Home
- Overview
- Installation
- Geometry optimization
- Step 1: Structure Generation
- Step 2: Setting Up Your Input Files
- Step 3: Setting up the submit script and submitting jobs to the queue
- Step 4: Viewing your output file
- Running a growing string calculation
- General overview of the DE-GSM and SE-GSM
- Getting started
- Double-ended Growing String Method (DE-GSM)
- Single-ended Growing String Method (SE-GSM)
- Managing QSub Files for DE-GSM/SE-GSM
- Analyzing Output
- Advanced Options
- Troubleshooting and FAQS
- References
- External links
The Growing String Method (GSM) is a reaction path (RP) and transition state (TS) finding method that develops a RP by iteratively adding new nodes (each node is a chemical structure along the RP) and optimizing them until a complete RP with a TS and a stable intermediate on each side of the string are present. The string is represented by a discretized set of structures along the RP connecting the reactant and product geometries (nodes) and its formation can be initiated from a single initial geometry (single ended-GSM) or a pair of initial and final structures (double ended-GSM). By incremental addition of new nodes, GSM rapidly leads to a reasonably well converged RP since it avoids placing nodes at high-energy regions of the potential energy surface. GSM has been shown to outperform competing chain-of-states methods that generate and place all the nodes at once because it avoids optimization of high-energy structures in the middle of the RP.
This method operates through three overall phases: growth, optimization, and exact TS search. The growth phase builds the string representing the RP by sequential node addition and optimization until a reasonably converged path is formed. When the string formation is complete, the optimization phase refines the RP, which also creates a guess-geometry for the exact TS search phase. At the last phase, a saddle point search follows the Hessian eigenvector of the TS node that most closely resembles the reaction path, resulting in a reliable TS optimization. In this phase, the non-TS nodes of the RP continue to be optimized, resulting in a simultaneous formation of the exact TS and minimum energy RP.
Example file for GSM calculation:
https://github.com/ZimmermanGroup/molecularGSM/tree/master/TEST
Examples of geometry optimization:
https://github.com/ZimmermanGroup/molecularGSM/tree/master/tutorial
Read the instructions on the README file here: https://github.com/ZimmermanGroup/molecularGSM
The geometry optimization for molecules in gas phase is divided into 4 steps. The procedure is explained using the acetic acid example.
In order to run reaction path finding calculations, you first need to generate the input structure(s). To do this, you need a visualization software such as Avogadro. When using Avogadro (or any other type of visualization software):
- Draw your structure using the drawing tools
- Check that all atoms are the correct element
- Check that all atoms are connected to the appropriate number of hydrogen atoms (or other atoms)
- Check the bond order for all connections
- Run a quick low level geometry optimization (see below)
- Double check structure to make sure it looks like a good guess at the starting structure for your reaction of interest (e.g. sometimes hydrogen atoms won't be oriented correctly, or the conformation of a ring structure may change in an undesirable way)
- Save your file in .xyz format
See images below for more details:
Avogadro Tools

Optimize Structures Before Saving
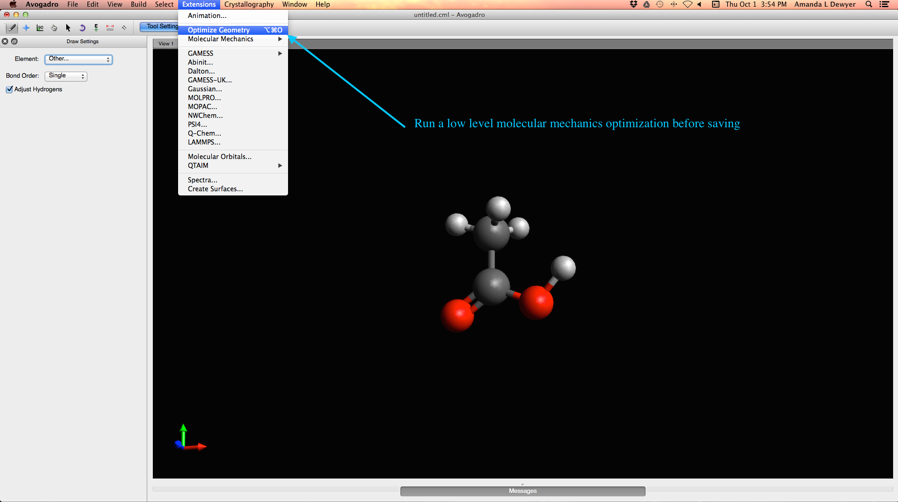
Double check structures before saving
Poor starting structure guess

Good starting structure guess

Both structures above are optimized; the bottom one is lower in energy though.
Save Structure in .xyz format
The .xyz file you save holds the Cartesian coordinates that define the structure you generated. These coordinates will be used for DFT geometry optimizations using a quantum chemical package such as Q-Chem.
In order to run an optimization you need the following files (sample files can be found here):
- Cartesian coordinates of the input structure (generated above)
- q001.template.inp
- submitall.qsh
- getOptEnergy
- makeXYZ
- Knowledge of the appropriate levels of theory to run your calculation at:
- Density functional (ex. B3LYP)
- Exchange Functional
- Correlation Functional
- Basis set (ex. 6-31+G*)
- Restricted or Unrestricted DFT
- Effective Core Potential (ECP) for heavy atoms
- The charge of your structure
- The spin multiplicity of your structure Once you have the above files and details about your calculations you can generate your input file. The file "q001.template.inp" is a template file for optimization calculations. The Cartesian coordinates of the structure should be inserted on line 24 of this file.
- Density functional (ex. B3LYP)
- Exclamation point (!) indicates that the line is commented out (QChem will not read the line).
$rem
JOBTYPE #Tells QChem which type of job is being ran
EXCHANGE #Defines the density functional being used
! CORRELATION #Specifies the use of an optional correlation functional
! UNRESTRICTED #Defines if calculation uses restricted or unrestricted DFT
SCF_ALGORITHM #Specifies the SCF algorithm used in QChem
SCF_MAX_CYCLES #max number of SCF cycles before convergence failure
BASIS #Indicates the basis set being used
ECP #Effective Core Potential being used on heavy atoms
WAVEFUNCTION_ANALYSIS
GEOM_OPT_MAX_CYCLES #max number of geom opts before the optimization fails
scf_convergence #convergence threshold for SCF cycles
SYM_IGNORE #Indicates if symmetry is ignored
SYMMETRY #Indicates if symmetry is turned on
molden_format #Prints xyz coordinates in molden format in the output file
$end
$molecule
0 1 #Charge | Multiplicity
#Cartesian coordinates of structure goes here
$endTo generate your input file, copy this file to a new one with the designated name of your choice. Then edit your new file and fill in the appropriate levels of theory etc. for your calculation.
B3LYP density functional, restricted DFT, LANL2DZ basis set, neutral molecule, spin multiplicity of 1.
$rem
JOBTYPE OPT
EXCHANGE B3LYP
! CORRELATION PBE
! UNRESTRICTED TRUE
SCF_ALGORITHM diis
SCF_MAX_CYCLES 150
BASIS LANL2DZ
ECP LANL2DZ
WAVEFUNCTION_ANALYSIS FALSE
GEOM_OPT_MAX_CYCLES 300
scf_convergence 6
SYM_IGNORE TRUE
SYMMETRY FALSE
molden_format true
$end
$molecule
0 1
O -1.93776 -0.72249 0.00000
C -0.83158 -0.21089 -0.00000
O 0.28198 -0.96655 -0.00000
C -0.52791 1.25073 -0.00000
H -1.46497 1.81470 -0.00000
H 0.03663 1.51185 -0.89846
H 0.03663 1.51185 0.89846
H -0.05498 -1.88701 0.00000
$endOnce your input file is generated, you can run optimizations using Q-Chem by submitting jobs to the queue using the “submitall.qsh” script as shown below:
#PBS -t 2
#PBS -l nodes=1:ppn=2 -l pmem=2000MB -l walltime=24:00:00
ID=`printf “%0*d\n” 3 ${PBS_ARRAYID}`
#i=$PBS_ARRAYID
module load qchem
cd $PBS_O_WORKDIR
name=`ls q$ID*.inp`
qchem -np 2 $name $name.out-
#PBS –t: Indicates the jobs you want to run. It refers to the input file number (q002.methane.inp). You can specify a range or series of files. (ex. “#PBS –t 2-10” or “#PBS –t 2,5,7”) -
ID=`printf “%0*d\n” 3 ${PBS_ARRAYID}`: Indicates the ID of the file by looking at the 3 digits indicated at in the input file. -
module load qchem: Loads Q-Chem. -
name=`ls q$ID*.inp`: Sets the file name -
qchem -np 2 $name $name.out: Indicates the number of processors (np) QChem is using. np in this line needs to match ppn in#PBS –lline. For more information on submitting jobs to the queue see “Workstation Setup” tutorial.
Once your optimization calculations finish, you then need to look at the output. Output files will have the .out extension. QChem will show a message at the end of the output file indicating successful optimization. You can then run the getOptEnergy and makeXYZ executables to obtain the energy of the structure in Hartrees and xyz file of the final optimized geometry, respectively. Once you have completed the geometry optimizations you can use it to search for reaction paths.
Take a look at "Items of Note and Advanced Options" section before setting up a GSM calculation!
As this is most likely the first time you have used the growing string methods, we would encourage you to spend a moment to learn how the software operates. We have included a very general overview of the method here. Depending on the method, the user input varies: for the single ended growing string method (SE-GSM) the starting structure and bonding changes (driving coordinates) are required, for the double ended growing string method (DE-GSM) the start and end structure are required (no bonding changes need to be input by the user). The method takes the input information and generates a string of “nodes”. These nodes represent various geometric conformations along the reaction tangent (the path that the reaction is taking) (Figure 1).

Figure 1. The left picture shows the addition of nodes on the string connecting the starting and end structures (nodes 1 and 7) of an example DE-GSM run. As more nodes are added and subsequently optimized, the string begins to converge toward the transition state. Note how the nodes in the energy diagram on the right increase in energy as they get closer to the transition state. This is considered a good profile for evaluation of a single elementary step. In the final portions of a growing string run, the software takes the highest energy node and optimizes the structure along the reaction path toward the transition state.
As the string is evaluated, all of the nodes are optimized repeatedly until the convergence threshold (in inpfileq) is met. At this point the software will evaluate the “exact transition state”. No further optimization of the transition state is needed. The next sections will outline specific user interaction with the software, how to setup the input file, and common mistakes.
In general, ask yourself the following questions before choosing a particular string method:
- Do you know the end point (final product) of the string you are searching for?
- Do you have the structure optimized for the product of your reaction?
- Are the coordinates of the reaction (the bonds/angles/torsions) difficult to define?
- Are you searching for a single product with a known final conformation?
If you answered yes to any of these questions, then the best bet is probably DE-GSM. For all other cases we would advise attempting the SE-GSM first.
In cases where one has elected to use DE-GSM, you must be certain about the numbering of atoms in the XYZ file. To elaborate, your input parameters (the two starting XYZ files containing the starting material and the product of the transformation) need to have the atoms arranged in the same order. If this is not done correctly, the DE-GSM will not locate the transition state you are looking for.
Obtaining pairs of reactant/product geometries with the correct (matching) atomic arrangement can be achieved in Avogadro and other molecular editors. One can achieve this in Avogadro by adding/removing bonds from the starting structure that correspond to the product/intermediate structure. It is important to avoid adding/deleting atoms as this reorders the atoms within the XYZ file. Lastly, using the force field optimization option in Avogadro should give you an approximate geometry for the product (with the correct order of atoms in the XYZ file) that can be optimized in Q-Chem. A text editor where you can change the order of lines could also be used for this purpose.
First obtain the most recent version of the GSM along with the necessary files and copy them to a new directory. A number of files will be created along with the final stringfile, make sure that your directory is specific enough that the files generated will be easy to distinguish. Example files could be found here.
Copy the files to where you would like to run the job and create your queue submission script through the following command:
$ ./qmakeg
This should generate a qsub file in the scratch directory named go_gsm_dft.qsh. We will come back to this file shortly. Also, one can change the qmakeg file to produce the desired qsub file in the scratch directory.
Take your optimized reactant and product files and put them together through the “cat” command:
$ cat reactant.xyz product.xyz >> scratch/initial0001.xyz
Or by using a text editor such as vim. Additional input files are named sequentially: initial0002.xyz, initial0003.xyz … etc.
It is important to indicate the correct charge and multiplicity for the structures provided in the “initial####.xyz” files as well as the level of theory (functional/basis set) in the input file. The template files provided contains a file called “qstart” where you can input the charge, multiplicity, and level of theory. This file uses the same format as Q-Chem (or your energy calculator), so you should know where to input the charge, multiplicity, density functional, and basis set. To submit the job, use:
$ qsub go_gsm_dft.qsh
or
$ sbatch go_gsm_dft.qsh
or in command line:
./gfstringq.exe jobNumber numberOfCores > scratch/paragsmXXXX
First obtain the most recent version of the GSM along with the necessary files and copy them to a new directory. A number of files will be created along with the final stringfile, make sure that your directory is specific enough that the files generated will be easy to distinguish. Example files could be found here.
Copy the directory to where you would like to run the job and create your queue submission script through the following command:
$ ./qmakeg
This should generate a qsub file in the scratch directory named go_gsm_dft.qsh. We will come back to this file shortly.
Take your input file and copy its contents to initial0001.xyz file:
$ cat reactant.xyz >> scratch/initial0001.xyz
Or by using a text editor such as vim. Additional input files are named sequentially: initial0002.xyz, initial0003.xyz … so on. Note that each "initial" file will only have one set of xyz coordinates since the SE-GSM only requires the reactant and driving coordinates, not both reactant and product.
Look for the paragraph in the previous section titled “Setting up the GSM” to correctly set up the “qstart” file, which indicates the correct charge/multiplicity for the given geometry as well as the desired level of theory used for the optimization of the nodes of the string.
Add the job(s) to the qsub file:

All other lines of the file (starting directories) should update automatically to the correct settings or should not be changed.
After this is complete you are able to submit your job!
Consult the “analyzing your output” section for information about GSM output.
The key to success in analyzing the output of DE-GSM/SE-GSM jobs is using the tools provided in the copied directory (or independent tools developed for personal purposes). However, for starters let’s look at the following:
$ ./status
requires the file “status” in the operating directory
$ molden stringfile.xyz#### where stringfile.xyz### is the output file from the GSM/SSM
This is used to visualize the RP. Any other visualization software could be used instead of molden.
An example output from "./status" created from a random directory is as follows. Status by default prints out the last two opt_iter lines from the output file.

- opt_iter: 59 Displays the number of iterations that the GSM/SSM ran to complete.
- totalgrad: 0.073 Gradient at the transition state.
- gradrms: 0.007 Gradient root mean square for all nodes.
- tgrads: 1015 Total gradients performed to complete the GSM/SSM.
- ol(0): 0.91 Overlap of the transition state with the (n+1)th Hessian vector. The number in parentheses should be either 0/1 while the overlap (0.91) should be close to (1.00).
- E: 2.7 Transition state energy in kcal/mol.
- Erxn: -40.7 ΔH of the rxn in question. It is vital to check the product structure for SSM runs prior to reporting this energy!
- nmax: 4 Number of maximum energy node in the string. Zero indexed.
- TSnode: 4 Number of node optimized for TS. Usually, assuming the string grows correctly and there are no issues with multiple elementary steps in the string.
- -XTS- Well converged TS.
- -TS- ....
- -multistep- Multi elementary step process between starting and ending structure (GSM).
- -FL- The reaction proceeds uphill or downhill in energy with no transition state between reactants and products.
In addition to the settings listed above there are a number of control factors which can be operated by advanced users. Please do not modify these settings unless you have experience with the method, or have been specifically told to make a change. These settings can be found in “inpfileq”. The default settings for GSM are shown below:

The following is a list of what these commands mean and a detailed explanation of what modifications to these settings “should” do. If something in the following list is found to be incorrect or incomplete, please contact the website admin to update.
SM_TYPE: Toggles between GSM and SSM. Use the indicated 3 letter combinations to utilize each of the chosen features.
MAX_OPT_ITERS: Maximum iterations for each step of the GSM.
STEP_OPT_ITERS: Maximum optimizing iterations for each step of the SSM. If starting structure is not properly optimized jobs can fail if the max opt set by this variable is exceeded!
CONV_TOL: Controls the optimization threshold for nodes. Smaller threshold increases the run time, but can improve TS finding in difficult systems.
ADD_NODE_TOL: Tolerance variable for the addition of next node in GSM. Higher numbers will afford fast growth, but decrease accuracy of reaction path identification.
SCALING: For opt steps. This feature controls how the step size is adjusted based on the topography of the previous optimization step. Since the step size is the product of dqmax and the scaling variable, increasing this variable will increase the step size. For more rapid adjustment based on the topography of the reaction path, increase this variable. For less automatic adjustment of the step size, decrease this variable. For the most part, the default setting is fine.
SSM_DQMAX: Controls the spacing between the nodes in SSM. In cases where the RP struggles to converge or the optimization of RP fails, decreasing this value might help.
GROWTH_DIRECTION: GSM specific toggle which enables user control of growth direction. Typically the default (0) is preferred. However, this is a good toggle for debugging more difficult cases. For new users think of the location of the TS; if the TS favors the product then growth from the product with low tolerance convergence could provide better TS identification.
INT_THRESH: Detection threshold for intermediate during string growth. GSM will not consider structures that have a energy below this threshold as a TS along the RP.
INITIAL_OPT: Starting structure optimization performed on the first structure of the input file.
FINAL_OPT: Max number of optimization steps performed on the last node of an SSM run.
TS_FINAL_TYPE: Determines whether rotations are considered causation for termination of the GSM or SSM run. Typically we are searching for a change in bond connectivity so this value is set to 1 for delta bond.
NNODES: Max number of nodes used for GSM. Set this number high (30) for SE-GSM as the convergence criterion typically results in less nodes needed and too small a number for this setting will result in job failure. For DE-GSM the typical is an odd number ranging from 9-15 with higher values being used for identifying multiple TSs along the path.
Q: How do I check the progress of specific runs of the growing string?
A: Check the corresponding paragsm file.
Q: SCF fails repeatedly.
A: Check spin and multiplicity in qstart file. Check that Q-Chem module is loaded correctly. For smaller systems, Q-Chem can fail if you run on too many cores in parallel. Run on no more than 1 cpu per 100 basis functions.
Q: If all files fail and no error is returned
A: Look at error files from queue system, rather than just GSM output.
Q: Error says: error opening gradient file (on gsm run)
A: Double check job to make sure molecule makes sense. This means that there are no missing hydrogens or
obvious problems with bonding. If this is not the problem, make sure to check the qstart, inpfileq and
molecule structure to make sure that charges and spin are in agreement between the files.
-
P. M. Zimmerman, “Growing string method with interpolation and optimization in internal coordinates: Method and examples,” Journal of Chemical Physics, 138, 184102 (2013).
-
P. M. Zimmerman, “Reliable Transition State Searches Integrated with the Growing String Method,” Journal of Chemical Theory and Computation, 9, 3043-3050 (2013).
-
P. M. Zimmerman, “Single-Ended Transition State Finding with the Growing String Method,” Journal of Computational Chemistry, 36, 601-611 (2015).
-
M. Jafari, P. M. Zimmerman, “Reliable and Efficient Reaction Path and Transition State Finding for Surface Reactions with the Growing String Method,” Journal of Computational Chemistry (2017).
-
A. G. Roessler, P. M. Zimmerman, “Examining the Ways To Bend and Break Reaction Pathways Using Mechanochemistry,” J. Phys. Chem. C, 122, 6996-7004, (2018).
-
C. Aldaz, J. Kammeraad, P. M. Zimmerman, “Discovery of Conical Intersection Mediated Photochemistry with Growing String Methods”, Phys. Chem. Chem. Phys., 20, 27394-27405, (2018).