In the modern tech environment, reliability, replication, redundacy and fault tolerance hold high importance, all of which are effectively ensured by the Raft consensus protocol. However, the predominant approach in Raft consensus implementations involves the use of REST APIs. There exists a potential to optimize the performance of Raft consensus by transitioning to gRPC. This project provides a Go implementation of a key/value store using Raft consensus protocol utilizing gRPC for communication between Raft peers. It subsequently evaluates the performance metrics of the Raft cluster.
The use cases for such a library are far-reaching, such as replicated state machines which are a key component of many distributed systems. They enable building Consistent, Partition Tolerant (CP) systems, with limited fault tolerance as well.
It is recommended to have Go installed before running the project. Go can be installed from the official Go website. This project was built using Go version 1.22.2.
Run the following command to check the code against all the available test cases
make testThe project can be run using:
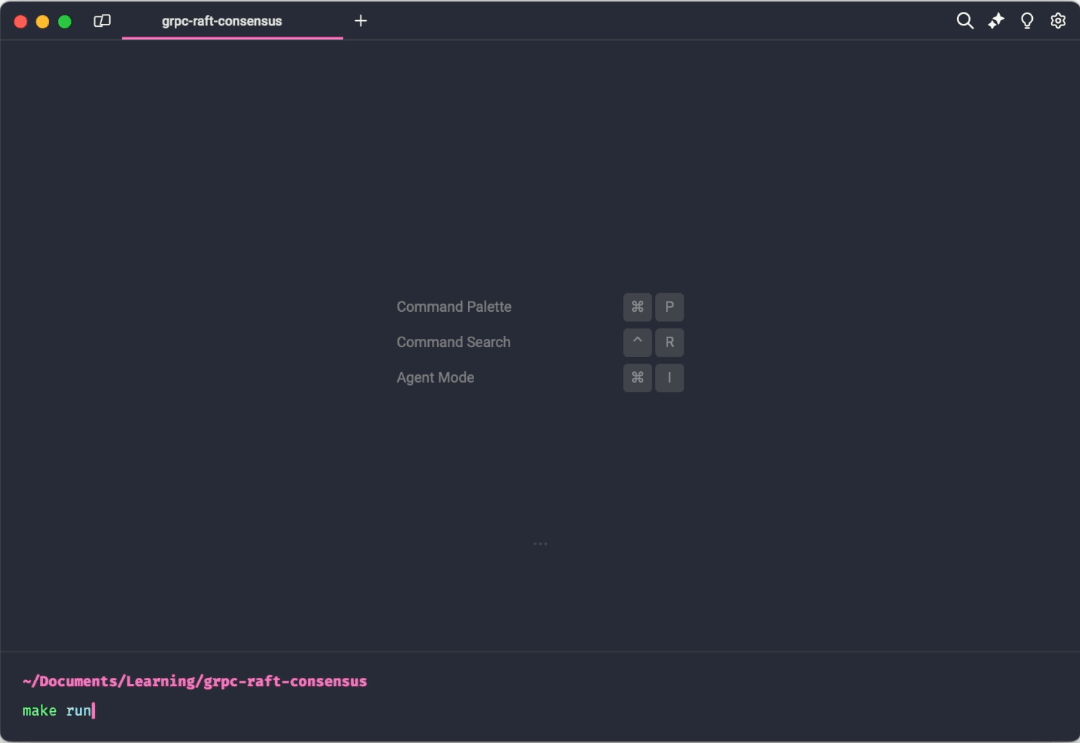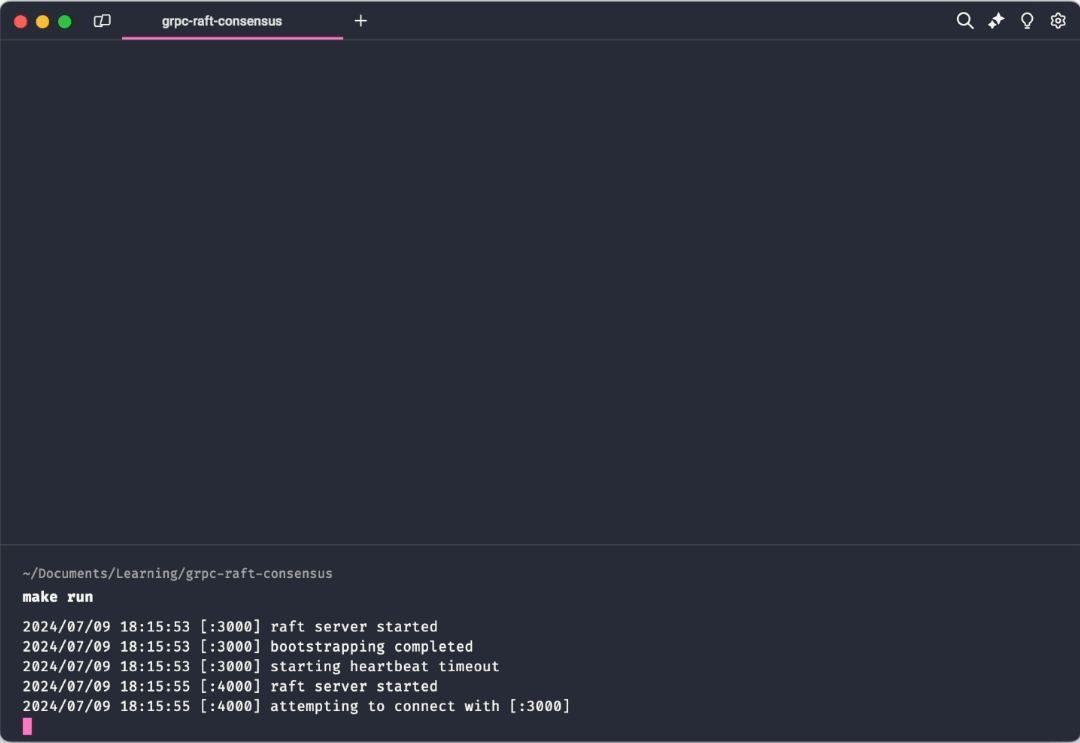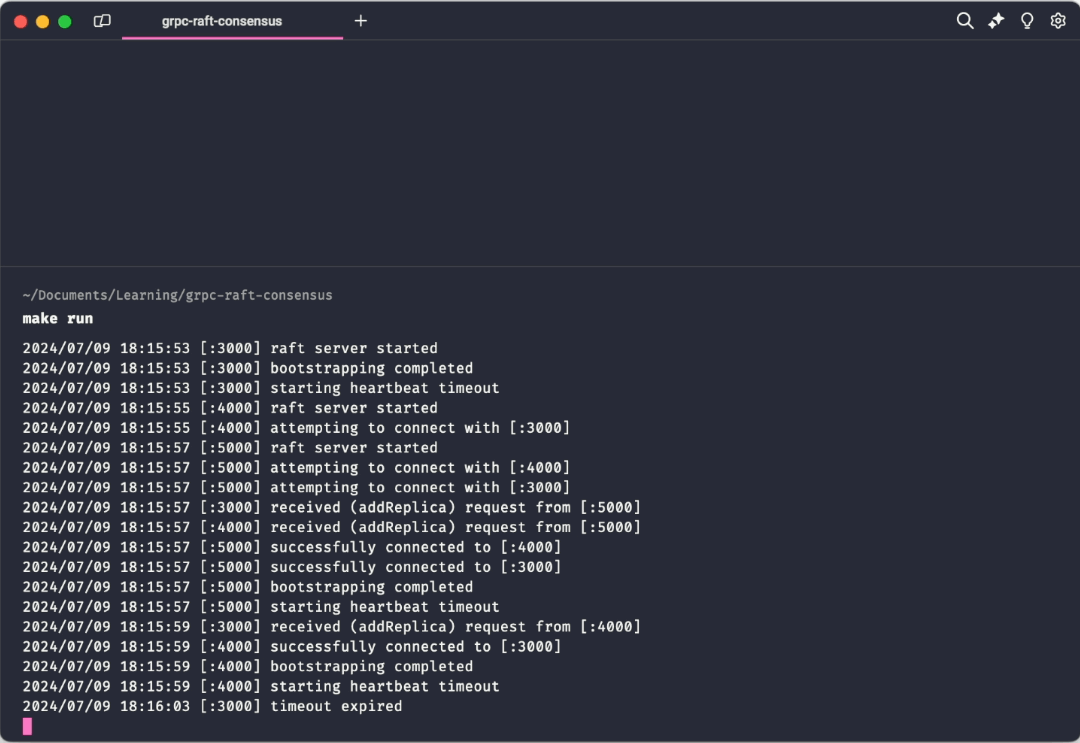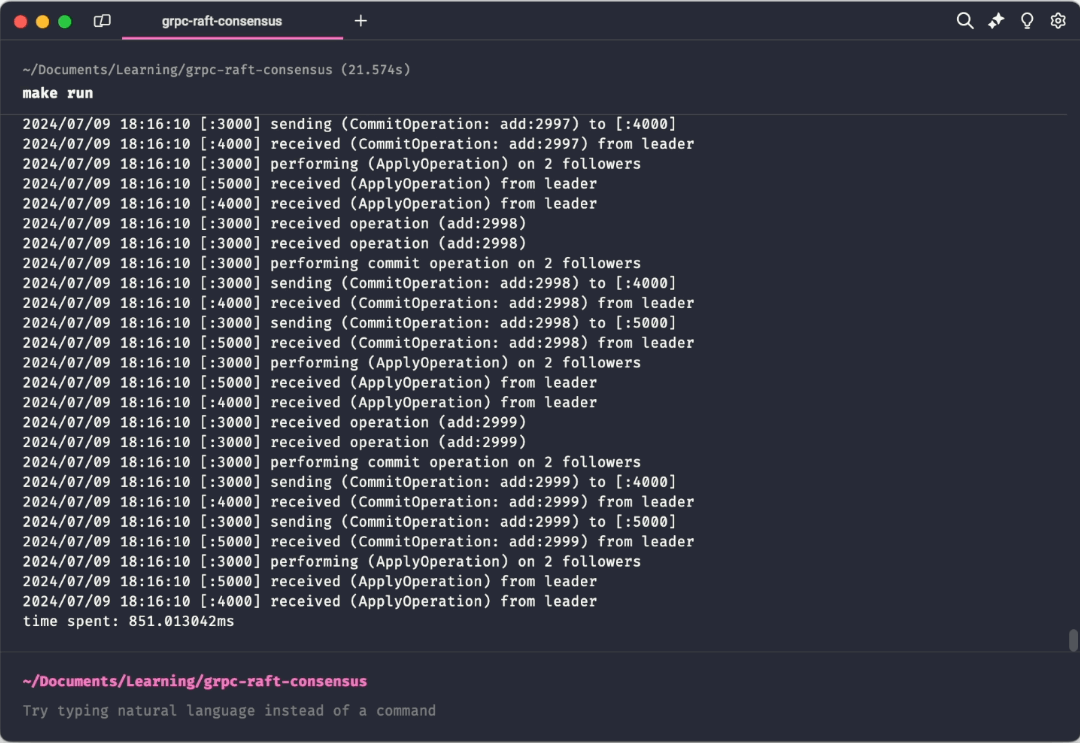
make runThis instantiates three key/value replicas, each with its own associated Raft peer. Initially, each raft replica will assume the role of a follower. Upon a timeout of the heartbeat duration of a replica, it promotes itself to a candidate role and requests votes from other followers. If it receives a quorum of votes, it becomes the leader. The client then sends operations to the cluster which are subsequently directed to the leader node. The leader then ensures that the opreations are replicated across all replicas in the cluster.
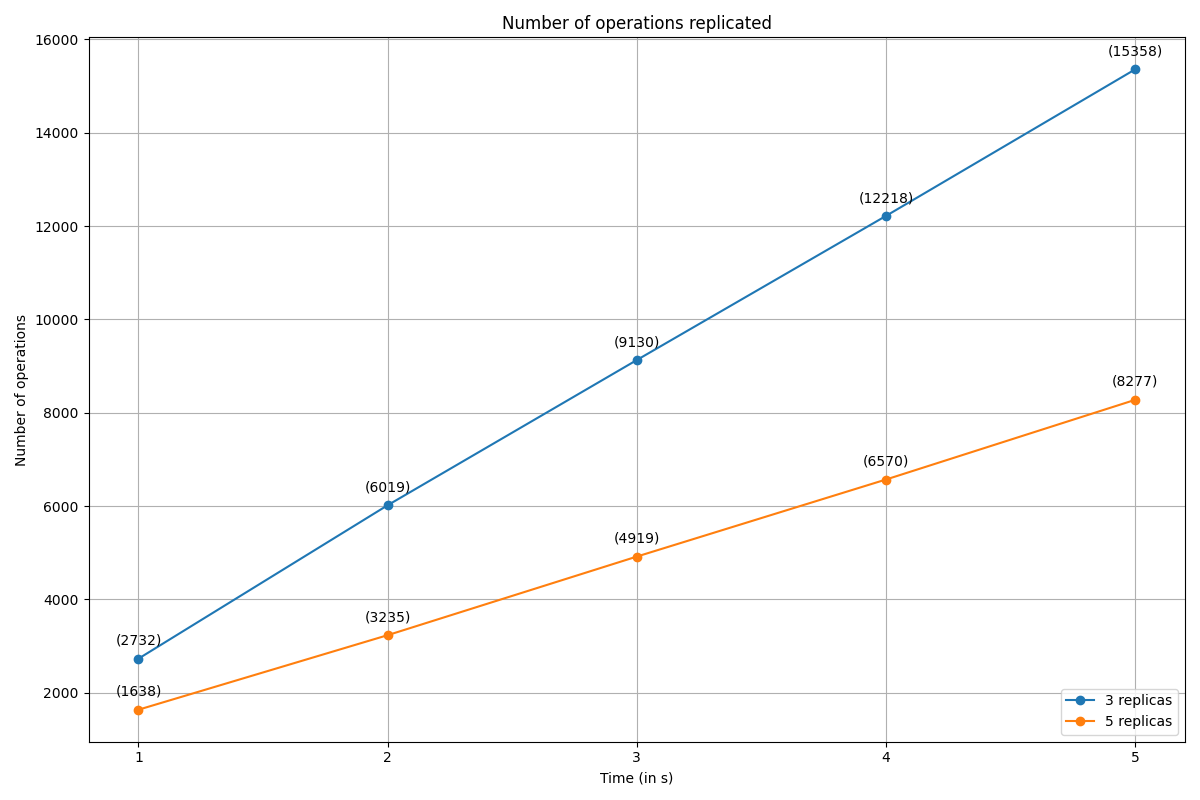
A Raft cluster of 3 nodes can tolerate a single node failure, while a cluster of 5 can tolerate 2 node failures. The recommended configuration is to either run 3 or 5 raft servers. This maximizes availability without greatly sacrificing performance. So, the performance of clusters with 3 and 5 raft servers were recorded. The Apple M1 processor was used for this experiment and the observations were as follows
raft is based on "Raft: In Search of an Understandable Consensus Algorithm"
A high level overview of the Raft protocol is described below, but for details please read the full Raft paper followed by the raft source.
Raft nodes are always in one of three states: follower, candidate or leader. All nodes initially start out as a follower. In this state, nodes can accept log entries from a leader and cast votes. If no entries are received for some time, nodes self-promote to the candidate state. In the candidate state nodes request votes from their peers. If a candidate receives a quorum of votes, then it is promoted to a leader. The leader must accept new log entries and replicate to all the other followers. In addition, if stale reads are not acceptable, all queries must also be performed on the leader.
Once a cluster has a leader, it is able to accept new log entries. A client can request that a leader append a new log entry, which is an opaque binary blob to Raft. The leader then writes the entry to durable storage and attempts to replicate to a quorum of followers. Once the log entry is considered committed, it can be applied to a finite state machine. The finite state machine is application specific, and is implemented using an interface.
In terms of performance, Raft is comparable to Paxos. Assuming stable leadership, committing a log entry requires a single round trip to half of the cluster. Thus performance is bound by disk I/O and network latency.
Usage is provided under the MIT License. See LICENSE for the full details.