
A curated list of awesome open-source tools, resources, and tutorials for MLSecOps (Machine Learning Security Operations).

- Open Source Security Tools
- Commercial Tools
- DATA
- ML Code Security
- 101 Resources
- Attack Vectors
- Blogs and Publications
- MLOps Infrastructure Vulnerabilities
- Community Resources
- Infographics
- Contributions
- Contributors
In this section, you and I can take a look at what opensource solutions and PoCs, exist to accomplish the task of ML protection. Of course, some of them are unsupported or will have difficulties to run. However, not mentioning them is a big crime.
| Tool | Description |
|---|---|
| ModelScan | Protection Against ML Model Serialization Attacks |
| NB Defense | Secure Jupyter Notebooks |
| Garak | LLM vulnerability scanner |
| Adversarial Robustness Toolbox | Library of defense methods for ML models against adversarial attacks |
| MLSploit | Cloud framework for interactive experimentation with adversarial machine learning research |
| TensorFlow Privacy | Library of privacy-preserving machine learning algorithms and tools |
| Foolbox | Python toolbox for creating and evaluating adversarial attacks and defenses |
| Advertorch | Python toolbox for adversarial robustness research |
| Artificial Intelligence Threat Matrix | Framework for identifying and mitigating threats to machine learning systems |
| Adversarial ML Threat Matrix | Adversarial Threat Landscape for AI Systems |
| CleverHans | A library of adversarial examples and defenses for machine learning models |
| AdvBox | Advbox is a toolbox to generate adversarial examples that fool neural networks in PaddlePaddle、PyTorch、Caffe2、MxNet、Keras、TensorFlow |
| Audit AI | Bias Testing for Generalized Machine Learning Applications |
| Deep Pwning | Deep-pwning is a lightweight framework for experimenting with machine learning models with the goal of evaluating their robustness against a motivated adversary |
| Privacy Meter | An open-source library to audit data privacy in statistical and machine learning algorithms |
| TensorFlow Model Analysis | A library for analyzing, validating, and monitoring machine learning models in production |
| PromptInject | A framework that assembles adversarial prompts |
| TextAttack | TextAttack is a Python framework for adversarial attacks, data augmentation, and model training in NLP |
| OpenAttack | An Open-Source Package for Textual Adversarial Attack |
| TextFooler | A Model for Natural Language Attack on Text Classification and Inference |
| Flawed Machine Learning Security | Practical examples of "Flawed Machine Learning Security" together with ML Security best practice across the end to end stages of the machine learning model lifecycle from training, to packaging, to deployment |
| Adversarial Machine Learning CTF | This repository is a CTF challenge, showing a security flaw in most (all?) common artificial neural networks. They are vulnerable for adversarial images |
| Damn Vulnerable LLM Project | A Large Language Model designed for getting hacked |
| Gandalf Lakera | Prompt Injection CTF playground |
| Vigil | LLM prompt injection and security scanner |
| PALLMs (Payloads for Attacking Large Language Models) | list of various payloads for attacking LLMs collected in one place |
| AI-exploits | exploits for MlOps systems. It's not just in the inputs given to LLMs such as ChatGPT |
| Offensive ML Playbook | Offensive ML Playbook. Notes on machine learning attacks and pentesting |
| AnonLLM | Anonymize Personally Identifiable Information (PII) for Large Language Model APIs |
| AI Goat | vulnerable LLM CTF challenges |
| Pyrit | The Python Risk Identification Tool for generative AI |
| Raze to the Ground: Query-Efficient Adversarial HTML Attacks on Machine-Learning Phishing Webpage Detectors | Source code of the paper "Raze to the Ground: Query-Efficient Adversarial HTML Attacks on Machine-Learning Phishing Webpage Detectors" accepted at AISec '23 |
| Giskard | Open-source testing tool for LLM applications |
| Safetensors | Convert pickle to a safe serialization option |
| Citadel Lens | Quality testing of models according to industry standards |
| Model-Inversion-Attack-ToolBox | A framework for implementing Model Inversion attacks |
| NeMo-Guardials | NeMo Guardrails allow developers building LLM-based applications to easily add programmable guardrails between the application code and the LLM |
| AugLy | A tool for generating adversarial attacks |
| Knockoffnets | PoC to implement BlackBox attacks to steal model data |
| Robust Intelligence Continous Validation | Tool for continuous model validation for compliance with standards |
| VGER | Jupyter Attack framework |
| AIShield Watchtower | An open source tool from AIShield for studying AI models and scanning for vulnerabilities |
| PS-fuzz | tool for scanning LLM vulnerabilities |
| Mindgard-cli | Check security of you AI via CLI |
| PurpleLLama3 | Check LLM security with Meta LLM Benchmark |
| Model transparency | generate model signing |
| ARTkit | Automated prompt-based testing and evaluation of Gen AI applications |
| LangBiTe | A Bias Tester framework for LLMs |
| OpenDP | The core library of differential privacy algorithms powering the OpenDP Project |
| TF-encrypted | Encryption for tensorflow |
| Tool | Description |
|---|---|
| Databricks Platform, Azure Databricks | Datalake data management and implementation tool |
| Hidden Layer AI Detection Response | Tool for detecting and responding to incidents |
| Guardian | Model protection in CI/CD |
| Tool | Description |
|---|---|
| ARX - Data Anonymization Tool | Tool for anonymizing datasets |
| Data-Veil | Data masking and anonymization tool |
| Tool for IMG anonymization | Image anonymization |
| Tool for DATA anonymization | Data anonymization |
| BMW-Anonymization-Api | This repository allows you to anonymize sensitive information in images/videos. The solution is fully compatible with the DL-based training/inference solutions that we already published/will publish for Object Detection and Semantic Segmentation |
| DeepPrivacy2 | A Toolbox for Realistic Image Anonymization |
| PPAP | Latent-space-level Image Anonymization with Adversarial Protector Networks |
- lintML - Security linter for ML, by Nvidia
- HiddenLayer: Model as Code - Research about some vectors in ML libraries
- Copycat CNN - Proof-of-concept on how to generate a copy of a Convolutional Neural Network
- differential-privacy-library - Library designed for differential privacy and machine learning
You can find here a list of resources to help you get into the topic of AI security. Understand what attacks exist and how they can be used by an attacker.
- AI Security 101
- Web LLM attacks
- Microsoft AI Red Team
- AI Risk Assessment for ML Engineers
- Microsoft - Generative AI Security for beginners
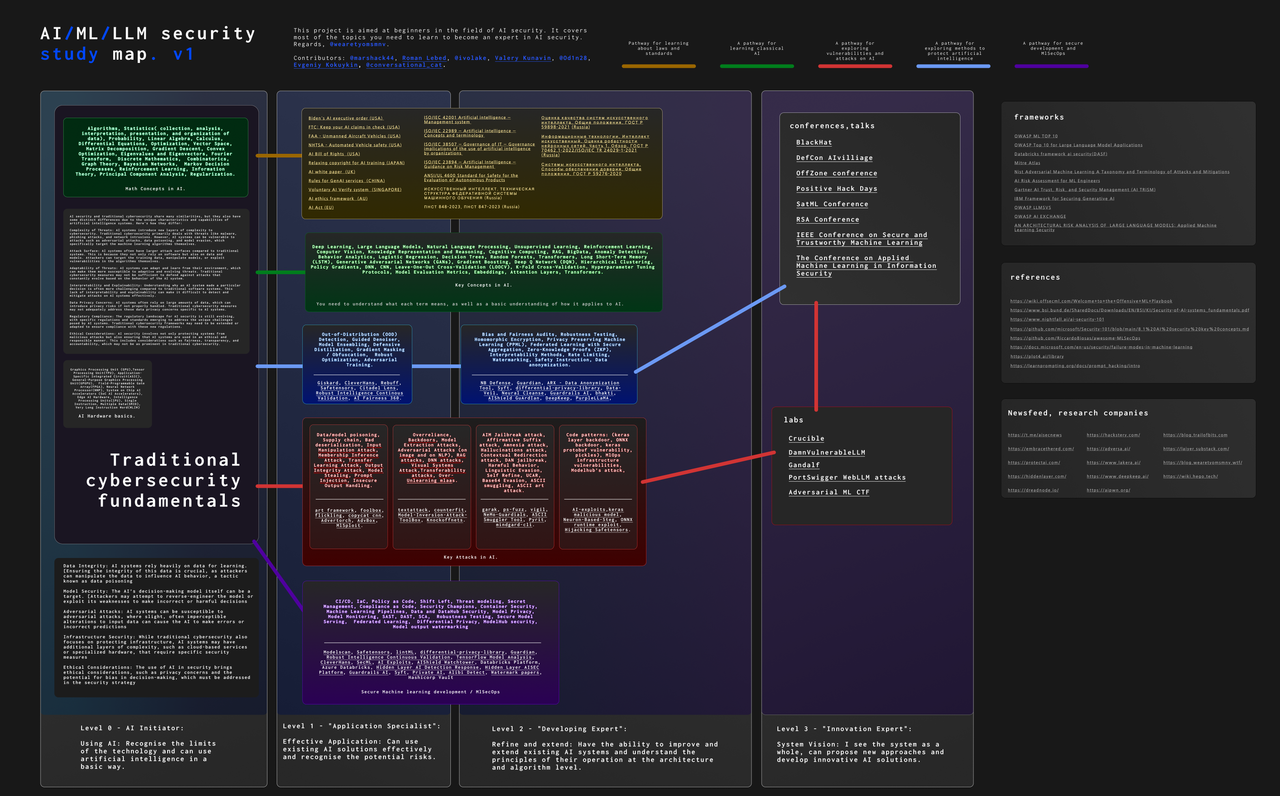
Full size map in this repository





more in Adversarial AI Attacks, Mitigations, and Defense Strategies: A cybersecurity professional's guide to AI attacks, threat modeling, and securing AI with MLSecOps
- Data Poisoning
- Adversarial Prompt Exploits
- Model Inversion Attacks
- Model Evasion Attacks
- Membership Inference Exploits
- Model Stealing Attacks
- ML Supply Chain Attacks
- Model Denial Of Service
- Gradient Leakage Attacks
- Cloud Infrastructure Attacks
- Architecture and Access-control attacks
🌱 The AI security community is growing. New blogs and many researchers are emerging. In this paragraph you can see examples of some blogs.
- 📚 What is MLSecOps
- 🛡️ Red-Teaming Large Language Models
- 🔍 Google's AI red-team
- 🔒 The MLSecOps Top 10 vulnerabilities
- 🏴☠️ Token Smuggling Jailbreak via Adversarial Prompt
- ☣️ Just How Toxic is Data Poisoning? A Unified Benchmark for Backdoor and Data Poisoning Attacks
- 📊 We need a new way to measure AI security
- 🕵️ PrivacyRaven: Implementing a proof of concept for model inversion
- 🧠 Adversarial Prompts Engineering
- 🔫 TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP
- 📋 Trail Of Bits' audit of Hugging Face's safetensors library
- 🔝 OWASP Top 10 for Large Language Model Applications
- 🔐 LLM Security
- 🔑 Is you MLOps infrastructure leaking secrets?
- 🚩 Embrace The Red, blog where show how u can hack LLM's.
- 🎙️ Audio-jacking: Using generative AI to distort live audio transactions
- 🌐 HADESS - Web LLM Attacks
- 🧰 WTF-blog - MlSecOps frameworks ... Which ones are available and what is the difference?
- 📚 DreadNode Paper Stack
Very interesting articles on MlOps infrastructure vulnerabilities. In some of them you can even find ready-made exploits.
- SILENT SABOTAGE - Study on bot compromise for converting Pickle to SafeTensors
- NOT SO CLEAR: HOW MLOPS SOLUTIONS CAN MUDDY THE WATERS OF YOUR SUPPLY CHAIN - Study on vulnerabilities for the ClearML platform
- Uncovering Azure's Silent Threats: A Journey into Cloud Vulnerabilities - Study on security issues of Azure MLAAS
- The MLOps Security Landscape
- Confused Learning: Supply Chain Attacks through Machine Learning Models

Official implementation of "AgentPoison: Red-teaming LLM Agents via Memory or Knowledge Base Backdoor Poisoning". This project explores methods of data poisoning and backdoor insertion in LLM agents to assess their resilience against such attacks.
Research on methods of embedding malicious payloads into deep neural networks.
Investigation of backdoor attacks on deep learning models, focusing on creating undetectable vulnerabilities within models.
Techniques for stealing deep learning models through various attack vectors, enabling adversaries to replicate or access models.
Model extraction without using data, allowing for the recovery of models without access to the original data.
Tool for mapping and analyzing large language models (LLMs), exploring the structure and behavior of various LLMs.
Federated learning pipeline using Google Cloud infrastructure, enabling model training on distributed data.
Attack using ensemble class activation maps to introduce errors in models by manipulating activation maps.
Methods for attacking deep models under various conditions and constraints, focusing on creating more resilient attacks.
Research on adaptive attacks on machine learning models, enabling the creation of attacks that can adapt to model defenses.
Knowledge transfer in zero-shot scenarios, exploring methods to transfer knowledge between models without prior training on target data.
Attack for generating informative labels, aimed at covertly extracting data from trained models.
Enhancing DMI (Data Mining and Integration) methods using additional knowledge to improve accuracy and efficiency.
Research on methods for visualizing and interpreting machine learning models, providing insights into model workings.
Attacks that can be "plugged and played" without needing model modifications, offering flexible and universal attack methods.
Tool for analyzing and processing snapshot data, enabling efficient handling of data snapshots.
Research on the trade-offs between privacy and robustness in models, aiming to balance these two aspects in machine learning.
Methods for data leakage from trained models, exploring ways to extract private information from machine learning models.
Research on blind information extraction attacks, enabling data retrieval without access to the model's internal structure.
Differential privacy methods for deep learning, ensuring data privacy during model training.
Defense methods using MMD-mixup, aimed at improving model robustness against attacks.
Tools for protecting memory from attacks, exploring ways to prevent data leaks from model memory.
Methods for merging and splitting data to improve training, optimizing the use of heterogeneous data in models.
Attacks on face recognition models using attributes, exploring ways to manipulate facial attributes to induce errors.
Attacks on face verification models, aimed at disrupting authentication systems based on face recognition.
Using GANs to create malware, exploring methods for generating malicious code with generative models.
Methods for generating adversarial perturbations using generative models, aimed at introducing errors in deep models.
Adversarial attacks using Relativistic AdvGAN, exploring methods for creating more realistic and effective attacks.
Attacks on large language models, exploring vulnerabilities and protection methods for LLMs.
Safe fine-tuning of large language models, aiming to prevent data leaks and ensure security during LLM tuning.
Methods for evaluating trust in models, exploring ways to determine the reliability and safety of machine learning models.
Benchmark for evaluating prompts, providing tools for testing and optimizing queries to large language models.
Tool for analyzing and evaluating models based on ROM codes, exploring various aspects of model performance and resilience.
Research on privacy in large language models, aiming to protect data and prevent leaks from LLMs.
- MLSecOps
- MLSecOps Podcast
- MITRE ATLAS™ and SLACK COMMUNITY
- MlSecOps communtiy and SLACK COMMUNITY
- MITRE ATLAS™ (Adversarial Threat Landscape for Artificial-Intelligence Systems)
- OWASP AI Exchange
- OWASP Machine Learning Security Top Ten
- OWASP Top 10 for Large Language Model Applications
- OWASP LLMSVS
- OWASP Periodic Table of AI Security
- OWASP SLACK
- Awesome LLM Security
- Hackstery
- PWNAI
- AiSec_X_Feed
- HUNTR Discord community
- AIRSK
- AI Vulnerability Database
- Incident AI Database
- Defcon AI Village CTF
- Awesome AI Security
- MLSecOps Reference Repository
- Awesome LVLM Attack
- Awesome MLLM Safety
- Adversarial AI Attacks, Mitigations, and Defense Strategies: A cybersecurity professional's guide to AI attacks, threat modeling, and securing AI with MLSecOps
- Privacy-Preserving Machine Learning
- Generative AI Security: Theories and Practices (Future of Business and Finance)


All contributions to this list are welcome! Please feel free to submit a pull request with any additions or improvements.
 @riccardobiosas |
 @badarahmed |
 @deadbits |
 @wearetyomsmnv |
 @anmorgan24 |
 @mik0w |
 @alexcombessie |








If you find this project useful, please consider giving it a star ⭐️

This project is licensed under the MIT License - see the LICENSE file for details.
Made with ❤️