON nécessite de combiner deux tables (points de vue et photos). Il faut donc opter pour une solution sur mesure.
-
Si vos données sont intégrées dans un système d'information alors votre moteur de base de données dispose certainement de fonctions SQL pour générer des sorties GeoJSON par l'exécution d'une requête adaptée.
-
Si vous utilisez uniquement des tableurs, vous pouvez vous appuyer sur le programme Python proposé dans le dossier
script, et dont le fonctionnement est détaillée ci-dessous.
Au préalable il vous faut installer le moteur Python indispensable à l'exécution du script : www.python.org
Le fichier contenant le code à exécuter se nomme vopp_csv2json.py et se trouve dans le dossier script.
Les données d'entrée doivent être au format CSV, il s'agit d'un format d'échange textuel pour les tableurs, les valeurs de chaque colonnes sont séparées par un caractère spécial généralement un point-virgule. Il vous faut donc convertir vos deux tables (points de vue et photos) depuis votre logiciel tableur vers le format CSV. Choisissez de préférence la tabulation comme séparateur de champs et l'encodage UTF-8.
Le script va permettre de générer en une commande un nouveau fichier GeoJSON combinant vos deux fichiers CSV (points de vue et photos). Outre le séparateur de colonne, le script peut prendre également en compte deux autres caractères de séparation permettant :
-
la séparation des colonnes (clés) en sous dictionnaire
-
la séparation des valeurs en liste
Prenons par exemple le tableau ci-dessous:
| NUM | NOM | COMMUNE | THEMES | RATIO | ANALYSE.TITRE | ANALYSE.DESCRIPTION | ANALYSE.ENJEUX |
|---|---|---|---|---|---|---|---|
| 1 | lieudit1 | commune1 | theme1;theme2 | 1,5 | Titre 1 | description1 | enjeu1;enjeu2 |
| 2 | lieudit2 | commune2 | theme | 2,5 | Titre 2 | description2 | enjeu1;enjeu2;enjeu3 |
En utilisant le . comme séparateur de clé on peut générer un sous-dictionnaire ANALYSE. Parallèlement certaines colonnes utilise le ; comme séparateur de valeur, ce qui traduit une liste de valeurs. Ainsi, en utilisant ces séparateurs il est possible de générer le JSON suivant :
{
"1": {
"NOM": "lieudit1",
"COMMUNE": "commune1",
"THEMES": [
"theme1",
"theme2"
],
"RATIO": 1.5,
"ANALYSE": {
"TITRE": "Titre 1",
"DESCRIPTION": "description1",
"ENJEUX": [
"enjeu1",
"enjeu2"
]
}
},
"2": {
"NOM": "lieudit2",
"COMMUNE": "commune2",
"THEMES": "theme",
"RATIO": 2.5,
"ANALYSE": {
"TITRE": "Titre 2",
"DESCRIPTION": "description2",
"ENJEUX": [
"enjeu1",
"enjeu2",
"enjeu3"
]
}
}
}Pour exécuter le programme Python, ouvrez une console système depuis le dossier script où se trouve le fichier Python. Placez dans ce même dossier vos deux fichiers CSV. Les paramètres de la commande à rédiger sont les suivants :
-
csvfile-pov: Nom du fichier csv listant les points de vue -
csvfile-photos: Nom du fichier csv listant les photos -
-o: Nom du fichier geojson à générer. Valeur par défaut :opp.geojson -
-pov: Libellé du champs indiquant le numéro du point de vue dans la table des photos. Valeur par défaut :NUM -
-lon: Libellé du champs indiquant la longitude. Valeur par défaut :LON -
-lat: Libellé du champs indiquant la latitude. Valeur par défaut :LAT -
-ks: Caractère utilisé pour séparer les clés et ainsi définir un dictionnaire de propriétés enfants. Valeur par défaut :'.' -
-as: Caractère utilisé pour séparer les valeurs dans un tableau. Valeur par défaut :';' -
-f: Liste des champs à inclure (permet donc de filtrer les champs que l'on souhaite exporter). Si rien n'est indiqué tous les champs seront exportés. -
-csv-sep: Caractère séparateur de champs du fichier csv. Valeur par défaut :'\t'(tabulation) -
-csv-nl: Caractère de fin de ligne du fichier csv. Valeur par défaut :'' -
-csv-chart: Encodage du fichier csv. Valeur par défaut :'utf8' -
-i: Indique si le fichier geojson doit être indenté
Exemple :
python3 vopp_csv2json.py pov.csv photos.csv -o opp.geojson -pov NUM -ks '.' -as ';' -csv-sep '\t' -i -f NUM NOM COMMUNE THEME RATIO DATE AUTEUR FILENAMENotes:
-
les 3 types de séparateurs doivent être différents pour éviter toute confusion
-
n'intégrez que les colonnes dont vous aurez utilité pour ne pas augmenter inutilement le poids du fichier de sortie
-
utilisez dans un premier temps le paramètre -i pour indenter le fichier de sortie, cela facilitera sa lecture et donc le contrôle du résultat produit. Si la sortie est valide, générez à nouveau le fichier mais cette fois sans indentation de façon à réduire considérablement le poids du fichier.
L'application dispose d'une fonctionnalité pour l'affichage de croquis réalisés sur la base des photographies. Les croquis sont des outils didactique utiles pour appuyer l'analyse d'une photographie. Pour une expérience utilisateur optimale, il est préférable de disposer de croquis dessinés précisément en proportions avec la photo de référence, autrement les outils de comparaison seront inutiles car le croquis impossible à aligner avec les photos.
Pour le moment il n'est possible d'intégrer qu'un seul croquis par point de vue. Pour activer la fonctionnalité, il faut renseigner une nouvelle propriété SKETCH dans le GeoJSON qui doit suivre pour partie le format suivant :
"SKETCH": {
"FILENAME": "001_2014.jpg",
"AUTEUR": "xxx",
"YEAR": 2019,
"PHOTOREF": 2014,
"WIDTH": 5000,
"HEIGHT": 4100,
"MARGINS": {
"LEFT": 250,
"RIGHT": 250,
"BOTTOM": 550,
"TOP": 550
}Cette structuration est plutôt rigide, les champs ci-dessous doivent être présents et strictement nommés de la même façon :
-
PHOTOREF: Il s'agit de la date de la photo de référence utilisée pour la réalisation du croquis -
WIDTHetHEIGHT: largeur et hauteur de l'image en pixels -
MARGINS: si le croquis contient des annotations elles se trouveront certainement dans les marges. Pour pouvoir superposer le dessin sur la photo il faut donc nécessairement connaitre qu'elles seront les dimensions en pixels de ces marges.
Côté tableur cela donne les noms de champs suivants : SKETCH.FILENAME SKETCH.AUTEUR SKETCH.DATE SKETCH.PHOTOREF SKETCH.WIDTH SKETCH.HEIGHT SKETCH.MARGINS.LEFT SKETCH.MARGINS.RIGHT SKETCH.MARGINS.TOP SKETCH.MARGINS.BOTTOM
La préparation des dessins demande un peu de travail si l'on veut homogénéiser les marges et les dimensions des images. L'outil ImageMagick peut être à nouveau utile ici pour faire des modifications par lot, avec particulier avec l'option extent. Notez que les croquis ne doivent pas être tuilés, néanmoins cette limitation n'est pas gênant ce type d'image donne d'excellent taux de compression, les fichiers sont donc assez légers pour permettre un affichage rapide.
Le dossier src contient l'ensemble du code source de l'application qu'il faudra déployer côté serveur. L'organisation des fichiers et sous-dossiers proposée est la suivante :
-
à la racine, le tryptique opp.html, opp.js et opp.css correspond au cœur de l'application, ces fichiers n'ont normalement pas à être modifiés
-
toujours à la racine les fichiers themes.json et providers.json correspondent aux fichiers de configuration qu'il vous faudra cette fois modifier. Leur contenu est décrit dans les sections suivantes.
-
le dossier
dataest prévu pour contenir les fichiers GeoJSON (données sources de chaque OPP ou bien couches géographiques complémentaires) -
le dossier
photosest quand à lui destiné à stocker les fichiers jpg des photos -
le dossier
iconscontient toutes les images mobilisées dans l'interface graphique (symboles, logo...) -
les dossiers
libetjscontiennent des fichiers javascript dont dépend l'application, vous n'avez pas à vous en occuper -
le dossiers
layerscontient un fichier javascript pour chaque couche supplémentaire à afficher. Il s'agit d'un bloc de code personnalisé définissant le style de ces couches et leur légende. (voir section ajout de couches supplémentaires) -
le dossier
templatescontient du code HTML personnalisé à intégrer dans certaines parties de l'interface graphique. (voir section préparation des templates)
L'organisation des sous-dossiers n'est pas figée, il est possible de la modifier à partir du moment où les fichiers de configuration sont adaptés en conséquence.
Un thème permet de personnaliser l'application en définissant
-
des paramètres de style (couleurs, logos, titres)
-
les sources de données à afficher
-
des paramètres de configuration concernant le fonctionnement de l'application
Les thèmes sont définis dans le fichier themes.json. Il est possible de configurer autant de thème que l'on souhaite, pour charger un thème autre que le thème par défaut, il suffit de passer un paramètre supplémentaire dans l'url, exemple : observatoire.causses-et-cevennes.fr/opp?theme=cc
Le contenu du fichier est un simple objet JSON présentant les différents paramètres et leurs valeurs.
{
"key" : "cc",
"default" : true,
"domains" : ["observatoire.causses-et-cevennes.fr"],
"title" : "Observatoire Photographique du Paysage des Causses et Cévennes",
"description" : "Explorez et comparez les clichés de l'observatoire photographique du paysage culturel des Causses et des Cévennes",
"headerLogo" : "icons/logos/cc_logo.png",
"headerTextColor" : "#404040",
"headerBkgColor" : "linear-gradient(to left, #618BCD, white)",
"toolbarColor" : "linear-gradient(to top, white, #778bad)",
"providers" : {"CC":{}, "PNC":{}, "34":{"enable":false}},
"layers": ["limits_cc", "up_cc"],
"basemaps": ["osm", "ignOrtho"],
"about" : "templates/about.html",
"browserHistory": false,
"constrainMapExtent": true,
"viewmode": "SINGLE",
"saveDates": true,
"initPOVnumber": "1"
}-
key : il s'agit d'un identifiant unique pour votre thème. La valeur pourra être passée dans l'url. Proscrire les accents, espaces ou autres caractères spéciaux.
-
default : indique si le thème doit être chargé par défaut (c'est à dire en l'absence d'un paramètre dans l'url). Il ne peut y avoir qu'un seul thème par défaut.
-
domains : propriété facultative permettant d'associer le thème à un nom de domaine particulier. Utile lorsque l'on veut faire pointer des sous domaines vers un différents thèmes.
-
title : le titre du thème, correspond au titre qui sera affiché dans la barre d'en-tête de la page web ainsi que dans la balise title du document HTML (utilisée pour l'indexation du site par les moteurs de recherche)
-
description : une présentation courte de la page à destination du référencement par les moteurs de recherche, sera intégré dans une balise meta du document HTML.
-
headerLogo : lien vers le fichier image qui sera utilisé comme logo
-
headerBkgColor : valeur CSS définissant la couleur de fond pour la barre d'en-tête
-
toolbarColor : valeur CSS définissant la couleur de fond pour la barre d'outil verticale
-
toolbarIconBaseColor : valeur CSS définissant la couleur des icônes de la barre d'outil
-
toolbarIconSelectColor : valeur CSS définissant la couleur des icônes actifs
-
providers : la liste des fournisseurs d'OPP que l'on souhaite afficher. La configuration des fournisseurs est décrite plus bas. La liste est rédigée sous la forme d'un dictionnaire permettant si besoin de modifier des propriétés du fournisseur pour ce thème.
-
layers : la liste des couches supplémentaires que l'on souhaite afficher sur la carte (par exemple les limites communales, ou bien les entités paysagères). La configuration de couches additionnelles est décrite plus bas.
-
basemaps : liste des fonds de carte utilisables avec ce thème. Il s'agit de service tuilés OGC dont la configuration est décrite plus bas.
-
about : url vers le template html qui sera affiché dans le panneau "à propos"
-
browserHistory : indique si lorsque l'on change de point de vue il faut ajouter l'url à l'historique de navigation.
-
constrainMapExtent : restreindre les déplacements dans la vue carto et dans les photos de façon à rester centré sur la zone d'intérêt
-
viewmode : le mode de visualisation par défaut :
- 'SINGLE' : Vue simple avec une seule photo
- 'SPLIT' : Vue comparée de deux photos synchronisées
- 'SBS' : vue comparée avec séparateur glissant
- 'SPOT' : Vue comparée avec une loupe
-
saveDates : Mémoriser les dates (années plus ancienne et plus récente) entre deux points de vue
-
initPOVnumber : l'identifiant du point de vue à afficher en premier (point de vue appartenant au premier fournisseur indiqué dans la liste des providers)
La configuration du thème permet de renseigner un titre et une description spécifique à chaque thème. Ces données sont injectées via javascript dans le code html respectivement dans les balises title et meta. Ces balises sont ensuite utilisées par les robots d'indexation des moteurs de recherche, leur contenu conditionne donc la façon dont le site apparaît dans la liste des résultats. En théorie les moteurs de recherches sont capables d'indexer des pages dont le contenu dépend de code javascript. Néanmoins ce processus est complexe et coûteux ce qui ralentit l'indexation de plus, le rendu peut échouer pour différentes raisons (erreur js, timeout...). C'est pourquoi, en pratique, il vaut mieux éviter de générer dynamiquement les métadonnées afin d'éviter le risque d'une indexation peu qualitative et, pour ce faire, il est préférable de renseigner en dur les balises title et meta dans le fichier opp.html :
<title>Observatoire Photographique du Paysage des Causses et Cévennes</title>
<meta name="description" content="Remontez le temps en explorant et comparant les clichés de l'observatoire photographique
du paysage culturel des Causses et des Cévennes, inscrit sur la liste Patrimoine Mondial de l'UNESCO ! Au travers de séries
photographiques reconduites régulièrement, découvrez un témoignage exceptionnel de la culture agro-pastorale méditerranéenne
et suivez ses évolutions récentes."/>
L'application permet d'afficher plusieurs OPP que ce soit des itinéraires différents ou bien des OPP gérés par vos partenaires. Un fournisseur d'OPP est donc une source de données à part entière définie par un fichier GeoJSON distinct et un ensemble de fichiers images correspondant aux photos. La façon dont ces données doivent être intégrées dans l'application est décrite dans le fichier de configuration providers.json.
Comme précédemment il s'agit d'un simple fichier JSON présentant les différents paramètres et leurs valeurs. Néanmoins, ici certains paramètres doivent être configurés avec des variables. Ces dernières sont identifiées par des doubles accolades et leurs noms font référence à vos noms de champs dans votre base de données initiale (et donc dans le fichier GeoJSON). A noter qu'il est possible d'appeler les variables YEAR, MONTH et DAY car elles sont calculées automatiquement à partir des date de prise de vue.
[
{
"key" : "CC",
"enable" : true,
"name" : "Causses & Cévennes",
"shortName" : "C\u0026C",
"datafile" : "data/opp_cc.geojson",
"svgMarker" : "icons/marker_blue.svg",
"clusterColor" : "#2981cbc8",
"photoUrl" : "photos/CC/{{YEAR}}/{{FILENAME}}",
"thumbUrl" : "photos/CC/{{YEAR}}/THUMBS/{{FILENAME}}",
"tiled" : false,
"sketch": "croquis/{{SKETCH.FILENAME}}",
"infosPanel" : "templates/infospanel_cc.mst",
"popup" : "{{NUM}} - {{NOM}}",
"photoAttrib" : "© {{YEAR}} {{AUTEUR}}",
"filters" : {"THEME":"Thématique", "COMMUNE":"Commune"},
"searchKeys": ["NUM", "NOM", "COMMUNE", "THEME", "UP", "SECTEUR", "PHOTOS.AUTEUR", "PHOTOS.DATE"],
"searchResultsTemplate": ["{{NOM}} ({{SECTEUR}})", "n°{{NUM}} {{YEARMIN}} > {{YEARMAX}}"]
}
]-
key : identifiant unique pour le fournisseur d'OPP
-
enable : indique si par défaut les points de vue de cet OPP doivent être affichés sur la carte
-
shortName : 3 caractères maximum, qui seront représentés dans la légende, peut être un texte vide
-
datafile : chemin d'accès vers le GeoJSON
-
svgMarker : chemin d'accès vers le symbole SVG qui sera utilisé pour représenter un point de vue
-
clusterColor : style CSS renseignant la couleur de fond des clusters. Les clusters désignent les symboles générés par le regroupement sur la carte de plusieurs points, lorsque l'échelle ne permet pas de les distinguer clairement.
-
photoUrl : url template permettant de construire le chemin d'accès aux photos, les variables sont recherchées dans les propriétés du point de vue et dans les propriétés de la photo concernée. Si les couches sont tuilées il faut également renseigner le template permettant d'accéder aux tuiles via leurs coordonnées, par exemple
{z}_{x}_{y}. -
thumbUrl : url template permettant de construire le chemin d'accès aux thumbnails (vignettes) qui seront affichées dans la ligne de temps.
-
tiled : indique si les photos sont tuilées ou non
-
sketch : url template permettant de construire le chemin d'accès aux croquis, les variables sont recherchées dans les propriétés du point de vue
-
infosPanel : lien vers le fichier template décrivant l'affichage des données dans le panneau d'information (voir plus bas), les variables renseignées dans le template sont recherchées dans les propriétés du point de vue
-
popup : template à utiliser pour renseigner le popup, les variables sont recherchées dans les propriétés du point de vue
-
photoAttrib : template à utiliser pour renseigner l'auteur d'une photo, les variables sont recherchées dans les propriétés de la photo concernée. Ce template est également utilisé pour définir le texte d'attribution des croquis, les variables doivent donc aussi exister dans le sous dictionnaire
SKETCH. -
filters : permet d'indiquer les propriétés des points de vue qui seront utilisées comme variable de filtrage dans le panneau de recherche. A chaque champs spécifié correspondra une liste déroulante contenant les valeurs unique contenues dans ce champs. Les filtres sont indiqués sous la forme d'un dictionnaire dont la clé est le nom de la variable et la valeur correspond au label qui sera utilisé dans l'interface graphique.
-
searchKeys : liste des propriétés du geojson qui seront prises en compte par le moteur de recherche par texte libre. Les sous-dictionnaires sont accessibles en utilisant le point comme séparateur de clé.
-
searchResultsTemplate : template définissant le formatage des résultats d'une recherche. Cette variable est définie sous la forme d'une liste de template, chaque entrée correspondant à une ligne distincte. Ainsi il possible de formater l'affichage sur plusieurs ligne, la première ayant une police de caractère plus importante que les suivantes.
A noter que le fichier de configuration permet de définir la couleur des clusters mais que ce paramètre n'a aucune influence sur la couleur du symbole SVG utilisé pour représenter un point. Cela signifie que pour mettre les couleurs en cohérence il est nécessaire de modifier manuellement le symbole SVG. Ceci peut être réalisé très facilement avec l'aide d'un logiciel de dessin vectoriel type Inkscape.
Afin de personnaliser les informations à afficher dans le panneau d'information, il faut paramétrer un template HTML dans lequel seront définies à la fois l'organisation des éléments HTML et l'utilisation de variables. Ce fichier porte l'extension *.mst car il est destiné à être traiter par le moteur de template Mustache (le nom fait référence aux doubles accolades permettant de définir les variables). Les variables doivent faire référence à vos noms de champs dans la table des points de vue. Des classes CSS prédéfinies peuvent être mobilisées pour définir le style des éléments : title, field, value, desc, warn.
Ci-dessous un exemple de template :
<p class="title">{{ANALYSE.TITRE}}</p>
<div id="fields">
<div class="entry">
<span class='field'>Numéro :</span>
<span class='value'>{{NUM}}</span>
</div><div class="entry">
<span class='field'>Nom :</span>
<span class='value'>{{NOM}}</span>
</div><div class="entry">
<span class='field'>Thématique :</span>
<span class='value'>{{THEME}}</span>
</div><div class="entry">
<span class='field'>Département :</span>
<span class='value'>{{DPT}}</span>
</div><div class="entry">
<span class='field'>Secteur :</span>
<span class='value'>{{UP}} {{SECTEUR}}</span>
</div><div class="entry">
<span class='field'>Commune :</span>
<span class='value'>{{COMMUNE}}</span>
</div>
</div>
<div class='desc'>{{ANALYSE.ENJEUX}}</div>
<div class='warn'>{{AVERTISSEMENT}}</div>Le résultat obtenu permet d'illustrer les classes CSS disponibles :

Le template about.html peut être édité directement pour modifier le texte qui sera afficher dans le panneau à propos. Ce template n'utilise pas de variables.
Il est possible de personnaliser les fonds de carte disponibles en indiquant les services tuilé (XYZ, TMS ou WMTS sous certaines conditions) auxquels ont souhaite pouvoir accéder. Le dossier layers contient un fichier basemaps.json dédié à cette configuration. Il s'agit d'une liste dont chaque entrée définie les propriétés du service. L'exemple ci-dessous illustre la configuration d'un flux OpenStreetMap :
[
{
"key":"osm",
"name":"Open Street Map",
"url":"https://{s}.tile.osm.org/{z}/{x}/{y}.png",
"attribution":"<a href='https://www.openstreetmap.org/copyright'>OpenStreetMap</a> contributors"
}
]- key : l'identifiant du service qui sera utilisé dans les paramètres du thème
- name : le nom du service tel qu'il sera affiché dans le contrôle des couches
- url : l'adresse du service sous la forme d'un template indiquant la position des différentes variables (x, y et z les coordonnées de la tuile et s le numéro de serveur)
- attribution : le texte html indiquant les mentions de copyright
Par défaut la librairie Leaflet ne supporte pas les services WMTS et les grilles ou projections hétérogènes. C'est pourquoi les flux ici spécifiés doivent nécessairement être des services standard c'est à dire respectant la grille Google Web Mercator. Néanmoins, il est possible de se connecter à des flux WMTS à partir du moment où leur configuration est calée sur la grille standard. Dans ce cas il suffit d'écrire les paramètres KVP de l'url en dur. L'exemple ci-dessous illustre la configuration d'un flux WMTS de l'IGN :
{
"key":"ignOrtho",
"name":"Photos aériennes",
"url":"https://wxs.ign.fr/APIKEY/wmts?layer=ORTHOIMAGERY.ORTHOPHOTOS&style=normal&tilematrixset=PM&Service=WMTS&Request=GetTile&Version=1.0.0&Format=image/jpeg&TileMatrix={z}&TileCol={x}&TileRow={y}",
"attribution":"© <a href='http://www.ign.fr'>IGN</a>"
}Nota : dans l'url il faut remplacer la variable APIKEY par votre clé personnelle. La clé est écrite en clair, elle doit donc au préalable être protégée en l'associant soit à l'IP de votre serveur, soit à un nom de domaine particulier.
Il est possible de configurer l'affichage des couches géographiques supplémentaires. Néanmoins cela implique nécessairement d'écrire du code javascript personnalisé afin de définir comment l'information doit être stylisée.
La première étape est de convertir votre couche géographique en un fichier GeoJSON. La création du GeoJSON pour les données OPP était complexe car elle impliquait de combiner deux tables distinctes. Ici, dans la plupart des cas vous n'aurez pas cette difficulté, c'est pourquoi cette étape peut facilement être réalisée avec le logiciel QGIS. Il suffit de charger la couche dans le logiciel quelque soit son format initial (Shapefile, Geopackage, PostGIS...) puis de l'exporter en GeoJSON. Plusieurs paramètres doivent être considérés :
-
les coordonnées doivent être géographiques (longitude/latitude) et non projetées. Il faut donc choisir le système WGS84 (EPSG 4326)
-
pour diminuer la taille du fichier vous pouvez réduire le nombre de décimale des coordonnées à 4.
-
forcer l'encodage en UTF-8
-
n'exportez que les champs dont vous aurez l'utilité
Le fichier généré est probablement encore trop lourd pour un usage web, l'étape suivante consiste à simplifier la géométrie afin de réduire le nombre de points et obtenir une taille plus raisonnable. Cette étape peut être réalisée très facilement avec l'outil en ligne mapshaper.
Le fichier GeoJSON généré doit être ensuite déposé dans le sous dossier data. Choisissez un nom de fichier qui servira d'identifiant unique pour cette couche. Dans le sous dossier layers, créer un fichier du même nom avec l'extension *.js. C'est dans ce fichier que doit se trouver le code javascript permettant le chargement de la couche. Utilisez les fichiers existants comme modèle et référez vous à la documentation Leaflet. Exemple complet :
opp.bkgLayers['limits_cc'] = {
title : 'Zonage UNESCO',
enable : true,
maxZoom : 20,
load : function(data){
this.layer = L.geoJson(data, {
style: function (feature) {
switch (feature.properties.type) {
case 'Zone inscrite': return {color: "red", dashArray:"5, 10", opacity:0.5};
case 'Zone tampon': return {color: "black", dashArray:"5, 10", opacity:0.5};
}
}
});
this.legend = L.control({position: 'bottomright'});
this.legend.onAdd = function (map) {
var div = L.DomUtil.create('div', 'legend');
div.innerHTML += '<p><span class="icon" style="border:2px dashed black; background:transparent;"></span>Zone inscrite</p>';
div.innerHTML += '<p><span class="icon" style="border:2px dashed red; background:transparent;"></span>Zone tampon</p>';
return div;
};
this.info = L.control({position: 'topleft'});
this.info.onAdd = function (map) {
this._div = L.DomUtil.create('div', 'info');
return this._div;
};
this.info.update = function (props) {
if (props){
$('.info').css('display', 'inline-block')
this._div.innerHTML = props.zone;
} else {
this._div.innerHTML = '';
$('.info').css('display', 'none')
}
};
}
}le code doit implémenter un objet javascript qui sera ajouté comme nouvelle propriété de l'objet bkgLayers, en utilisant votre nom de fichier comme clé. L'objet doit contenir les propriétés suivante :
-
title : le titre de la couche tel qu'il doit apparaître dans le contrôle des couches
-
enable : indique si par défaut la couche doit être visible ou non
-
load : c'est la fonction principale qui se charge d'assigner des nouvelles propriétés à notre objet à partir des données GeoJSON. Trois nouvelles propriétés peuvent être définies :
-
layer (requis) : la couche Leaflet représentant notre GeoJSON
-
legend (optionnel) : un contrôle Leaflet contenant le code html à utiliser comme légende
-
info (optionnel) : un contrôle Leaflet permettant d'afficher un label dans l'angle supérieur gauche lorsque le pointeur survole une entité de la couche
-
Enfin, dans la configuration du thème, vous pouvez ajouter le nom de cette nouvelle couche dans la propriété layers, ce nom doit exactement correspondre au noms des fichiers GeoJSON et javascript correspondants.
Une fois l'application fonctionnelle en local, il suffit de déposer les fichier sur le serveur via FTP. Il est préférable de zipper les fichiers à transférer surtout s'il y a beaucoup de photos. Néanmoins cela implique d'avoir un accès ssh pour les dézipper.
Pour faciliter les mises à jour ultérieures du code deux alternatives au transfert FTP peuvent être envisagées :
-
déployer l'application sous la forme d'un clone git. C'est une approche très commode si vous maîtrisez le logiciel de versionnement git, cela vous permet de modifier la configuration de l'application à partir d'un fork et d'utiliser votre propre dépôt distant pour synchroniser le serveur.
-
l'utilitaire rsync est une autre solution très commode pour synchroniser un répertoire local avec un répertorie distant. Contrairement à git, rsync ne permet pas le versionnement des fichiers mais c'est une solution plus légère et facile. Le versionnement peut toujours être gérer en local avant synchronisation.
Dans tous les cas, le dossier de destination doit être servi par votre serveur http, le fichier d'index sera opp.html. Pour les photos, une mise en cache forte est préférable puisque les fichiers sont lourds et ne changent jamais.
Exemple de configuration Apache avec mise en cache de 3 ans pour les jpg.
<Directory /srv/www/opp>
DirectoryIndex opp.html
AllowOverride None
Require all granted
<IfModule mod_expires.c>
ExpiresActive on
ExpiresByType image/jpeg "access plus 3 years"
</IfModule>
</Directory>Identification du thème via un paramètre d'url :
Le nom du thème est normalement passer via un paramètre d'url, par exemple observatoire.causses-et-cevenne.fr/opp?theme=monTheme le code javascript côté client se charge ensuite de récupérer ce paramètre. Le cas échéant, le nom du thème sera rechercher dans la dernière partie de l'url, ainsi il est donc possible d'avoir des urls de la forme observatoire.causses-et-cevenne.fr/opp/monTheme ce qui est plus lisible lorsque l'on veut héberger plusieurs thèmes. Si la dernière partie de l'url ne correspond à aucun nom de thème alors c'est le thème par défaut qui sera appliqué. Pour que ce type d'url fonctionne il faut côté serveur que l'adresse soit traitée comme un alias renvoyant vers notre fichier index opp.html. Exemple de directive Apache avec le module mod_alias :
Alias /opp/montheme /srv/www/oppAttention la directive Alias ne peut pas être exécutée dans un fichier htaccess, mais il est possible d'écrire une directive équivalente avec le module rewrite :
RewriteEngine on
RewriteRule ^/opp/montheme(/.*)*$ /opp/$1 [L,QSA]Associer un nom de domaine à un thème particulier :
Dans le fichier de configuration des thèmes, il est possible de définir pour chacun le ou les noms de domaine auxquels ils seront associés. Si aucun paramètre de thème n'est passé dans l'url, alors le nom de domaine sera testé. Si aucune association n'est trouvée alors le thème par défaut sera renvoyé. Ainsi en synthèse, l'ordre de priorité pour la sélection du thème est le suivant :
-
paramètre passé dans l'url (query string ou url alias)
-
correspondance avec un nom de domaine spécifié dans la configuration du thème
-
thème par défaut
Pour configurer différents sous-domaines vers des thèmes spécifiques, il faut donc :
-
renseigner la propriété
domainsdans la configuration des thèmes -
faire pointer le sous domaine vers l'adresse IP du serveur (à faire dans l'interface de gestion de votre nom de domaine)
-
rediriger en interne les requêtes provenant du sous domaine vers le dossier hébergeant l'application
Ce dernier point peut-être réalisé en ajoutant une règle de réécriture au serveur Apache, soit dans le fichier de configuration général soit dans un fichier htaccess. Exemple pour faire pointer le sous-domaine test.causses-et-cevennes.fr vers le dossier /opp du serveur on peut ajouter les directives suivantes :
RewriteEngine on
RewriteCond %{HTTP_HOST} ^test\.causses-et-cevennes\.fr$
RewriteRule ^(.*)$ /opp/$1 [L,QSA]Lorsque que l'on déploie une mise à jour du code les modifications ne seront pas prises en compte si le navigateur charge des anciennes versions des fichiers ressources utilisés par la page web. La mise en cache concerne tous les types de ressources : images (jpg, png, svg), données (json, geojson), template (mst, html), script (js) ou feuilles de style (css). Pour forcer la mise à jour du cache on peut utiliser le raccourci ctrl+F5, mais cela implique pour l'utilisateur d'être informé de la mise à jour et de connaitre la procédure. Différentes solutions existent pour contourner ce problème, dans notre cas l'application utilise la technique du cache busting qui consiste à ajouter un numéro de version dans les paramètres des urls, ainsi le navigateur considère qu'il s'agit d'une nouvelle ressource car l'url a changé. Exemple : www.obs.fr/opp/themes.json?v=1 La présence du paramètre n'a aucun impact sur la capacité du navigateur à récupérer la ressource. Le fichier opp.js contient une variable version qu'il est possible d'incrémenter, la nouvelle version sera injectée dans toutes les urls. Il faudra également incrémenter les urls concernées dans les fichiers opp.html et opp.css, ces derniers ne contiennent pas de variable globale il faut donc utiliser la fonction rechercher et remplacer de votre éditeur de code. Le mécanisme de cache busting est à améliorer dans les prochaines versions.