This is part of a group effort from Twitter's 2019 Early Bird Program. We had 4 days to plan, design, and implement our feature on Twitter's web environment
Vision-based search is a popular feature that has been in demand, as shown with the rise to engines such as TinEye. Also noting that most search engines have also caught up with the technology such as Google - incorporating image search as an option. This proves that the demand for this feature will continue to rise.
- To implement this feature, photos on Twitter will have to carry unique identifiers in their metadata. These identifiers will be used to trace photos that are saved and reposted back to their original posters.
- Additionally, the lightbox functionality that “magnifies” a tweet’s photo when it is clicked will receive a new button in the bottom toolbar for directing users to a new timeline with other tweets that use the same photo.
- Overall, this feature’s implementation will add functionality to the lightbox for photos and include a modified implementation of the Twitter timelines
- Furthermore, pulling up image results for Google searches shows that many images have multiple versions of different sizes. In addition to tracking images via their ID, Vision Search will also use the Google Vision API to present all of these size versions together.
- The server will also utilize an image’s identifier to identify and provide the user with the name of the image’s original poster.
- When photos are saved off of Twitter, they will be encoded with the assigned ID. When another user goes on to repost this photo, the metadata ID will mark its tweet for being presented in a timeline of other tweets with the same photo.
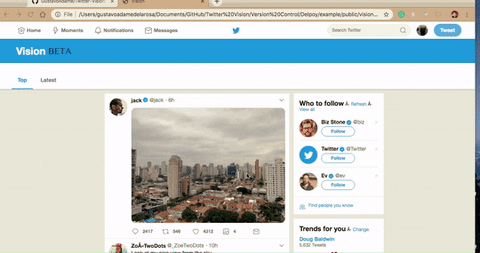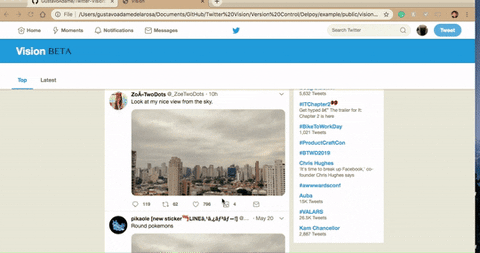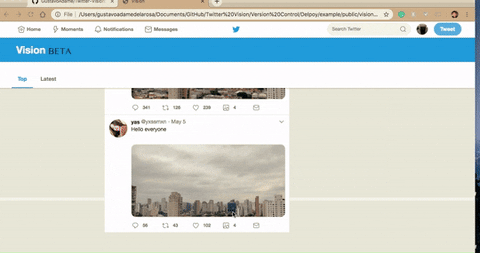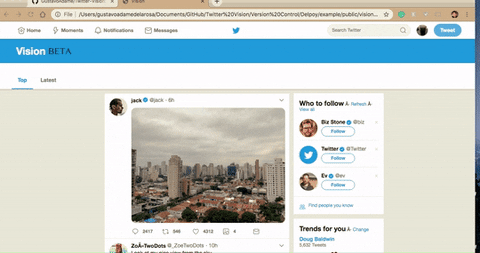
Note the additional button, that's our feature.
The number next to it is a counter - the number of posts with the same image
- Scenario: Say on user '@itsmegan' posts a tweet of a movie that she just watched with the movie's cover image attached to it. She then tweets that the movie was gross and advises others not to watch it. You were just considering watching it and would like to validate the claims. What do you do?
- Traditionally, you switch to another tab and open a movie review site such as Rotten Tomatoes and see what other people are saying. But aren't these OTHER PEOPLE also on Twitter? Why do all that? When you can...
- With Twitter Vision, can simply click on the image search icon and see what other people are saying about Avengers Endgame. Twitter could even take this further by incorporating aggregation tools that calculate average ratings and top comments.
- Disaster Management: Crowdfunding that has been a popular way of helping those in need after disasters is often subject to falsification by con-artists. With Twitter Vision, users are able to differentiate false accounts from real ones just by a simple search.
- Meme generation: A huge majority of young adults spend a lot of time on Twitter looking at memes as entertainment. Unfortunately, when meme threads get trendy, it becomes hard to follow up especially when there is no central hub. With Twitter Vision, users can follow one meme and see all other imaginable versions of it. This will significantly increase Twitter usage as well as make millions of young adults’ days a little brighter.
- Tourism: A picture of a tourist destination can be filled with biased tweets if viewed from one source. With Twitter Vision, users will be able to click on an image and see what every other person who posted the same destination is saying about the place. This makes judgment more informed.
- Fake news: The fight against fake news can easily be fought using vision search. Instances of misinformation and pseudo-news can be combated by allowing users to guide each other. Often, when a leading news source makes a claim about an event, it goes to the top of the news feed and if fake, can mislead many users. Nonetheless, with Twitter Vision, the users have the power to see what other users are saying about the same incidence.
- Movie reviews: Granted, there are tons of movie review sites out there - Twitter has the potential to disrupt this industry. User-generated feedback of movies can be aggregated in an image search platform which could be the future of peer review. With additional computational tools, this can be formalized into one of the most trusted movie review destinations for even non-Twitter users.
- Food and nutrition
Online campaigns for nutrition and well-being are on the rise with more people caring about what they eat than ever before. Nonetheless, not many social media sites have caught up with this. Twitter could potentially use image search to provide a wealth of information to users about the nutrition quality of such foods.
- For example, a user could click on an image of an apple and see what people are saying about its health quality. This could be a combination of word and image search. It would also open up the opportunity for health professionals to make this information more accessible.
- Inclusion Movements such as #WomenRightsAreHumanRights can be followed with much more ease and this makes gender education and information dissemination easier. Twitter will,of course, have to be careful on the negative effect taking effect by censoring and filtering. Otherwise, the feature will be invaluable in the fight for gender inclusion and promotion of diversity.
- Proposed Experiment
- We are trying to establish a cause-effect relationship between the introduction of the feature and the rate of usage. This calls for a Quasi-experiment Design.
- We also want to establish user satisfaction as increased usage could be a result of curiosity but satisfaction guarantees long term usage of the feature. This calls for a survey.
- We will also calculate statistical significance.
- Factors Considered
- Sample size, 30+: We surveyed over 30 respondents from different parts of the USA using Google Forms
- Stratified samples: We chose respondents from different social categories, i.e. people at gyms, hotel guests, people walking on the streets, online friends, Starbucks employees, etc.
- Crossover design: We introduced the feature to the users and got the post feature feedback from the same users.
- Randomized natural clusters: Despite being from different social groups, the choice of respondents was random
- Experimental Designs Used
- Quasi-experiment
- Survey design
- Statistical significance
-
Proof of growth of image use: In May, Twitter added a feature making it accessible to users to quote tweets using Images, GIFS, and photos. Because of this, users have more use of images on the Twitter platform. Tracking and being able to display images tweeted more than once to users to share information from the same image will be valuable.
-
Proof of feature demand: Tweets with images are 34% more likely to get retweeted than tweets with no images. Twitter images were used widely in the 2011 UK riots. Further research has been done and most of them advocate for a new approach to Twitter images for their basic function and meaning to have a greater impact on society. Another example of the 2011 Egyptian Revolution
-
The truth in the numbers: Using a pretendotype, we will do a Quasi-Experiment to evaluate the difference in user satisfaction that may be brought by the new feature.
The experiment will then entail a survey to establish the impact the feature would have on the users by evaluating the correlation between the introduction of the feature and the increase in user satisfaction.
We will then proceed to carry out tests of significance.
- Null hypothesis: The vision feature prototype will not show a possible increase in user satisfaction.
- NB: We called it possible increase because data collected from users is only a forecasted opinion and not a view of the implemented feature.
def difference_of_means_test(data1, data2, tails):
"""
Computes the difference of means test inputs as the datasets in comparison.
The function ouputs the p-value and the cohen's d value.
"""
n1 = len(data1)
n2 = len(data2)
x1 = np.mean(data1)
x2 = np.mean(data2)
s1 = np.std(data1, ddof = 1) #Bessel's correction: use n-1 in denominator
s2 = np.std(data2, ddof = 1)
SE = np.sqrt(s1**2/n1 + s2**2/n2)
Tscore = np.abs((x2 - x1))/SE
df = min(n1, n2) - 1 #conservative estimate
pvalue = tails*stats.t.cdf(-Tscore, df)
SDpooled = np.sqrt((s1**2*(n1-1))) + s2**2*(n2-1))/(n1+n2-2))
Cohensd = (x2 - x1)/SDpooled
print('t = ', Tscore)
print('p = ', pvalue)
print('d = ', Cohensd)
difference_of_means_test(prefeature, postfeature, 1)Results
t = 3.4763219074729492 | p = 0.0008111182847412143 | d = 0.8975824569132489
#p value is less than 0.001 hence is statistically significant
Cohensd = 0.8975824569132489
Hedgesg = Cohensd*(1-(3/(4*(len(prefeature)+len(postfeature)-9))))
print(Hedgesg)Result
0.8843827148998188
# this is a large effect size, i.e. >0.8 thus also practically significant - The p-value is less than the alpha value which means that we reject the null hypothesis.
- This shows that the difference in user satisfaction between pre and post feature introduction is statistically significant.
- Hedges G value is 0.88438 and therefore greater than the standard 0.8 which means that there is a large effect size. This means that the difference is also practically significant.
- Additional Experiment
- We will look at statistics at the images saved off of Twitter, both images, videos, and GIFS.
- Observe if these images were saved off of Twitter are being reposted or used in any way on the app.
- We can start testing this feature with users who regularly post images, i.e. those with a large number of photos on their accounts. From here, we could categorize the images into images saved from Twitter and those that were not.
- As for the Twitter Vision functionality, we could test the Vision Search with photos that were saved and reposted without alterations; photos that were saved, cropped, and reposted; and photos that are the same, cropped or uncropped, but not saved from Twitter before being reposted.
- Implementation will be deemed successful if all of these stages successfully group together all tweets with the same image.
- Some issues for development include the fact that, in the case of memes, one picture can have different caption-text boxes. How will we handle this?
- Additionally, if a photo has already been posted but not previously saved from Twitter, should we use Google Vision to give it the ID of a version that was posted earlier or generate a new one?
- César Castro - Played a key role in the development of this feature - emanuel@minerva.kgi.edu
- Jack Nyange - Lead the statistical analysis - jacknyange@minerva.kgi.edu
- Megan St. Hilaire - Help build the front-end of this feature - mfsthilaire13@gmail.com
- Yasmin Hernandez Calderon - Lead the design and implementation of this feature - yherna29@ucsc.edu
- Gustavo Adame Delarosa (Me 😄) - Organized and implemented the design feature - gua222@lehigh.edu
Special thanks to our mentor, Andrew McCree (amccree@twitter.com)
And of course, Twitter for having us for this opportunity as we continue to learn more about development and solve the problems around us.
This is all front-end, so the Google Vision API wasn't actually implemented. It was a concept idea presented to Twitter engineers and staff as part of this program.