Resources for the ICWSM 2022 paper, "Overcoming Language Disparity in Online Content Classification with Multimodal Learning"
Authors: Gaurav Verma, Rohit Mujumdar, Zijie J. Wang, Munmun De Choudhury, and Srijan Kumar
Paper link: https://arxiv.org/abs/2205.09744
Webpage: https://multimodality-language-disparity.github.io/
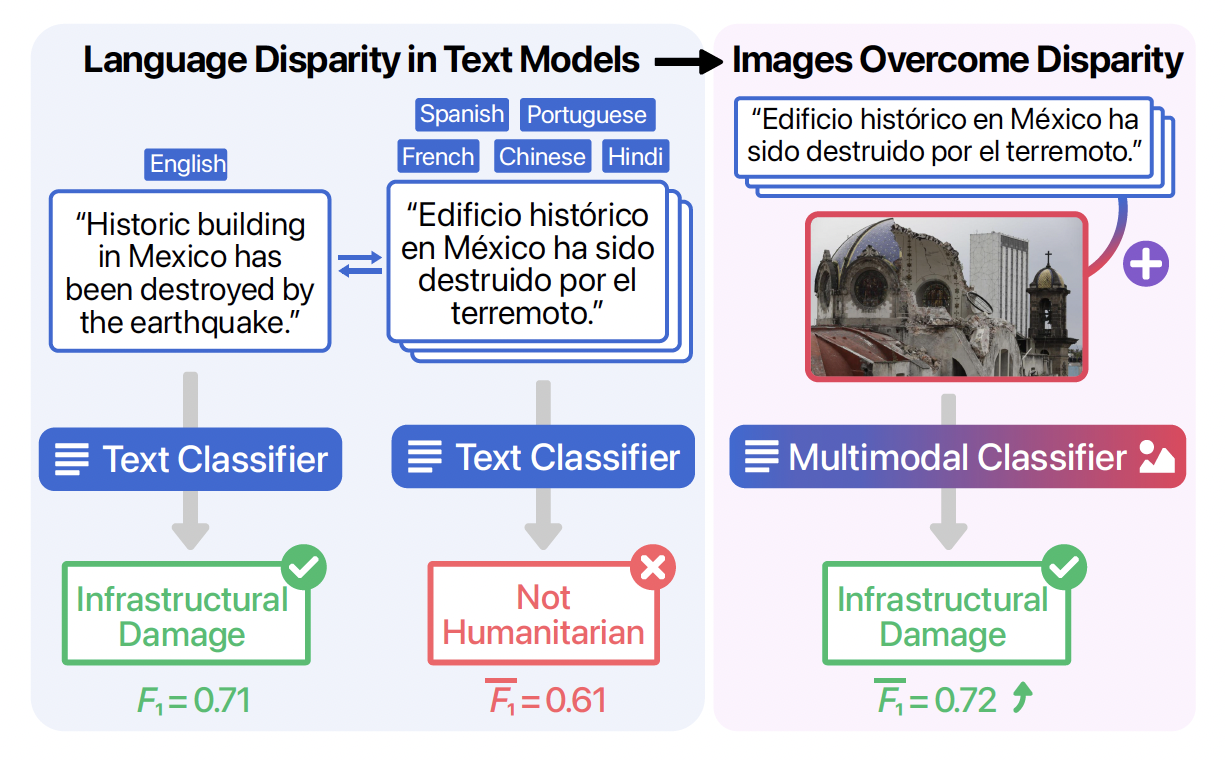
We make the code for fine-tuning BERT-based monolingual and multilingual classifiers available. We have code available for the following languages: English, Spanish, Portuguese, French, Chinese, and Hindi. Please refer to the files inside language-models/ for more details.
We also release the code to fine-tune a VGG-16 image classifier and the code for training a fusion-based multimodal classifiers. Please refer to the files inside image-models/ for more details.
In this work, we consider three social computing tasks that have existing multimodal datasets available. Please download the datasets from respective webpages:
- Crisis humanitarianism (CrisisMMD): https://crisisnlp.qcri.org/crisismmd
- Fake news detection: https://github.com/shiivangii/SpotFakePlus
- Emotion classification: https://github.com/emoclassifier/emoclassifier.github.io (note: if you cannot access the dataset at its original source (proposed in this paper), please contact us for the Reddit URLs we used for our work.)
As part of our evaluation, we create human-translated subset of the CrisisMMD dataset. The human-translated subset contains about ~200 multimodal examples in English, each translated to Spanish, Portuguese, French, Chinese, and Hindi (a total of ~1200 translations). The translations for five non-English languages are available in human-translated-eval-set/. The Twitter IDs for the original examples from the CrisisMMD dataset are available in the file names human-translated-eval-set/tweet_ids.txt – the lines in rest of the translation files correspond to these IDs.
@inproceedings{verma2022overcoming,
title={Overcoming Language Disparity in Online Content Classification with Multimodal Learning},
author={Verma, Gaurav and Mujumdar, Rohit and Wang, Zijie J and De Choudhury, Munmun and Kumar, Srijan},
booktitle={Proceedings of the International AAAI Conference on Web and Social Media},
year={2022}
}