
这是一个私人维护的zabbix安装脚本,它包括了zabbix-server,zabbix-agent的安装,初始化配置,在4.0之后加入了docker-compose,随后的server端都采用了docker安装。在最新的更新中,引入了elasticsearch:6.1.4。在最近的更新中添加了timescaledb。如果你喜欢这个项目,你可以在右上角点击 ♥
-版本信息-
| App | docker-compose | version | User ID | port | date |
|---|---|---|---|---|---|
| mysql | 3.5 | 8.0.15 | 999 | 3306/33060 | 2019/0420 |
| docker.elastic.co | 3.5 | elasticsearch:6.1.4 | 1000 | 9200/9300 | 2019/0420 |
| zabbix-server-mysql | 3.5 | alpine-4.4-latest | 100/1000 | 10051 | 2020/02/03 |
| zabbix-web-nginx-mysql | 3.5 | alpine-4.4-latest | 100/1000/101 | 80 | 2020/02/03 |
| timescaledb | 3.5 | timescale/timescaledb:latest-pg11 | 70 | 5432 | 2020/02/03 |
| zabbix_agent_win | 3.5 | 4.4.7 | 10050 | 2020/03/31 |
note
安装与配置
如果你对docker-compose中的参数有疑问可以参考linuxea:Zabbix-complete-works之Zabbix基础安装配置这篇文章。
倘若你安装的是最新的(4.4),我建议一些优化需要重新做,你可以参考Newbeginning
你至少要使用3.0以上的版本才能够更好的兼容使用。其中保留了一些好的用法,在我看来。这些当中包括:
基础监控
当你安装了Agent,以上包含在MySysOps_Templates模板中
应用监控
- MariaDB主从监控
- MariaDB-Galera mariadb监控分为主从监控,galera监控 ,和mariadb监控的性能监控,他们分别在不同的模板和两个脚本中
- nginx和php-fpm
- Redis
- CrateDB
- ActiveMQ
不要忘记,当你配置完成,你或许应该重启systemctl restart zabbix-agent.service
我在最新的agentd安装脚本中,使用的4.0版本,在这个脚本的包中包含如上的几种基础监控项目。
curl -Lk https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/zabbix_agent/install-agentd.sh|bash -s local ZABBIX_IPADDR
你需要指定server ip,
base -s local ZABBIX_IPADDR或者-s net ZABBIX_IPADDR
docker和docker-compose安装参考-docker官网的安装方式 And - docker-compose安装参考docker-compose官网的安装方式。或者使用docker部署脚本
- 注意:如果已经安装了docker,运行此脚本会删除,同时删除镜像
curl -Lk https://raw.githubusercontent.com/marksugar/MySysOps/master/scripts/docker_init.sh|bash
- windows agent
假如你是windows agent,你需要考虑下载windows的zabbix_agent脚本,修改其中AutoInstall.bat脚本中的zabbix_server的环境变量并且使用超级管理运行,你可能需要了解其细节部分,关注其中的AutoInstall.bat即可。有问题你可以留言。
另外,你可能还需要搭配其模板使用,如: sql server 2012
zabbix在2019的早些版本实验性支持timescaledb,在2020的4.4版本已经官方支持。管家是很大的亮点,他可以减少你对数据切割的必要。如果你是小规模存储,并且你也了解PostgreSQL,那么我强烈推荐使用zabbix+timescaledb。
如果在面对大规模存储长久的数据,还是推荐elasticsearch,但是你要解决单个数据随着时间而变大,查询变慢的问题。毫无疑问,zabbix+elasticsearch非常有研究价值。期待官网支持更新的版本。
快速部署脚本
- zabbix+timescaledb (推荐方式)。
timescaledb和elasticsearch都可以存储大量数据,不过在新版4.4中timescaledb已经官方支持,但是不支持zabbix_proxy,仅仅支持zabbix_server。
正式部署zabbix+timescaledb:
curl -Lk https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/zabbix_server/zabbix-install/install_zabbix_timescaledb.sh|bash
部署细节见describe.md,我在我的博客也做了说明linuxea:zabbix4.2新功能之TimescaleDB数据源测试
这里还有一个timewait优化脚本,你或许可以试试
- zabbix+mysqldb+elasticsearch (适用于大规模)。
在es中的问题,你需要手动添加索引,进行滚动每天的数据,否则他会变大。我目前没有提供这方面的信息。
使用curl -XGET "http://127.0.0.1:9200/_ingest/pipeline?pretty"查看已经创建的索引旋转周期.
curl -Lk https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/zabbix_server/zabbix-install/install_zabbix_mysqldb_es.sh|bash
当然,你仍然可以尝试测试使用zabbix+timescaledb+elasticsearch进行测试部署
如果你使用了是timescaledb,在我当下配置中,zabbix_server describe如下:
| 节点数 | items数 | triggers数 | 性能 | 配置 |
|---|---|---|---|---|
| 540 | 74360 | 28896 | 1259.64 | 8C8G |
timescaledb如下:
| 节点数 | items数 | triggers数 | 性能 | 配置 |
|---|---|---|---|---|
| 540 | 74360 | 28896 | 1259.64 | 8C8G500G |
实际使用中:
-
zabbix-server 8核8G在具体表现中稳定在2核2G的使用
-
timescaledb 8核8G在具体表现中稳定在2核5G的使用
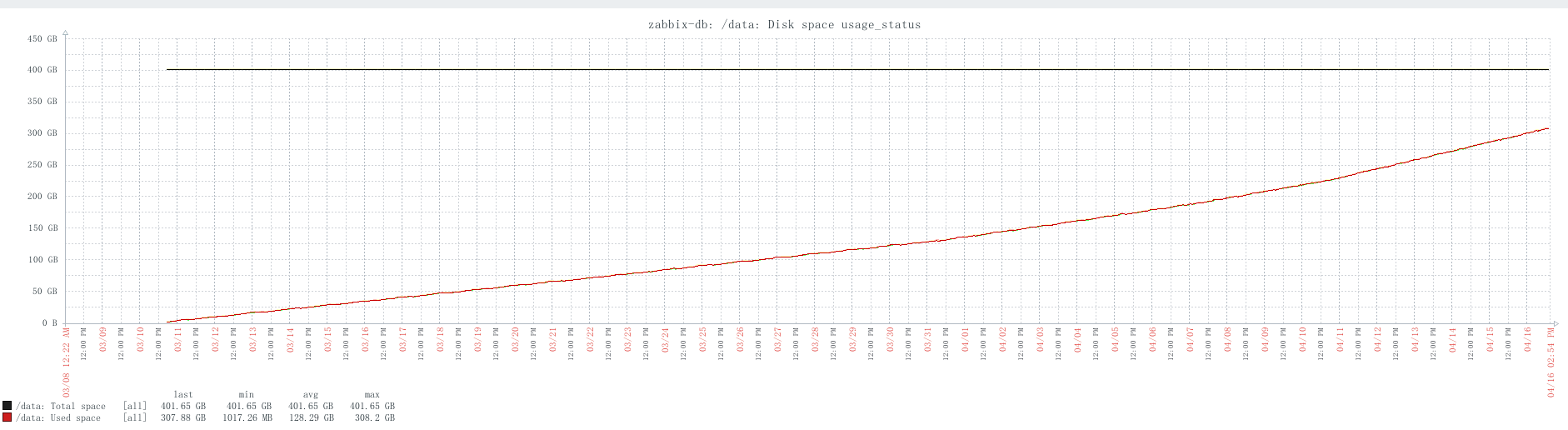
磁盘:在上述的体现中。400G磁盘37天使用300G
自动发现节点参考zabbix4.2的自动发现教程
半自动发现参考redis自动发现db
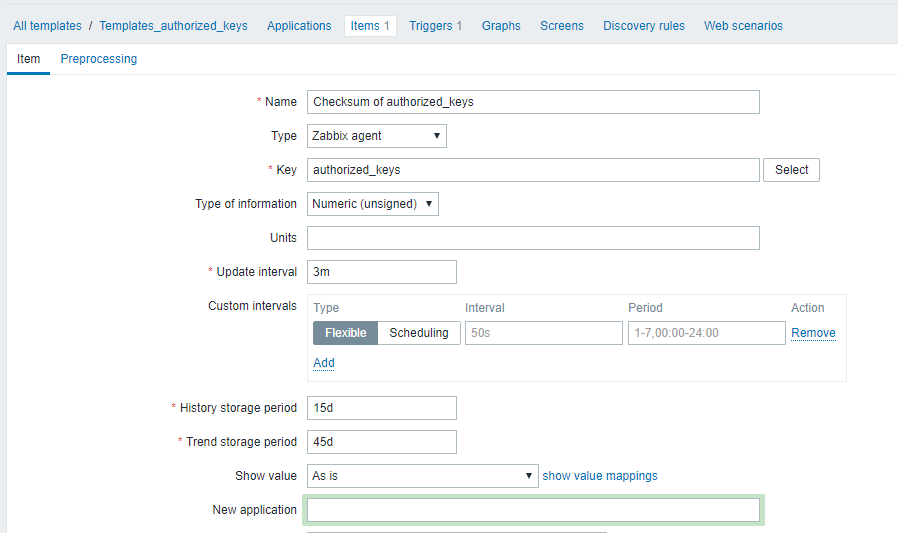
- Templates Name: MySysOps_Templates.xml
这需要sudo权限
zabbix ALL=(root)NOPASSWD:/usr/bin/cksum /root/.ssh/authorized_keys
zabbix ALL=(root)NOPASSWD:/usr/bin/awk
而后添加
- UserParameter
UserParameter=authorized_keys,sudo /usr/bin/cksum /root/.ssh/authorized_keys|awk '{print $1}'
如果你有好点子,你可以修改
- Items
- Trigger
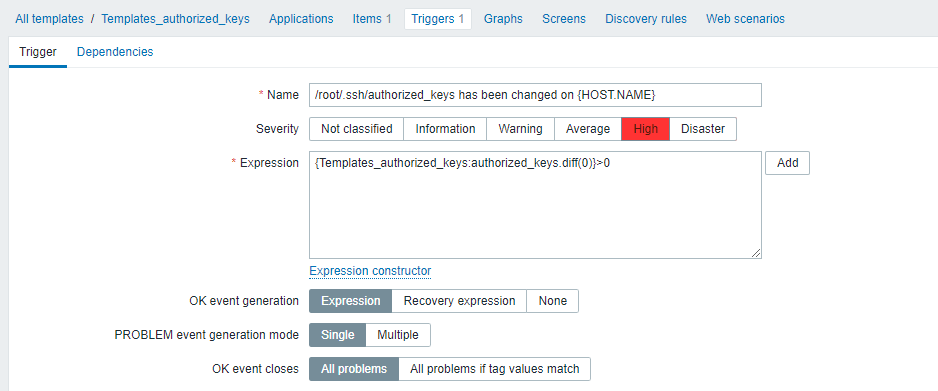
在最新的版本中已经存在
UserParameter=status_passwd,cksum /etc/passwd|cut -c 1-5
- Items
- Trigger
Not Items
key : vfs.file.cksum[/etc/zabbix/zabbix_agentd.conf]
UserParameter=OOM_stats,sudo awk '/kill|OOM|killer/{print $0}' /var/log/messages|md5sum |cut -c 1-5
- Items
- Trigger
- Templates Name: MySysOps_Templates.xml
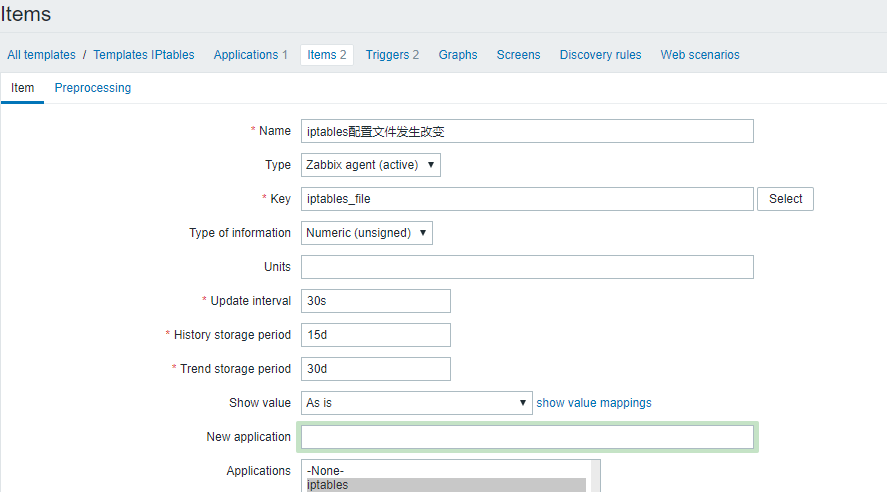
我仍然使用了及其简单的方式来监控iptables变化,但是你需要注意,这个变化的报警的时间非常短
- UserParameter
UserParameter=iptables_lins,/usr/bin/sudo iptables -S |md5sum|cut -c 1-5
UserParameter=iptables_file,/usr/bin/sudo /usr/bin/cksum /etc/sysconfig/iptables|cut -c 1-5
另外,需要sudo权限
zabbix ALL=(root)NOPASSWD:/usr/sbin/iptables,/usr/bin/cksum /etc/sysconfig/iptables
- Items
- Trigger
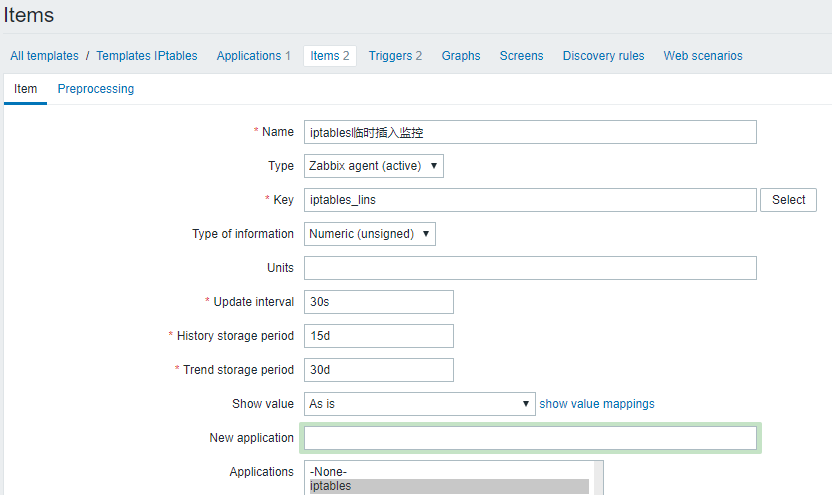
- Templates Name: MySysOps_Templates.xml
在这里下载perl脚本。并且要给755权限
- UserParameter
UserParameter=discovery.disks.iostats,/etc/zabbix/scripts/disk.pl
UserParameter=custom.vfs.dev.read.sectors[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$6}'
UserParameter=custom.vfs.dev.write.sectors[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$10}'
UserParameter=custom.vfs.dev.read.ops[*],cat /proc/diskstats | grep $1 | head -1 |awk '{print $$4}'
UserParameter=custom.vfs.dev.write.ops[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$8}'
UserParameter=custom.vfs.dev.read.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$7}'
UserParameter=custom.vfs.dev.write.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$11}'
这个是一个自动发现做的
- Items
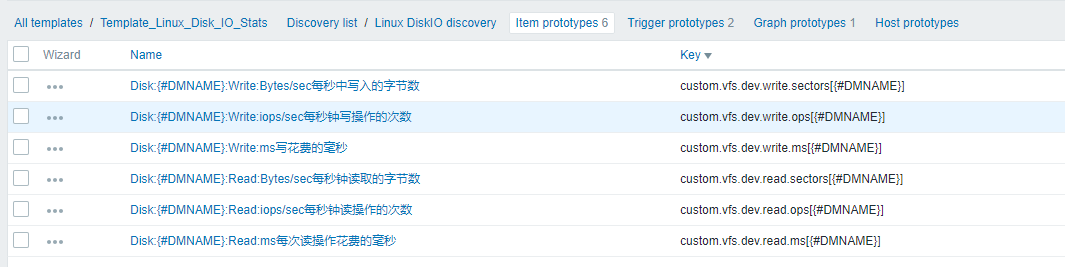
- Trigger

注意
你需要创建正则表达式: 名称为Linux disks for autodiscovery(必须)
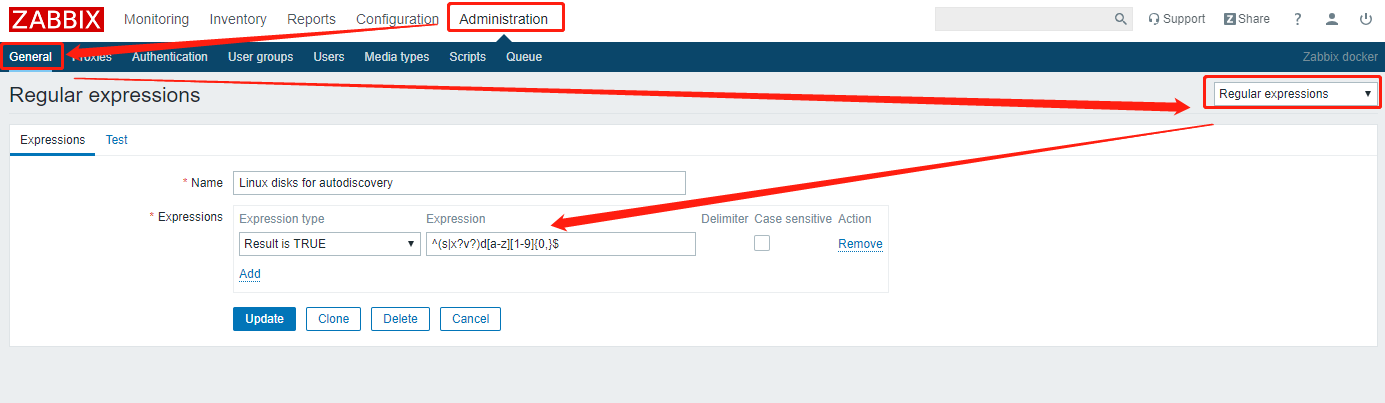
- Expression
^(s|x?v?)d[a-z][1-9]{0,}$
- Templates Name: Template_Nginx_Status.xml
- Templates Name: Template_PHP-FPM_status.xml
准备
server {
listen 40080;
server_name localhost;
location /nginx_status
{
stub_status on;
access_log off;
}
location /php-fpm_status
{
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $fastcgi_script_name;
include fastcgi_params;
}
}
在这里下载nginx脚本
- php
php就更简单了,直接访问抓取即可
- UserParameter
UserParameter=nginx.status[*],/etc/zabbix/scripts/nginx_status.sh $1 $2
UserParameter=php-fpm.status[*],/usr/bin/curl -s "http://127.0.0.1:40080/php-fpm_status?xml" | grep "<$1>" | awk -F'>|<' '{ print $$3}'
- nginx-Items
- Trigger

- php-fpm-Items
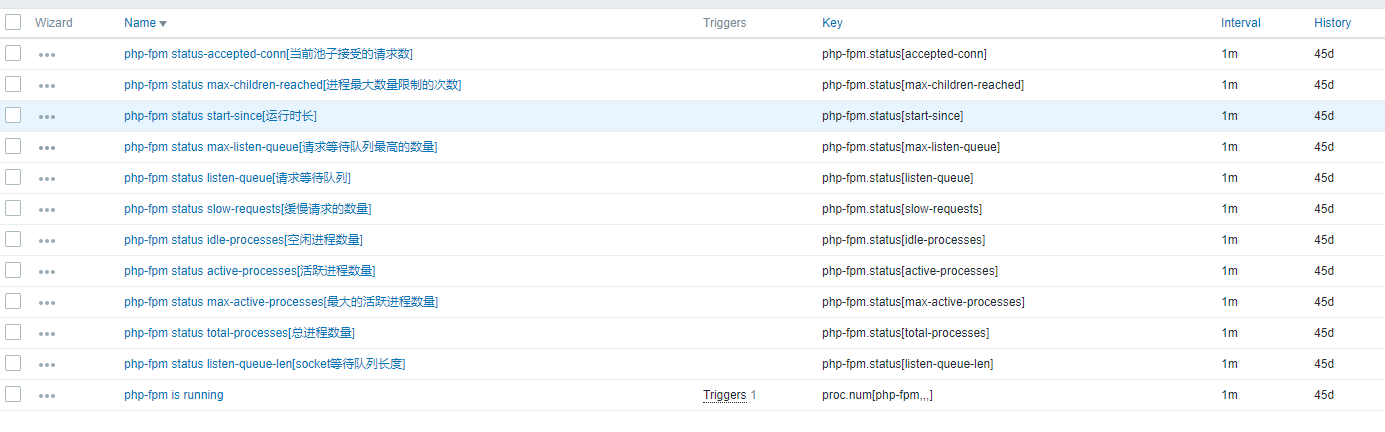
- Trigger

我用了一种简单的方式来进行监控,在我看来越简单越好用。
- Templates Name: MySysOps_Templates.xml
需要提醒的是,我存放在计划任务中执行的统计信息,存放在/tmp/下,而后使用脚本去抓取。计划任务默认最小粒度1分钟一次
*/1 * * * * /usr/sbin/ss -tan|awk 'NR>1{++S[$1]}END{for (a in S) print a,S[a]}' > /tmp/tcp-status.txt
*/1 * * * * /usr/sbin/ss -o state established '( dport = :http or sport = :http )' |grep -v Netid > /tmp/httpNUB.txt
- UserParameter
UserParameter=tcp.status[*],awk '{if ($$1~/^$1/)print $$2}' /tmp/tcp-status.txt
UserParameter=tcp.httpd_established,awk 'NR>1' /tmp/httpNUB.txt|wc -l
- Items
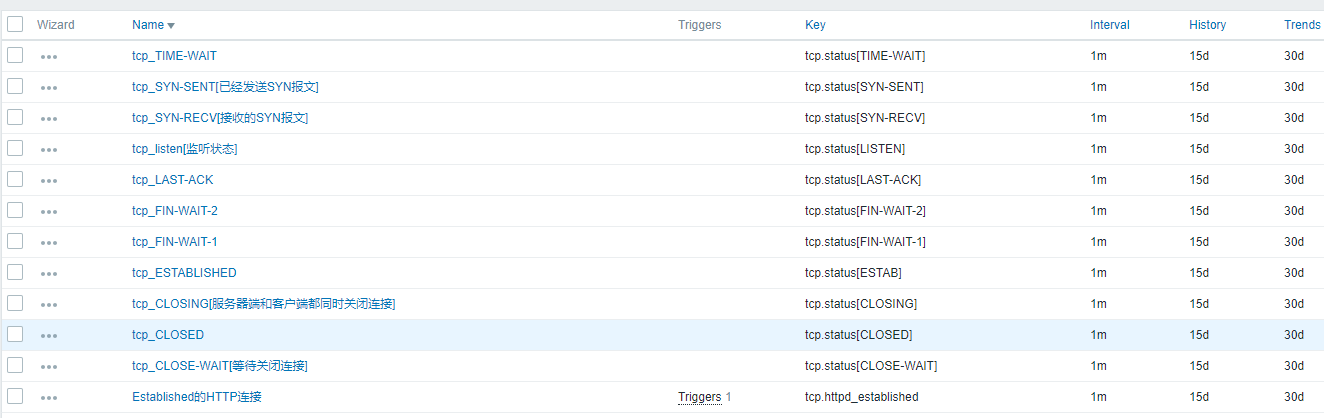
- Trigger

如果你是主从结构,你需要导入Mariadb_M-S_Thread.xml模板,并且使用app-scripts中的IO_SQL.sh脚本配合使用。脚本内容如下:
- Templates Name: Mariadb_M-S_Thread.xml
#/bin/bash
# https://github.com/marksugar/zabbix-complete-works
DEF="--defaults-file=/etc/zabbix/zabbixmy.conf"
MYSQL='/usr/local/mariadb/bin/mysql'
ARGS=1
if [ $# -ne "$ARGS" ];then
echo "Please input one arguement:"
fi
case $1 in
Slave_IO_Running)
result=`${MYSQL} $DEF -e "show slave status\G"|awk '/Slave_IO_Running/{print $2}'`
echo $result
;;
Slave_SQL_Running)
result=`${MYSQL} $DEF -e "show slave status\G"|awk '/Slave_SQL_Running/{print $2}'`
echo $result
;;
*)
echo "Usage:$0(Slave_SQL_Running|Slave_IO_Running)"
;;
esac
分别是监控两个进程
maria.IO_SQL[Slave_IO_Running]
maria.IO_SQL[Slave_SQL_Running]
- 授权sql
GRANT SELECT ON *.* TO 'zabbix'@'127.0.0.1' IDENTIFIED BY 'password';
- UserParameter
echo "UserParameter=maria.IO_SQL[*],/etc/zabbix/scripts/IO_SQL.sh \$1" >> /etc/zabbix/zabbix_agentd.conf
当然,除此之外,想监控更多,你还要导入Mariadb_monitoring.xml和调用app-scripts中的mariadb.sh脚本来监控其他的项目,比如innodb的情况等。
这是一个非常简单的mariadb-galera-clster监控项目,它不适用于一般的主从结构。
-
Templates Name: mariadb-galera-cluster-monitor.xml
-
授权sql
GRANT SELECT ON *.* TO 'zabbix'@'127.0.0.1' IDENTIFIED BY 'password';
- UserParameter
echo "UserParameter=maria.db[*],/etc/zabbix/scripts/mariadb.sh \$1" >> /etc/zabbix/zabbix_agentd.conf
app-scripts中的mariadb.sh作为脚本来调用,你需要导入mariadb-galera-cluster-monitor.xml文件,如果你要更详细的信息,你仍然需要导入Mariadb_monitoring.xml。而这些都调用app-scripts中的mariadb.sh
对于redis仅仅只是做了一些简单的监控,不包含主从或者集群。如下图:
- Templates Name: redis-info-status.xml
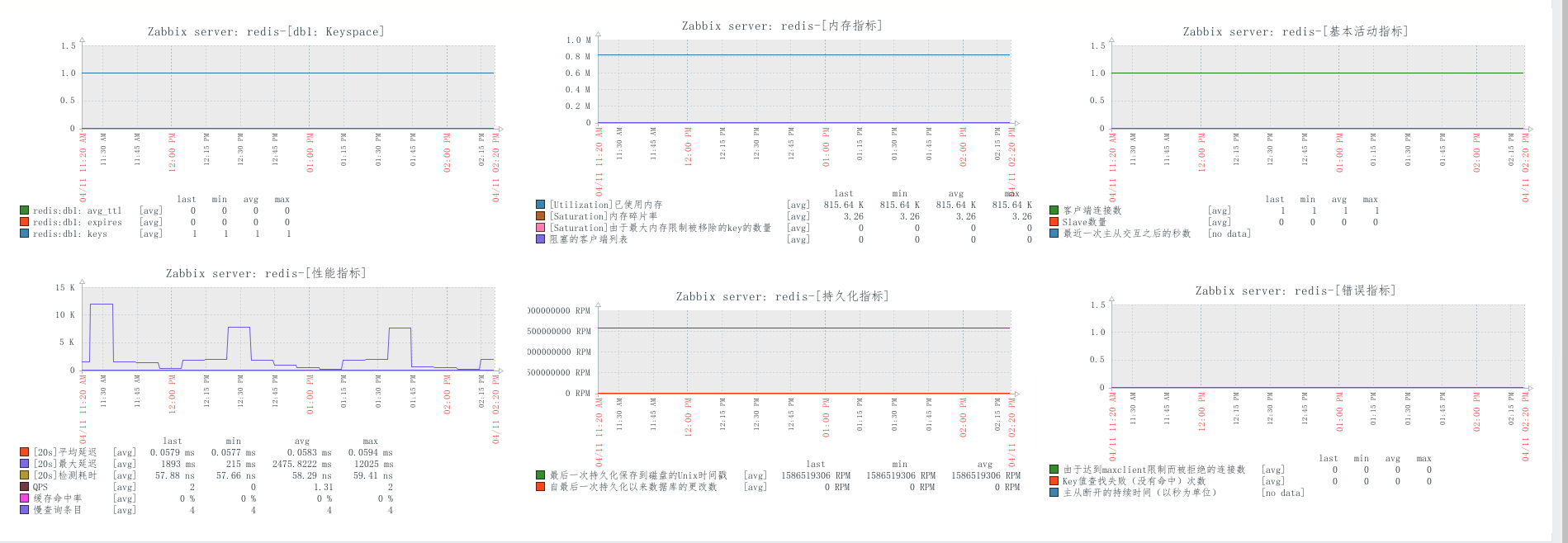
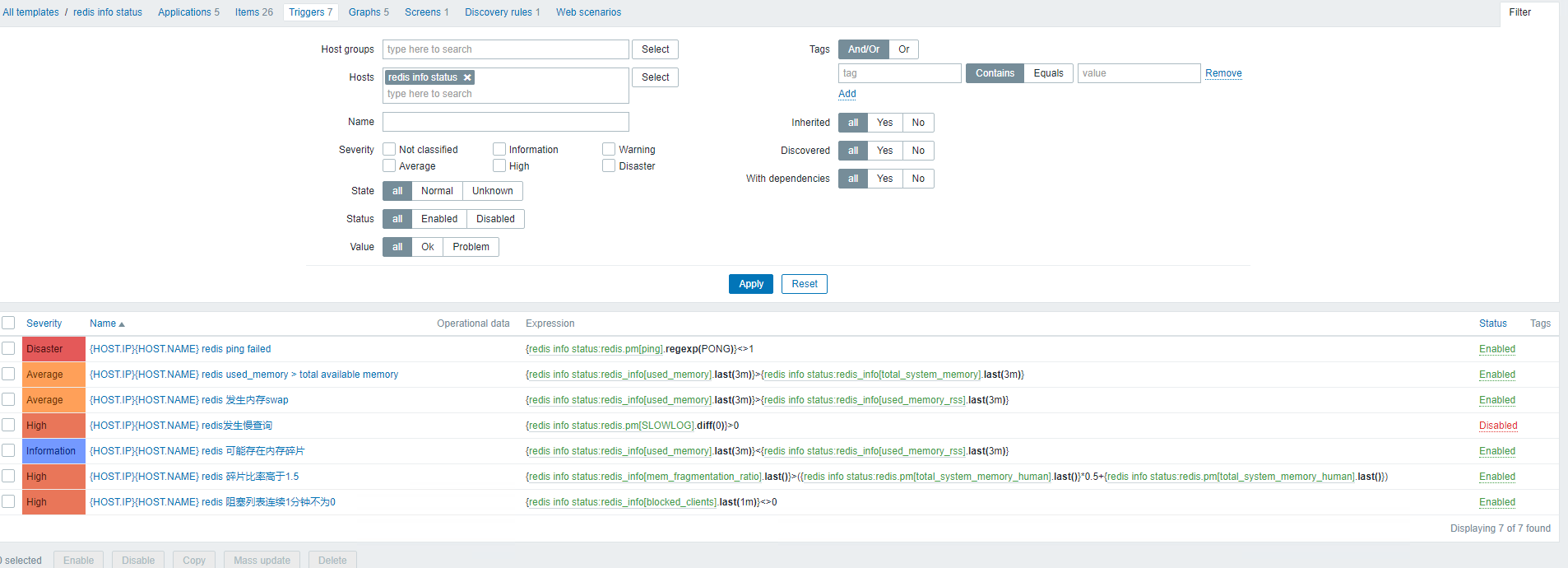
脚本redis.sh在app-scripts/redis下,通过deploy-redis.sh进行部署,细节如下:
需要注意:--intrinsic-latency 20 20是作为20秒进行探测的,可以修改更小
read -p "输入redis密码:" repassword
mkdir -p /etc/zabbix/scripts/
curl -LKs https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/app-scripts/redis/redis.sh -o /etc/zabbix/scripts/redis.sh
curl -LKs https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/app-scripts/redis/redis_discovery.py -o /etc/zabbix/scripts/redis_discovery.py
sed -i 's@#Include=/etc/zabbix/zabbix_agentd.d/*.conf@Include=/etc/zabbix/zabbix_agentd.d/*.conf@g' /etc/zabbix/zabbix_agentd.conf
curl -LKs https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/app-scripts/redis/redis.conf -o /etc/zabbix/zabbix_agentd.d/redis.conf
chmod +x /etc/zabbix/scripts/redis*
sed -i "s/mima/$repassword/g" /etc/zabbix/scripts/redis.sh /etc/zabbix/scripts/redis_discovery.py /etc/zabbix/zabbix_agentd.d/redis.conf
grep Timeout=30 /etc/zabbix/zabbix_agentd.conf || echo "Timeout=30" >> /etc/zabbix/zabbix_agentd.conf
systemctl restart zabbix-agent.service
快速部署如下:
bash <(curl -s https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/app-scripts/redis/deploy-redis.sh|more)
- redis-cli安装:
curl -Lk https://raw.githubusercontent.com/marksugar/Maops/master/redis-cli/install.sh|bash
createdb本身不对zabbix提取不友好,而对prometheus友好。我只是简单的做了集群的监控,我怀疑我的“增删改查”几个项有问题。暂且如此
- Templates Name: CrateDB Simple cluster monitoring.xml
模板位于app-templates下的CrateDB Simple cluster monitoring.xml
cratedb.conf如下:
#集群状态GREEN :
UserParameter=CRATE_STATUS,curl -sXPOST localhost:4200/_sql -d '{"stmt":"SELECT (SELECT health FROM sys.health ORDER BY severity DESC LIMIT 1) AS health, (SELECT sum(missing_shards) FROM sys.health) AS missing_shards, (SELECT count(*) FROM sys.nodes) AS num_nodes;"}' |awk -F\" '{print $12}'
#集群成员数量:
UserParameter=CRATE_CLUST_NUM,curl -sXPOST localhost:4200/_sql -d '{"stmt":"SELECT (SELECT health FROM sys.health ORDER BY severity DESC LIMIT 1) AS health, (SELECT sum(missing_shards) FROM sys.health) AS missing_shards, (SELECT count(*) FROM sys.nodes) AS num_nodes;"}' |python -m json.tool|awk 'FNR==13{print $1}'
#集群分片,为0正常 未分配或启动的分片数
UserParameter=CRATE_MISSING_SHARDS,curl -sXPOST localhost:4200/_sql -d '{"stmt":"SELECT (SELECT health FROM sys.health ORDER BY severity DESC LIMIT 1) AS health, (SELECT sum(missing_shards) FROM sys.health) AS missing_shards, (SELECT count(*) FROM sys.nodes) AS num_nodes;"}' |awk -F\, '{print $5}'
#增删改查
UserParameter=CRATE_INSERT,curl -sXPOST localhost:4200/_sql -d '{"stmt":"select node,classification FROM sys.jobs_metrics;"}' |python -m json.tool|grep INSERT|wc -l
UserParameter=CRATE_SELECT,curl -sXPOST localhost:4200/_sql -d '{"stmt":"select node,classification FROM sys.jobs_metrics;"}' |python -m json.tool|grep SELECT|wc -l
UserParameter=CRATE_DELETE,curl -sXPOST localhost:4200/_sql -d '{"stmt":"select node,classification FROM sys.jobs_metrics;"}' |python -m json.tool|grep DELETE|wc -l
UserParameter=CRATE_COPY,curl -sXPOST localhost:4200/_sql -d '{"stmt":"select node,classification FROM sys.jobs_metrics;"}' |python -m json.tool|grep COPY|wc -l
UserParameter=CRATE_DDL,curl -sXPOST localhost:4200/_sql -d '{"stmt":"select node,classification FROM sys.jobs_metrics;"}' |python -m json.tool|grep DDL|wc -l
UserParameter=CRATE_MANAGEMENT,curl -sXPOST localhost:4200/_sql -d '{"stmt":"select node,classification FROM sys.jobs_metrics;"}' |python -m json.tool|grep MANAGEMENT|wc -l
下载cratedb.conf
curl -LKs https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/app-scripts/cratedb/cratedb.conf -o /etc/zabbix/zabbix_agentd.d/cratedb.conf
除了上的,你也可以通过
查看集群
select health from sys.health order by severity desc limit 1;
查看未同步的信息
select * from sys.health order by severity desc, table_name;
这些信息在**官网的页面**有解释,我只是简单做了集群的健康状态监控。
使用自动发现队列,监控队列的值。
通过url http://127.0.0.1:8161/admin/xml/queues.jsp抓取queue,获取值达到监控的目的
- Templates Name: activemq-queues-monitoring.xml。
发现队列Queues_Name.py脚本存放在app-scripts/activemq下,模板位置名称activemq-queues-monitoring.xml。
脚本如下:
#!/usr/bin/env python
#-*- encoding: utf-8 -*-
#########################################################################
# File Name: Queues_Name.py
# Author: www.linuxea.com
# https://github.com/marksugar/zabbix-complete-works
#########################################################################
import os
import json
t=os.popen(""" curl -s -uadmin:admin http://127.0.0.1:8161/admin/queues.jsp | awk -F'<' '/<\/a><\/td>/{print $1}' """)
QUEUES_NAME = []
for dname in t.readlines():
r = os.path.basename(dname.strip())
QUEUES_NAME += [{'{#QUEUES_NAME}':r}]
print json.dumps({'data':QUEUES_NAME},sort_keys=True,indent=4,separators=(',',':'))
activemq.conf
UserParameter=discovery.activemq.queues,/etc/zabbix/scripts/Queues_Name.py
UserParameter=discovery.activemq.status,curl -s -uadmin:admin http://127.0.0.1:8161/api/jolokia/ | python -m json.tool|awk '/status/{print $2}'|awk -F\, '{print $1}'
UserParameter=activemq.status[*],curl -s -uadmin:admin http://127.0.0.1:8161/admin/xml/queues.jsp |grep -v "^$"| grep -A 5 """<queue name=\"$1\">"""|awk -F \" '/$2/{print $$2}'
- 配置到ActiveMQ节点:
mkdir -p /etc/zabbix/scripts
sed -i 's@#Include=/etc/zabbix/zabbix_agentd.d/*.conf@Include=/etc/zabbix/zabbix_agentd.d/*.conf@g' /etc/zabbix/zabbix_agentd.conf
curl -LKs https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/app-scripts/activemq/activemq.conf -o /etc/zabbix/zabbix_agentd.d/activemq.conf
curl -LKs https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/app-scripts/activemq/Queues_Name.py -o /etc/zabbix/scripts/Queues_Name.py
script:
curl -LKs https://raw.githubusercontent.com/marksugar/zabbix-complete-works/master/app-scripts/activemq/activemq_queues.sh |bash