-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
1946e55
commit 1405407
Showing
7 changed files
with
577 additions
and
13 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,17 +1,128 @@ | ||
| # 7-32 说反话-加强版 | ||
|
|
||
| 给定一句英语,要求你编写程序,将句中所有单词的顺序颠倒输出。 | ||
|
|
||
| ## 输入格式 | ||
|
|
||
| 测试输入包含一个测试用例,在一行内给出总长度不超过500 000的字符串。字符串由若干单词和若干空格组成,其中单词是由英文字母(大小写有区分)组成的字符串,单词之间用若干个空格分开。 | ||
|
|
||
| ## 输出格式 | ||
|
|
||
| 每个测试用例的输出占一行,输出倒序后的句子,并且保证单词间只有1个空格。 | ||
|
|
||
| ## 输入样例 | ||
|
|
||
| ```c | ||
| Hello World Here I Come | ||
| ``` | ||
|
|
||
| ## 输出样例 | ||
|
|
||
| ```c | ||
| Come I Here World Hello | ||
| ``` | ||
|
|
||
| ## 分析与答案 | ||
|
|
||
| 题目给出了总长度,可以采用大数组的形式,但下面的程序依然使用链表的形式处理,为了方便指针的来回移动,这一道题建立的是双向链表,每个节点包含一个字符,一个指向前一节点的指针和一个指向下一节点的指针。 | ||
|
|
||
| 输入的处理和之前统计字符串单词长度的处理类似,但由于这一道题要求的是单词倒序输出而不是字母倒序输出,输出采取的是以下循环方式(输出前已完成链表处理,单词之间只有一个空格,结尾没有空格): | ||
|
|
||
| 1. 如果已经到达头节点,退出循环; | ||
| 2. 如果没有到达头节点,则指向单词结尾的`q`指针先移动到指向单词开头的`p`指针的位置(在最开始,`p`指针位于链表末尾); | ||
| 3. 移动`p`指针,直到`p`指针中指向前一节点的指针为空(已经到头节点)或者前一节点储存的是空格,此时`p`指针已经在单词的开头; | ||
| 4. 把链表自己的指针拉到`p`的位置,`p`指针开始输出并移动,直到`q`的位置; | ||
| 5. 把`p`指针拉回到单词开头,如果此时还没有到链表头节点,就把储存的前一节点(必定是空格)输出,并移动到空格之前的节点,进入下一个循环。 | ||
|
|
||
| 如果只有一个字母,意味着上面的循环一开始就在头节点,会直接退出循环。这种情况可以单独处理,直接输出头结点的字母(测试点中,如果只有空格,输出空格是符合要求的)。 | ||
|
|
||
| ```c | ||
| #include <stdio.h> | ||
| #include <stdlib.h> | ||
|
|
||
| //定义链表节点 | ||
| typedef struct list{ | ||
| struct list * pre; | ||
| char letter; | ||
| struct list * next; | ||
| } str; | ||
|
|
||
| int main(){ | ||
| str * char_list = (str*)malloc(sizeof(str)); | ||
| //头节点完全初始化,只对头节点这样做 | ||
| char_list->pre = NULL; | ||
| char_list->letter = EOF; | ||
| char_list->next = NULL; | ||
| char c=getchar(); | ||
| while(c!='\n'){ | ||
| //遇到换行符结束 | ||
| if(c!=' '){ | ||
| //非空格非换行符,为字母,塞入节点 | ||
| if(char_list->letter==EOF){ | ||
| //头节点,只塞入字符 | ||
| char_list->letter = c; | ||
| } | ||
| else{ | ||
| //非头节点,创建新节点塞入 | ||
| char_list->next = (str*)malloc(sizeof(str)); | ||
| char_list->next->pre = char_list; | ||
| char_list = char_list->next; | ||
| char_list->letter = c; | ||
| } | ||
| } | ||
| else{ | ||
| if(char_list->letter!=' '&& char_list->pre!=NULL){ | ||
| //现节点不是空格,也不是第一个节点,创建新节点插入一个空格 | ||
| //如果先节点是空格,或者是第一个节点,那就什么都不做 | ||
| char_list->next = (str*)malloc(sizeof(str)); | ||
| char_list->next->pre = char_list; | ||
| char_list = char_list->next; | ||
| char_list->letter = c; | ||
| } | ||
| } | ||
| //读取下一个字符 | ||
| c= getchar(); | ||
| } | ||
| //如果结尾有空格,删掉最后一个节点 | ||
| if(char_list->letter==' '){ | ||
| str *tmp = char_list; | ||
| char_list = char_list->pre; | ||
| free(tmp); | ||
| } | ||
| //最后一个字母的next指针置空 | ||
| char_list->next = NULL; | ||
| str *p = char_list,*q; | ||
| while(1){ | ||
| if(p->pre==NULL) | ||
| //已经到头节点,结束循环 | ||
| break; | ||
| //q指针拉上来 | ||
| q = p; | ||
| while(p->pre!=NULL && p->pre->letter!=' ') | ||
| //到头节点或者到空格前停下 | ||
| p = p->pre; | ||
| //char_list指针拉上来 | ||
| char_list = p; | ||
| while(p != q){ | ||
| printf("%c",p->letter); | ||
| p = p->next; | ||
| } | ||
| //打完最后一个字母 | ||
| printf("%c",p->letter); | ||
| //p指针拉上来 | ||
| p = char_list; | ||
| if(p->pre!=NULL){ | ||
| //p还没到头节点,打空格 | ||
| p = p->pre; | ||
| printf("%c",p->letter); | ||
| p = p->pre; | ||
| } | ||
| } | ||
| //如果只有一个字母 | ||
| if(p->next==NULL&&p->letter!=EOF) | ||
| printf("%c",p->letter); | ||
| return 0; | ||
| } | ||
| ``` | ||
|
|
||
| ## 分析与答案 | ||
| 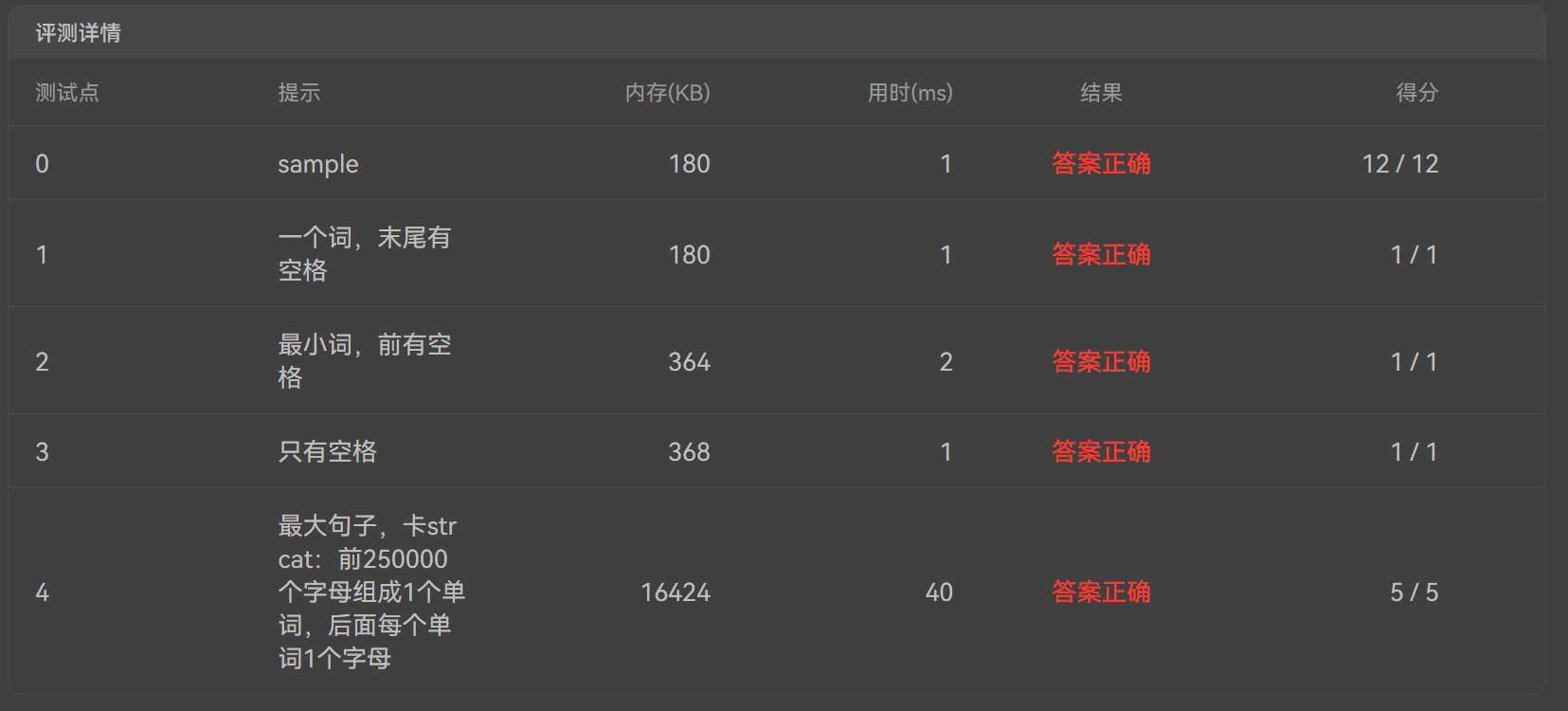 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,17 +1,75 @@ | ||
| # 7-33 有理数加法 | ||
|
|
||
| 本题要求编写程序,计算两个有理数的和。 | ||
|
|
||
| ## 输入格式 | ||
|
|
||
| 输入在一行中按照`a1/b1 a2/b2`的格式给出两个分数形式的有理数,其中分子和分母全是整形范围内的正整数。 | ||
|
|
||
| ## 输出格式 | ||
|
|
||
| ## 输入样例 | ||
| 在一行中按照`a/b`的格式输出两个有理数的和。注意必须是该有理数的最简分数形式,若分母为1,则只输出分子。 | ||
|
|
||
| ## 输入样例1 | ||
|
|
||
| ```c | ||
| 1/3 1/6 | ||
| ``` | ||
|
|
||
| ## 输出样例 | ||
| ## 输出样例1 | ||
|
|
||
| ```c | ||
| 1/2 | ||
| ``` | ||
|
|
||
| ## 输入样例2 | ||
|
|
||
| ```c | ||
| 4/3 2/3 | ||
| ``` | ||
|
|
||
| ## 输出样例2 | ||
|
|
||
| ```c | ||
| 2 | ||
| ``` | ||
|
|
||
| ## 分析与答案 | ||
|
|
||
| 其实是考数学,`a1/b1+a2/b2=(a1b2+a2b1)/(b1b2)`,然后对结果进行约分输出。 | ||
|
|
||
| ```c | ||
| #include <stdio.h> | ||
|
|
||
| /* | ||
| a1/b1+a2/b2=(a1b2+a2b1)/(b1b2),然后进行约分 | ||
| */ | ||
| void sim(int up, int down); | ||
| int main(){ | ||
| int a1,b1,a2,b2; | ||
| scanf("%d/%d %d/%d",&a1,&b1,&a2,&b2); | ||
| int up,down; | ||
| up = a1*b2 + a2*b1; | ||
| down = b1*b2; | ||
| sim(up,down); | ||
| return 0; | ||
| } | ||
| sim(int up,int down){ | ||
| if(up%down == 0){ | ||
| printf("%d",up/down); | ||
| } | ||
| else{ | ||
| int i = down; | ||
| while(i!=1){ | ||
| if(up%i == 0 && down%i == 0){ | ||
| up /= i; | ||
| down /=i; | ||
| } | ||
| i--; | ||
| } | ||
| printf("%d/%d",up,down); | ||
| } | ||
| } | ||
| ``` | ||
| ## 分析与答案 | ||
| 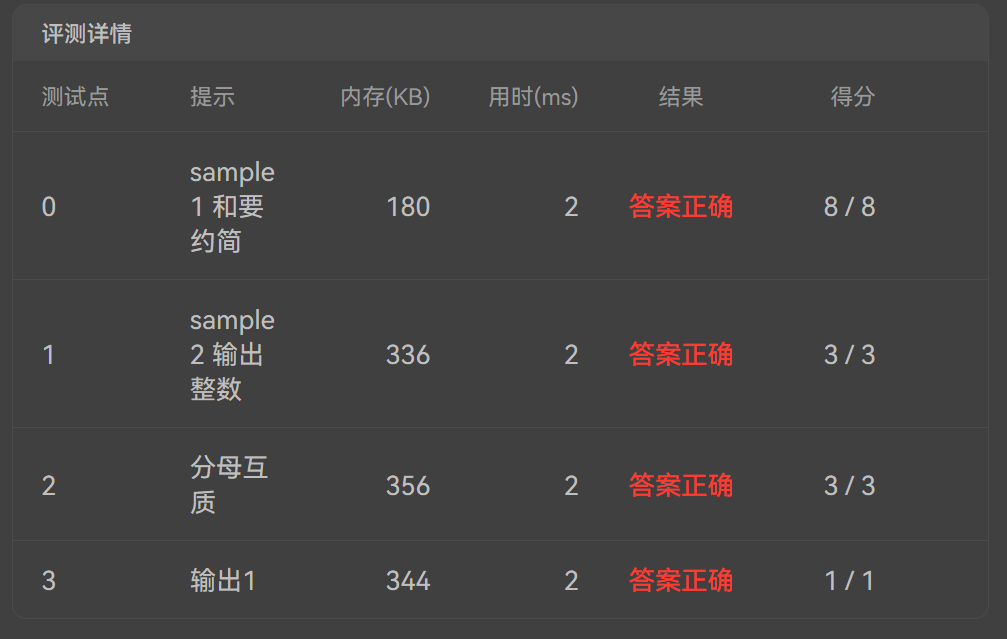 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,17 +1,79 @@ | ||
| # 7-34 通讯录的录入与显示 | ||
|
|
||
| 通讯录中的一条记录包含下述基本信息:朋友的姓名、出生日期、性别、固定电话号码、移动电话号码。 | ||
| 本题要求编写程序,录入$N$条记录,并且根据要求显示任意某条记录。 | ||
|
|
||
| ## 输入格式 | ||
|
|
||
| 输入在第一行给出正整数$N$(≤10);随后$N$行,每行按照格式`姓名 生日 性别 固话 手机`给出一条记录。其中`姓名`是不超过10个字符、不包含空格的非空字符串;生日按`yyyy/mm/dd`的格式给出年月日;性别用`M`表示“男”、`F`表示“女”;`固话`和`手机`均为不超过15位的连续数字,前面有可能出现`+`。 | ||
|
|
||
| 在通讯录记录输入完成后,最后一行给出正整数$K$,并且随后给出$K$个整数,表示要查询的记录编号(从0到$N$−1顺序编号)。数字间以空格分隔。 | ||
|
|
||
| ## 输出格式 | ||
|
|
||
| 对每一条要查询的记录编号,在一行中按照`姓名 固话 手机 性别 生日`的格式输出该记录。若要查询的记录不存在,则输出`Not Found`。 | ||
|
|
||
| ## 输入样例 | ||
|
|
||
| ```c | ||
| 3 | ||
| Chris 1984/03/10 F +86181779452 13707010007 | ||
| LaoLao 1967/11/30 F 057187951100 +8618618623333 | ||
| QiaoLin 1980/01/01 M 84172333 10086 | ||
| 2 1 7 | ||
| ``` | ||
|
|
||
| ## 输出样例 | ||
|
|
||
| ```c | ||
| LaoLao 057187951100 +8618618623333 F 1967/11/30 | ||
| Not Found | ||
| ``` | ||
|
|
||
| ## 分析与答案 | ||
|
|
||
| 用一个动态分配内存的结构体数组来储存通讯录记录,每一项都作为字符串(或字符,性别只有一个字母)来处理。注意输入和输出的次序是不一样的。 | ||
|
|
||
| ```c | ||
| #include <stdio.h> | ||
| #include <stdlib.h> | ||
| #include <string.h> | ||
|
|
||
| typedef struct{ | ||
| char name[11]; | ||
| char birth[11]; | ||
| char sex; | ||
| char tele[17]; | ||
| char mobile[17]; | ||
| }contact; | ||
|
|
||
| int main(){ | ||
| int n,i = 0; | ||
| scanf("%d",&n); | ||
| contact * list = (contact*)malloc(n*sizeof(contact)); | ||
| for(;i<n;i++){ | ||
| scanf("%s %s %c %s %s",(list+i)->name,(list+i)->birth,&(list+i)->sex,(list+i)->tele,(list+i)->mobile); | ||
| } | ||
| int num; | ||
| int * lookup; | ||
| scanf("%d",&num); | ||
| lookup = (int*)malloc(num*sizeof(int)); | ||
| for(i=0;i<num;i++){ | ||
| scanf("%d",lookup+i); | ||
| } | ||
| for(i=0;i<num;i++){ | ||
| if(*(lookup+i)>=n||*(lookup+i)<0){ | ||
| printf("Not Found"); | ||
| } | ||
| else{ | ||
| printf("%s %s %s %c %s",(list+*(lookup+i))->name,(list+*(lookup+i))->tele,(list+*(lookup+i))->mobile,(list+*(lookup+i))->sex, | ||
| (list+*(lookup+i))->birth); | ||
| } | ||
| if(i!=num-1) | ||
| printf("\n"); | ||
| } | ||
| return 0; | ||
| } | ||
| ``` | ||
|
|
||
| ## 分析与答案 | ||
| 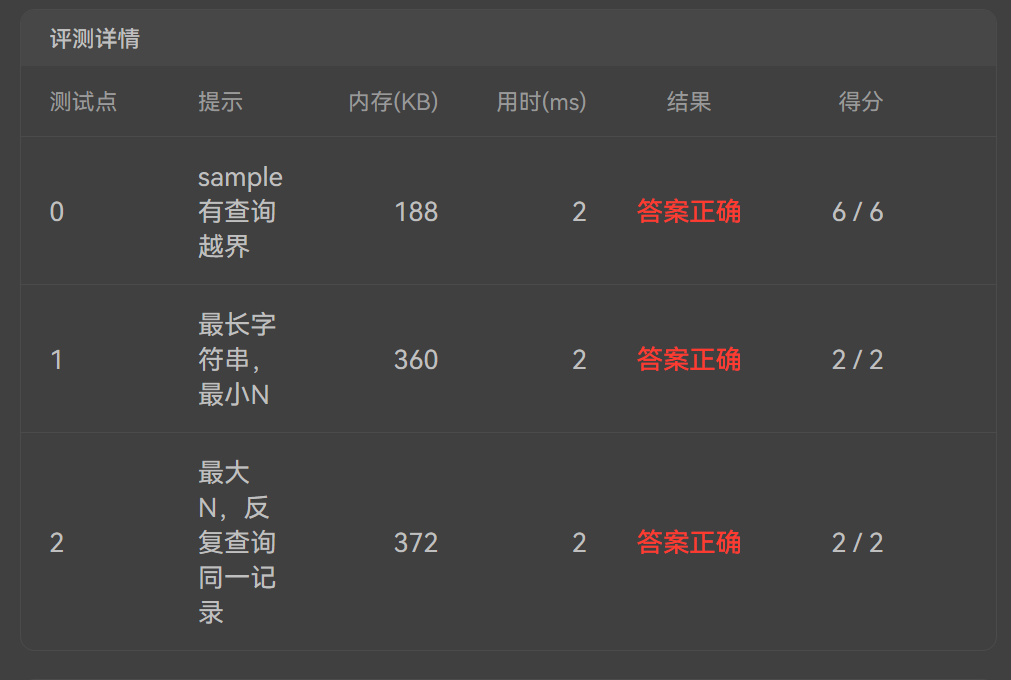 |
Oops, something went wrong.