Desde que inicié este lindo recorrido llamado Ciencia de datos, me he dado cuenta de que las personas tienen las mismas dudas. Ya sea cuando apenas están arrancando con esta disciplina o incluso si llevan algún tiempo. Lo que intento con esto es resumir algunas de las respuestas a preguntas frecuentes. Aquí también podrás encontrar recursos para cada una de ellas.
Mi recomendación es usar esto como una guía de estudio y un checklist de skills por desarrollar.
Si este repositorio es de valor para tí, no olvides darle fork y estrellita.
Sin más retraso, acá hay algunas de las preguntas más frecuentes entre las personas que están estudiando Data Science y Machine Learning.
- ¿Qué habilidades concretas necesito para arrancar con Data Science?
- ¿Qué lenguajes de programación necesito para data science?
- ¿Qué necesito saber de SQL?
- ¿Qué es machine learning?
- ¿Y qué hay con deep learning e inteligencia artificial?
- ¿Qué matemáticas necesito?
- ¿Qué quiere decir conocimientos de negocio?
- ¿Qué hay que saber sobre visualización de datos?
- ¿Jupyter Notebooks o Google Colab?
- ¿Qué debería de saber sobre ingenieria de software/web?
- ¿Cuánto tiempo puedo tardar para adquirir las habilidades para data science?
- ¿Qué hay sobre la parte legal y ética?
- ¿Cuáles son las oportunidades laborales?
La ciencia de datos son básicamente tres cosas:
- Ciencias de la Computación: Programación, para ser más específicos.
- Matemáticas: Estadística mayormente, álgebra lineal y cálculo.
- Conocimiento de negocio: Con esta le darás contexto a tus análisis.
Para ser un científico de datos hay que desarrollar estas tres áreas. También hay que tener en cuenta que Data Science tiene varias subramas:
- Análisis de Datos y Business Intelligence: que se encarga de tomar los datos recogidos para análisis respecto a una necesidad de negocio y ayudar a los líderes a tomar decisiones basadas en datos.
- Ingeniería y Arquitectura de Datos: que se encarga del proceso de ETL (extraer, transformar y cargar). Es decir, tomar datos de diferentes fuentes (bases de datos, web scraping, APIs, etc), limpiar los datos y entregarlos en un sitio donde los científicos de datos podrán disponer de ellos (data warehouses, bases de datos, cloud, etc.).
- Científico de datos: que se encarga de tareas similares al analista de datos, aunado a utilizar la data disponible para entrenar modelos predictivos.
- Ingenieros de Machine Learning, Deep Learning e Inteligencia Artificial: que se encargan no solo de entrenar modelos con la data disponible, sino también desplegarlos, mantenerlos actualizados, monitorearlos y generar pipelines para orquestar todos estos procesos automáticamente.
Para cada una de estas subramas, las habilidades específicas que necesitas son las siguientes:

Fig 1. Data Science Skills
Python y/o R, dependiendo de los objetivos que tengas. Los conceptos clave que son importantes entender antes de brincar a data science es la programación orientada a objetos y las estruturas de datos. El uso de librerías también es importante ya que tienen cargados todos los módulos para facilitar tu trabajo.
Python es un lenguaje multipropósito, el cual funciona bien si tu trabajo estará vinculado al equipo de desarrollo. Las librerías más importantes que deberías dominar si optas por Python son:
- Numpy: Tiene varias funcionalidades de álgebra lineal, que te permiten trabajar con vectores (arrays y columnas) y matrices (arrays de arrays y tablas).
- Pandas: Te permite procesar y manipular datos como si fueran tablas de Excel utilizando DataFrames. También es de utilidad para exportar datos en formato json, excel, csv y más.
- SciPy: Es una extension de numpy la cual añade mas funcionalidades de estadísticas, álgebra lineal, integración, optimización, etc.
- Matplotlib: Es la librería principal para visualizar datos, aunque también puedes mirar Ploty y Seaborn.
- Scikit Learn: Tiene varios módulos para realizar machine learning (más de esto a continuación).
- TensorFlow y Pytorch: Son librerías de diferenciación automática principalmente usadas para deep learning (más de esto a continuación).
R es un lenguaje para uso estadístico y es recomendable aprender cuando no estarás trabajando directamente con un equipo de desarrollo. Las librerías más importantes para data science son:
- ggplot2: La cual es la librería principal para visualización de datos.
- dplyr y tidy: Con los cuales puedes hacer manipulación de datos.
- mlr3: Es la librería principal para machine learning. Otras librerías interesantes son Caret y XGBoost.
Existen otros lenguajes con los que se puede trabajar en Data Science, como Java, JavaScript, Ruby, Scala o Julia. Pero lo más recomendable es iniciar con Python y/o R.
Toma en consideración aprender a usar otras herramientas fuera de la programación para el análisis y visualización de datos. Algunas de las más importantes son Excel, Power BI, Tableau o Google Data Studio.
El mayor valor de SQL para un data scientist es la posibilidad de hacer consultas a las bases de datos. Con SQL puedes crear, modificar, administrar y eliminar bases de datos y columnas. Sin embargo, esta no es tradicionalmente la tarea de un científico de datos.
- El primer paso para aprender SQL es conocer cómo realizar consultas usando el estándar del lenguaje. Es decir, las sentencias SELECT, FROM, WHERE, ORDER BY, GROUP BY, HAVING, AS, WITH y los diferentes JOINs.
- Después puedes continuar con funciones más avanzadas como window functions, trigger functions, stored procedures, tablespaces y PLSQL. Estas pertenecen a las particularidades de motores de bases de datos como MySQL, PostgreSQL, Oracle o SQL Server.
- Finalmente, aprender sobre soluciones de cloud como (Amazon Web Services, Google Cloud Platform, Azure, IBM Cloud, etc.) es importantísimo para aprovechar las bondades de la Big Data (es decir, los millones de tera bytes disponibles). Por otra parte, para análisis conviene enfocarse a las búsquedas columnares con motores como Redshift o Big Query las cuales son las más populares.
Aunque NoSQL (es decir bases de datos basadas en documentos, key-values, optimizadas para búsqueda, para memoria o basadas en grafos) no son parte común del trabajo de un científico de datos, conviene saber algo de ellas, algunas populares son MongoDB o Firebase para poder tener un acceso aún mayor a datos.
Machine learning es la parte de data science que se encarga de crear modelos que generen predicciones a partir de datos históricos. La idea central de de machine learning es encontrar patrones poco obvios entre nuestros data points.
Una forma fácil de imaginar esto es que nuestro modelo es un niño que está aprendiendo hablar. Lo que el niño dice depende del vocabulario que le enseñenos. Si al niño le enseñamos groserías, dirá groserías. Si al niño le enseñamos jerga, hablará en jerga. Por ende, una parte importante de entrenar un modelo es obtener datos verídicos y representativos del fenómeno que queremos analizar.
Dentro de un algoritmo de machine learning encontramos redes neuronales artificiales. Estas redes procuran emular el proceso en el que un cerebro humano aprende. Es decir, a partir de la sinapsis (unión) de neuronas (nodos). Los nodos de las redes neuronales están divididos en nodos de entrada, nodos en capas escondidas y nodos de salida.
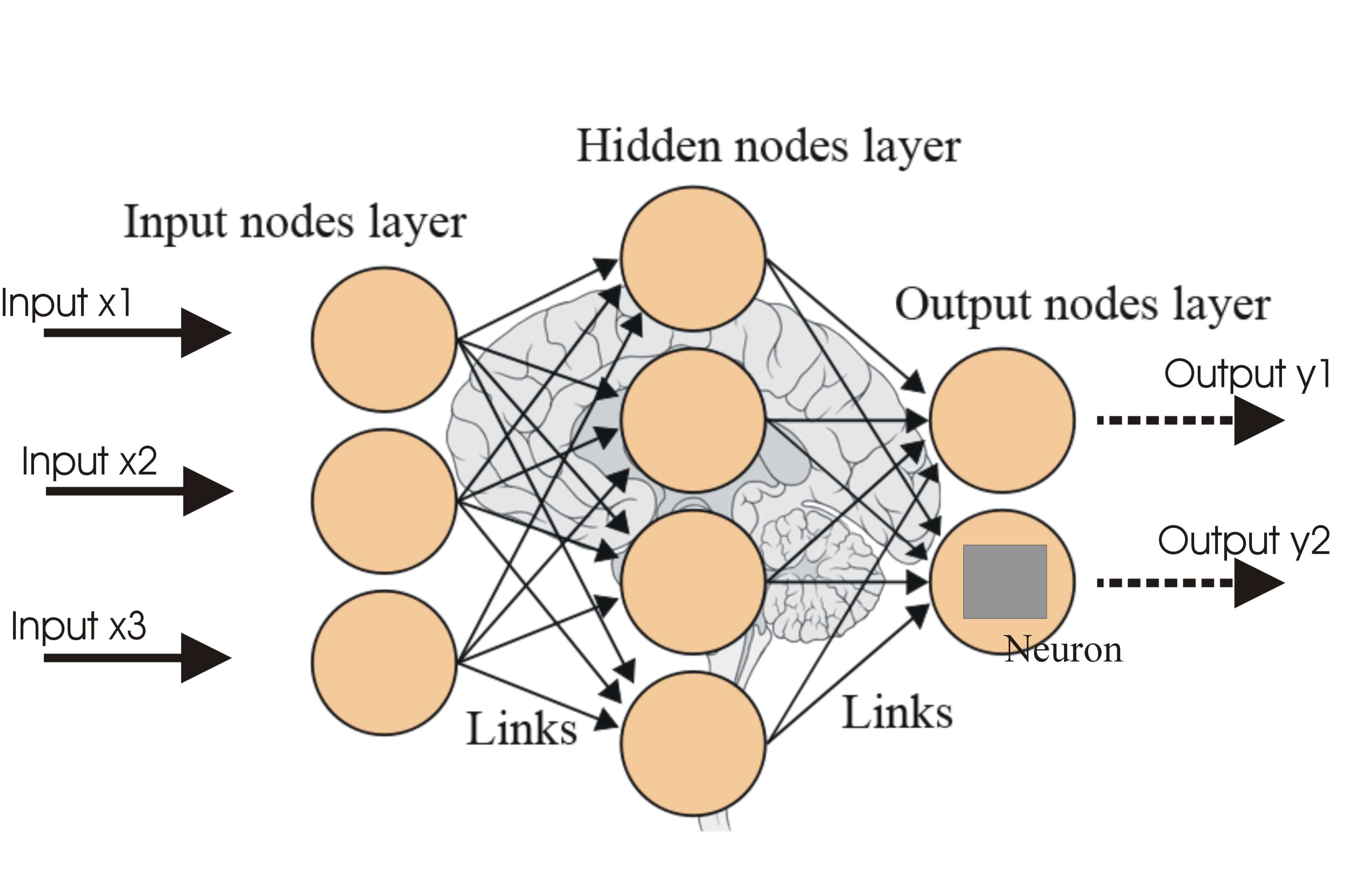
Fig 2. Red Neuronal, machine learning
Una gran ventaja del uso de librerías como Scikit Learn es que los modelos ya estan preconstruidos. Por ende, nosotros debemos de preocuparnos sólo de los datos que usaremos para entrenar el modelo y los hiperparámetros que optimizaran el aprendizaje.
Para poder realizar machine learning adecuadamente es recomendable analizar bien el problema que atendemos para saber que algoritmo es el más recomendable.

Fig 3. Cheat sheet para seleccion de modelo con Scikit learn
Al mismo tiempo, hay que conocer la teoría detrás de estos algoritmos (en gran medida basada en estadística bayesiana). Aunque puedes empezar haciendo machine leaning sin conocimientos matemáticos, es importante que eventualmente también seas consciente de eso para poder optimizar mejor tus modelos.
Principalmente la Inteligencia artificial es un super set del Machine Learning y éste a su vez del Deep learning. La inteligencia artificial en ciencias de la computación, es darle a una maquina una capacidad "cognitiva" de resolver una tarea.
La diferencia entre Deep learning o aprendizaje profundo y machine learning es que el Deep learning puede aprovechar su arquitectura para llevar a cabo transformaciones lineales, con las cuales es posible hacer que la máquina aprenda features no necesariamente explicitas, que pueden estar presentes en cualquier tipo de dato que se utilice para entrenar el modelo.
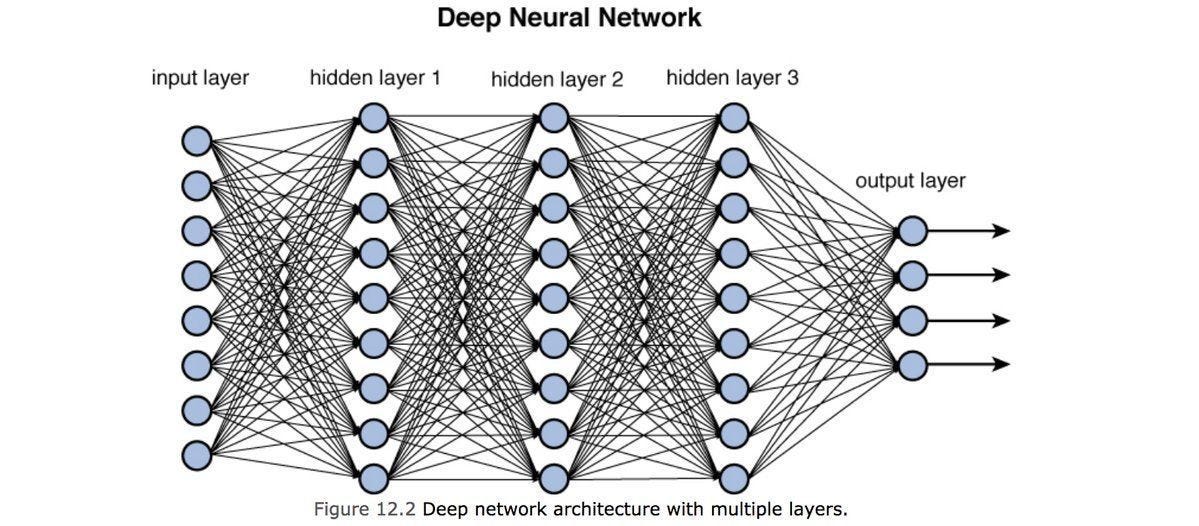
Fig 4. Deep Learning / Deep Artificial Neural Network
A nivel práctico, los modelos de deep learning se realizan con librerías de diferenciación automática como TensorFlow y Pytorch. Además de que los problemas que resolvemos en machine learning tienden a ser enfocados a predecir unidimensionalidades. Es decir: cifras numéricas o textos. En deep learning, las predicciones están más orientadas a identificar multidimensionalidades. Es decir: imágenes, video, audio, etc.
Otra consideración a la hora de trabajar con Deep Learning es que las librerías con las que trabajamos son de bajo nivel. Lo anterior quiere decir que en TensforFlow y Pytorch debemos de tener más cuidado al diseñar las capas, nodos, tasas de aprendizaje y funciones de activación a diferencia de librerías de alto nivel como Scikit Learn.
En cuanto Inteligencia Artificial, tanto machine como deep learning son insumos para diseñar inteligencias artificiales. Cuando realizamos una predicción con Machine o Deep Learning ya estamos creando una inteligencia artificial. Por ende, debemos de tener cuidado de los datos que utilizamos para entrenarla.
No necesitas matemáticas para arrancar con data science, pero es una habilidad que necesitarás para dominar esta disciplina. Lo más importante es que entiendas e internalices los conceptos matemáticos clave. La computadora es la encargada de realizar los cálculos necesarios, por lo que debes concentrarte en conocer cuáles son las herramientas matemáticas que pueden explicar el fenómeno que estas analizando.
Específicamente, necesitas saber lo siguiente:
Estadística básica
Durante el Análisis Exploratorio de Datos, tendrás que aplicar los conceptos elementales de estadística. En un principio tienes un número de data points, los cuales necesitan ser comprendidos antes de ser procesados en un modelo de machine o deep learning. Cuando queremos entender los datos, estamos hablando de estadística descriptiva. Los conceptos clave a entender son:
- Media, moda, mediana: Lo cual nos dice que tan frecuentes son ciertos datos y nos permite identificar datos raros (mejor conocidos como outliers).
- Varianzas y desviaciones estándar: Con lo que podemos identificar rangos dentro de los cuales se encuentran la mayoría de nuestros datos.
- Distribuciones: Las cuales asignan una probabilidad a cada valor dentro de los datos.
- Teorema de Bayes y probabilidades condicionales: Es decir, cómo se ven afectadas las probabilidades de los eventos estudiados dada la informacion de algún otro fenómeno que les afecte.
- Diseño de experimentos: Saber crear hipótesis que pondrás a prueba con la evidencia (datos) con la que dispongas.
Estadística avanzada
En el caso de estadística avanzada, nos enfocamos a usar la estadística para explicar los algoritmos de machine learnig. En este caso, queremos usar datos históricos para predecir eventos o datos futuros. A esto lo llamamos estadística inferencial. Lo importante a entender es:
- Regresion lineal: Es decir, encontrar relaciones lineales entre conjuntos de datos. Por ejemplo, a más horas de ejercicio (variable correlacionada 1) habrá menos colesterol en la sangre (variable correlacionada 2).
- Regresión logística y ensayos de Bernoulli: En donde el resultado solo puede ser binario (cierto o falso). Por ejemplo, una mujer está embarazada o no.
- Clasificación estadística y Naive Bayes: que nos ayuda a agrupar datos según sus características. Comprender esto te permitirá avanzar con algoritmos como KNN o clustering.
- Series de Tiempo: lo cual nos permite ver la evolución a través del tiempo. Por ejemplo, precios de acciones en la bolsa de valores.
- Estimadores de máxima verosimilitud: que nos permite definir los parámetros para mejorar el desempeño de nuestro modelo.
Álgebra lineal
La álgebra lineal nos permite tener un entendimiento más a fondo de los algoritmos de machine learning y cómo sacarles mayor provecho. En particular, vale la pena tener en cuenta lo siguiente:
- Normas de vectores y distancias euclidianas: que nos permite entender nuestras funciones de pérdida. Es decir, cuando nuestro modelo deja de aprender a medida que procesa los datos o lo muy alejado que se encuentra nuestra predicción de la realidad.
- Regularizaciones: para prevenir que nuestro modelo se sobreajuste a los datos que le hemos dado.
- Operaciones de Vectores y Matrices: las cuales son útiles para debuggear redes neuronales, transformar tu información e incluso optimizar cálculos.
- Matrices de covarianza: que nos permite medir la relación lineal dentro de un conjunto de datos.
- Vectores de soporte: los cuales son cruciales para entender qué separa a grupos de datos cuando hacemos clasificaciones.
- Análisis de Componentes Principales (PCA): que es crucial cuando no podemos decidir cuales son los features que más impactan a un conjunto de datos o el número de predictores es muy grande y quieres reducirlo.
- Autocomposiciones: Se trata de estudiar un poco las matrices ya que algunas de ellas poseen ciertas propiedades que permiten optimizar cálculos, entre ellas podemos encontrar los autovalores y autovectores.
Cálculo
Con cálculo podemos analizar las tasas de cambio de las cantidades. Esto genera curvas las cuales podemos medir según su longitud o área, que nos permite optimizar nuestros algoritmos de machine learning. En especial, necesitamos cálculo para:
- Derivadas: Usualmente para entender variaciones variables respecto a otras, principalmente utilizada en los algoritmos de Deep Learning en el paso de backpropagation y se aplican a traves de regla de cadena.
- Algoritmos de Optimización: En general en aprendizaje de máquina los algoritmos de optimización se utilizan para hallar el valor que se acerque más a nuestro objetivo, sea éste hacer una regresión o clasificación. Entre los algoritmos más usados esta el Gradiente descendiente, pero también se encuentra el gradiente adaptativo y momentum.
- Diferenciación Automática: Dentro del Deep learning, en realidad, la transformación de datos se da a traves de la construccion de un grafo computacional, y se aprovechan para formar funciones las cuales se pueden derivar, en general esta parte la cumplen librerias como Tensorflow y Pytorch.
- Integración: La integración es el método para encontrar el área bajo la curva y puede ser utilizado como métrica en algoritmos de clasificación, un ejemplo de este es la métrica AUC que literalmente se conoce como Area Under the Curve del comportamiento de un clasificador.
- Cálculo Multivariable: El cual permitirá enfrentarse a problemas con más de una variable utilizando conceptos fundamentalmente similares de derivación e integración. Son importantes para hablar de reglas de cadena, convergencia, divergencia y gradientes.
Las matemáticas suelen ser un tema que asusta y detiene a muchas personas para entrar a data science y machine learning. Mi consejo es: no te preocupes por hacer cálculos (para eso tienes la computadora). Más bien enfócate en desarrollar un pensamiento probabilístico y matemático que te lleve a a saber seleccionar la mejor solución para el problema al que te estas enfrentando.
Finalmente, es estadísticamente probable que estes enfrentando un problema que alguien más ya solucionó. La clave del éxito es montarte en hombros de gigantes y aprovechar los recursos ya existentes.
Al hablar de conocimiento de negocio nos referimos a responder preguntas como:
- ¿Cuál es el objetivo del negocio?
- ¿Cuáles son las métricas para medir el éxito del negocio?
- ¿De dónde obtenemos datos para tomar decisiones?
- ¿Cuáles son los datos de valor para el negocio?
Es importante a tomar en cuenta que los científicos de datos son aquellos que conocen mejor que nadie los datos más importantes de una organización. Por un lado, un analista de datos o business intelligence se encarga de obtener todos los datos para presentarlos y facilitar la toma de decisiones. La gran diferencia que tienen con un científico de datos es que este último puede hacer uso de machine learning y estadística inferencial para hacer proyecciones sobre lo que podría suceder con el negocio.
Comúnmente se dice que el data scientist es un story teller. Esto es cierto en el sentido que debe de reconstruir hechos para explicar un fenómeno. Debes de considerar también que como científico de datos, debes presentar la información a personas que tienen menos conocimientos matemáticos que tú. La forma más adecuada de hacerlo es a través de gráficos.
Lo más recomendable es estudiar para qué sirven cada uno de los diferentes gráficos. Así mismo, toma en cuenta sus caracaterísticas únicas para sacarle mayor jugo.
Matplotlib, Seaborn y Ploty son las librerías principales si programas en Python, mientras ggplot es ideal para R. Fuera del código, vale la pena familiarizarse con Google Data Studio y Tableau para la creación de tableros.
Por último, recuerda que la visualización de gráficas y la estadística se pueden usar para confundir o engañar. Hacer uso responsable de estas herramientas es parte importante del trabajo de un científico de datos.
Un Jupyter Notebook es un entorno informático, interactivo, basado en la web. Un documento o notebook de Jupyter es en realidad un archivo JSON (con terminación ".ipynb") con una lista ordenada de celdas que pueden contener código, texto, gráficos, etc.
Forma parte también de la colección Anaconda que tiene casi todas las librerías para trabajar en Machine Learning y Data Science. La ventaja que tiene es que puedes probar pedazos de código sin tener la necesidad de saltar entre un IDE y la terminal.
Por su lado, Google Colab tiene casi todas las librerías precargadas y no hay necesidad de instalarlas usando pip.
Es cuestión de gusto personal cuál utilizar. La ventaja de Jupyter Notebook es que corre en localhost, por lo que no dependes de tu conexión de internet para trabajar una vez instaladas las librerías.
Puedes utilizar la versión incluida con Anaconda pero es cargar muchas librerías en tu equipo cuando puedes usar un Jupyter Notebook en tu propio ambiente virtual y sin instalar Anaconda, sólo con algún manejador de paquetes (por ejemplo usando: pip install jupyter). Por ello conviene en ese caso trabajar en un Colab, ya que además ofrece memoria RAM suficiente para trabajar.
Idealmente, como científico de datos deberías tener una idea clara de como es el desarrollo de software.
Uno de los grandes problemas del gremio es que son muchos data scientists que solo saben trabajar en Jupyter Notebooks. Es por ello que vale la pena construir ventajas competitivas. Entre las más importantes incluyen:
- Conocer un framework de backend. Si estás trabajando con Python, es recomendable empezar con Django. Aunque Flask o FastAPI con más fáciles de aprender y operar, la mayoría de proyectos profesionales son desarrollados en Django.
- Cloud, como aquellos que mencionamos en la pregunta 3.
- DevOps es un buen complemento para un científico e ingeniero de datos, ya sea conociendo Bash Shell o administrando servidores Linux.
Entre 6 meses y 2 años es un periodo sensato para adquirir las habiliades para data science, dependiendo de los conocimientos previos que se tengan y el tiempo invertido para aprender.
Aunque nada está escrito sobre piedra, esta es una estimación vaga de tiempo para aprender cada una de los skills para data science:
(Nota: estamos hablando de obtener los conocimientos para usar estas herramientas para data science, más no en su completitud. Por ejemplo, en SQL nos referimos a hacer queries complejos, más no crear, administrar u optimizar una base de datos)
| Skill | 1 hora diaria | 1 - 2 horas diarias | 2 - 4 horas diarias |
|---|---|---|---|
| Python o R | 16-20 semanas | 10-16 semanas | 8-10 semanas |
| SQL | 6-8 semanas | 4-6 semanas | 2-4 semanas |
| Estadística | 12-16 semanas | 4-12 semanas | 4-5 semanas |
| Álgebra lineal | 12-16 semanas | 6-12 semanas | 4-8 semanas |
| Cálculo | 12-16 semanas | 6-12 semanas | 4-8 semanas |
| Cloud | 6-10 semanas | 3-6 semanas | 2-3 semanas |
| Machine Learning | 8-12 semanas | 6-8 semanas | 4-6 semanas |
| Django | 8-16 semanas | 6-10 semanas | 4-8 semanas |
Cada país tiene sus propias leyes respecto al uso de datos. Por lo general, dentro de las empresas los data scientists no son los responsables directos de hacer cumplir estos reglamentos. Sin embargo, conviene saber sobre lo siguiente:
- Los datos solo son de valor para el científico de datos cuando vienen en volumen. Ergo, los datos individuales de un usuario no sirven para el trabajo cotidiano en nuestra área.
- Al hacer el análisis de los datos, hay que procurar que vengan anonimizados. Lo anterior es especialmente importante si son datos bancarios o médicos.
- Conocer un poco de seguridad informática (sobre todo respecto a las buenas prácticas de almacenamiento y tratamiento de datos) es recomendable.
Algunas regularidades que podemos encontrar son la HIPAA, PCI-compliance y GDPR-compliance.
Dentro de la industria tech, data science es de las disciplinas de mayor demanda laboral. Debido a que son muchos los puestos que quedan vacantes para esta posición y pocos los solicitantes, los sueldos en esta área son bastante más elevados en comparación a otros roles en la industria.
- El mejor lugar para conseguir retos y ejercicios es Kaggle.
- Dentro de Kaggle podrás encontrar cursos gratuitos de Python, SQL y más.
- Cursos pagados que valen la pena incluyen Platzi, Data Camp y Data Quest
- Un excelente recurso gratuito para aprender estadística es Crash Course Statistics
- Otro recurso de paga que recomiendo para aprender matemáticas es Brilliant.
- Stack Overflow y Towards Data Science son recursos válidos para encontrar respuestas a problemas comunes de data science.
- Algunas certificaciones que valen la pena tomar incluyen AWS para Machine Learning y Google Cloud Platform para Ingenieria de Datos.
Finalmente, es fundamental siempre consultar la documentación de las tecnologías que usamos y mantener bien documentados nuestros propios proyectos para futura referencia.
(Nota: he utilizado todos estos recursos y no recibo ninguna comisión por promoverlos)
Este apunte fue hecho en conjunto por Xavier Carrera y Gerson Perdomo con una pequeña colaboración de Fer Torres.
Si quieres contactar con Xavier, puedes visitar su sitio web, escribirle en twitter o mandarle un correo a hola@xaviercarrera.com. 🤓
Para contactar con Gerson, puedes enviar un correo a ing.gersonp@gmail.com o encontrarlo en twitter como @gersonrpq. 🤖
Si quieres contactar con Fer Torres, puedes enviarle un correo a contacto@fertorresmx.dev, invitarle un café, visitar fertorresmx.dev o enviarle un saludo en Twitter.