This is the source code repository for the ACL 2023 short paper Black-box language model explanation by context length probing by Ondřej Cífka and Antoine Liutkus.
--single-branch to avoid fetching the demo data files.
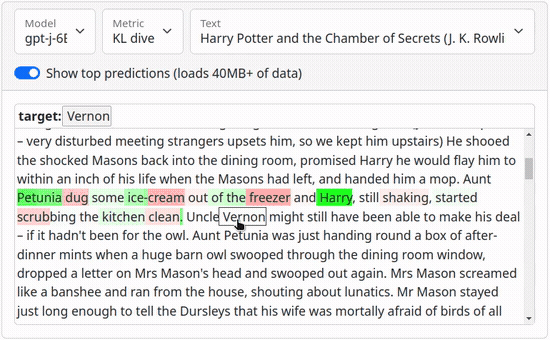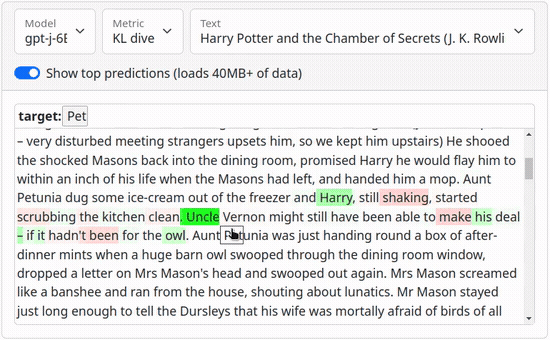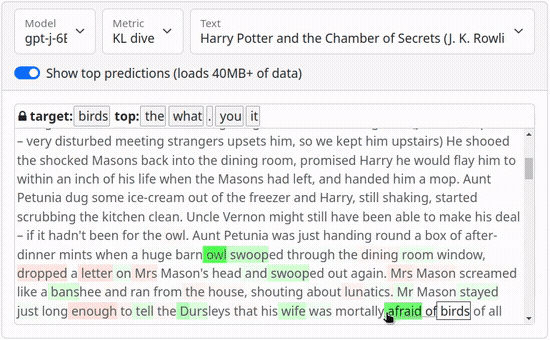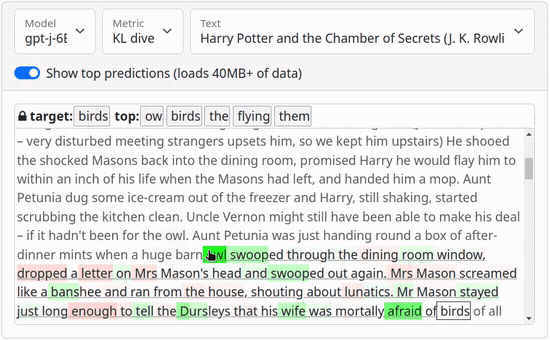
Links:
📃 Paper
🕹️ Demo
🤗 Space
📉 Computed metrics
Citation:
@inproceedings{cifka-liutkus-2023-black,
title = "Black-box language model explanation by context length probing",
author = "C{\'\i}fka, Ond{\v{r}}ej and
Liutkus, Antoine",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-short.92",
pages = "1067--1079",
doi = "10.18653/v1/2023.acl-short.92",
}To install the package, run pip install context-probing.
If you wish to reproduce the experiments, you may want to install from poetry.lock to make sure you have the exact same versions of the dependencies: pip install poetry && poetry install.
The context_probing package provides functions to use our method with 🤗 Transformers with a few lines of code:
from context_probing import run_probing
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
inputs = tokenizer("Harry heard from Hogwarts one sunny morning about a week after he had arrived at The Burrow.")
scores = run_probing(inputs=inputs, model=model, tokenizer=tokenizer)
print(scores){'kl_div': tensor([[nan, nan, nan, ..., nan, nan, nan],
[0.0, 1.2, 1.4, ..., 7.5, 1.8, 2.5],
[nan, 0.0, 0.6, ..., 3.4, 1.3, 2.2],
[nan, nan, 0.0, ..., 2.7, 2.0, 1.2],
...,
[nan, nan, nan, ..., nan, nan, 0.0]], dtype=torch.float16),
'xent': tensor([[nan, nan, nan, ..., nan, nan, nan],
[8.9, 4.7, 12.1, ..., 7.5, 3.2, 4.8],
[nan, 4.0, 11.3, ..., 3.4, 2.7, 5.1],
[nan, nan, 10.7, ..., 2.7, 3.5, 4.3],
...,
[nan, nan, nan, ..., nan, nan, 8.2]], dtype=torch.float16)}The first dimension of each scores tensor corresponds to context length (from 0 up to the total number of tokens), the second dimension to the target token position, starting with the second token ("heard") and ending with the end-of-sequence token ("<|endoftext|>"). Notice that the values are nan for context length 0; see below for how to estimate the metrics for zero-length context.
You can limit the maximum context length (and hence save computation time and space) by setting the window_len parameter to less than the number of input tokens. Otherwise window_len will automatically be set so that it doesn't exceed the number of tokens or the maximum input length allowed by the model.
To obtain the differential importance scores:
from context_probing import get_delta_scores
imp_scores = get_delta_scores(scores["kl_div"], normalize=True, nan_to_zero=False)The first dimension corresponds to the target tokens, the second one to the context tokens. We can plot the scores like so:
from context_probing import ids_to_readable_tokens
import matplotlib.pyplot as plt
tokens = ids_to_readable_tokens(tokenizer, inputs["input_ids"] + [tokenizer.eos_token_id])
plt.imshow(imp_scores, cmap="RdYlGn", vmin=-1., vmax=1.)
plt.colorbar(shrink=0.8)
plt.yticks(range(len(tokens) - 1), tokens[1:])
plt.xticks(range(len(tokens) - 1), tokens[:-1], rotation=90)
plt.xlabel("Context token")
plt.ylabel("Target token")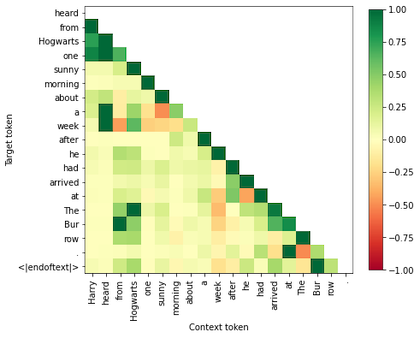
A neural language model normally cannot output unigram probabilities (i.e. with context length 0) as it is always conditioned on some input. Consequently, we cannot easily compute the importance score for the token immediately preceding the target token (i.e. context length 1). However, if we know the unigram probabilities (e.g. if we have access to the language model's training data), we can pass them to run_probing() via the unigram_logprobs parameter in order to enable it to compute the metrics for a null context.
If the unigram probabilities are not known, we can estimate them using the estimate_unigram_logprobs() function, e.g.:
from context_probing import estimate_unigram_logprobs
unigram_logprobs = estimate_unigram_logprobs(model=model, tokenizer=tokenizer)
scores = run_probing(inputs=inputs, model=model, tokenizer=tokenizer, unigram_logprobs=unigram_logprobs)
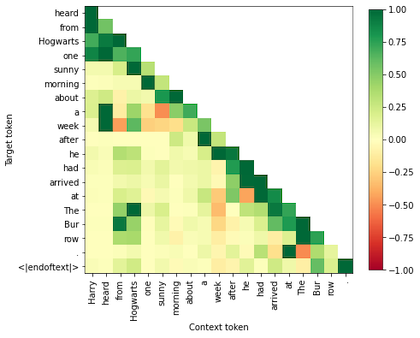
imp_scores = get_delta_scores(scores["kl_div"], normalize=True, nan_to_zero=False)
...Notice that the importance score matrix now has the diagonal (corresponding to the immediately preceding tokens) filled in:
These are the scripts and notebooks used for the paper. They allow for larger models, inputs and contexts than the simple API described above.
conllu_to_hf– Converts a Universal Dependencies dataset in the CoNLL-U format to a tokenized HuggingFace dataset with the annotations included. E.g.:python -m context_probing.scripts.conllu_to_hf \ data/ud-treebanks-v2.10/UD_English-LinES/en_lines-ud-dev.conllu \ data/en_lines-ud-dev \ --tokenizer-path gpt2predict_sliding– Applies a GPT-style language model along a sliding window and saves the logits as NumPy file(s). E.g.:for shard in {0..499}; do python -m context_probing.scripts.predict_sliding \ --model-path EleutherAI/gpt-j-6B --window-len 1024 \ --total-shards 500 --shard-id $shard \ --batch-size 8 --num-proc 8 \ data/en_lines-ud-dev \ preds/gpt-j-6B/en_lines-ud-dev done
⚠️ For theen_lines-ud-devdataset, this will produce 2.1 TB of data (4.2 GB per shard).
⚠️ You may want to parallelize this by submitting each shard to a different compute node. Adjust--num-procand--batch-sizeto the number of available CPU cores and memory.preds_to_metrics– Reads the predictions produced bypredict_slidingand computes different metrics (cross entropy, KL divergence, top k predictions). E.g.:The computed metrics (for thepython -m context_probing.scripts.preds_to_metrics \ --tokenizer-path EleutherAI/gpt-j-6B --topk 10 --max-ctx 1023 \ data/en_lines-ud-dev \ 'preds/gpt-j-6B/en_lines-ud-dev-0*-of-00500.npy' \ gpt-j-6B.en_lines-ud-dev.metrics.pthen_lines-ud-devdataset) can be downloaded here.process_metrics.ipynb– Produces the figures from the paper and the data files for the demo.