Welcome to Thoth's adviser repository.
This repository provides sources for a component called "thoth-adviser" which serves the following purposes:
- Recommendation engine for project Thoth.
- A tool called "Dependency Monkey" that can generate all the possible software stacks for a project respecting dependency resolution in the Python ecosystem following programmable rules.
- Check provenance of installed Python artifacts based on package source indexes used.
If you would like to interact with Thoth from user's perspective, check Thamos repository.
If you would like to browse technical documentation, visit thoth-adviser section at thoth-station.ninja.

The software stack generation is shared for Dependency Monkey as well as for the recommendation engine. The core principle of the software stack generation lies in an abstraction called "software stack resolution pipeline". This pipeline is made out of multiple units of different type that form atomic pieces to score packages that can occur in a software stack based on the dependency resolution.
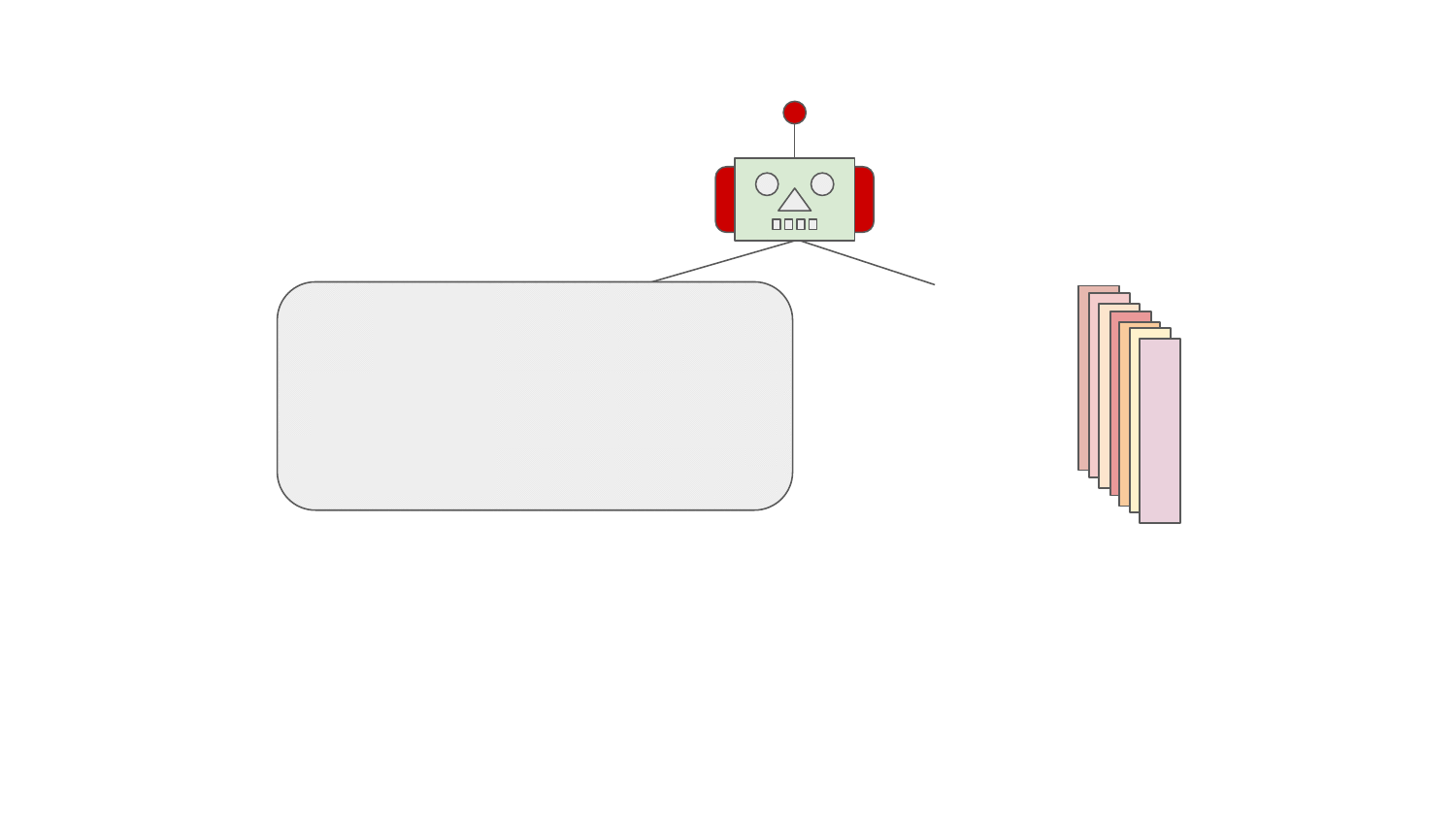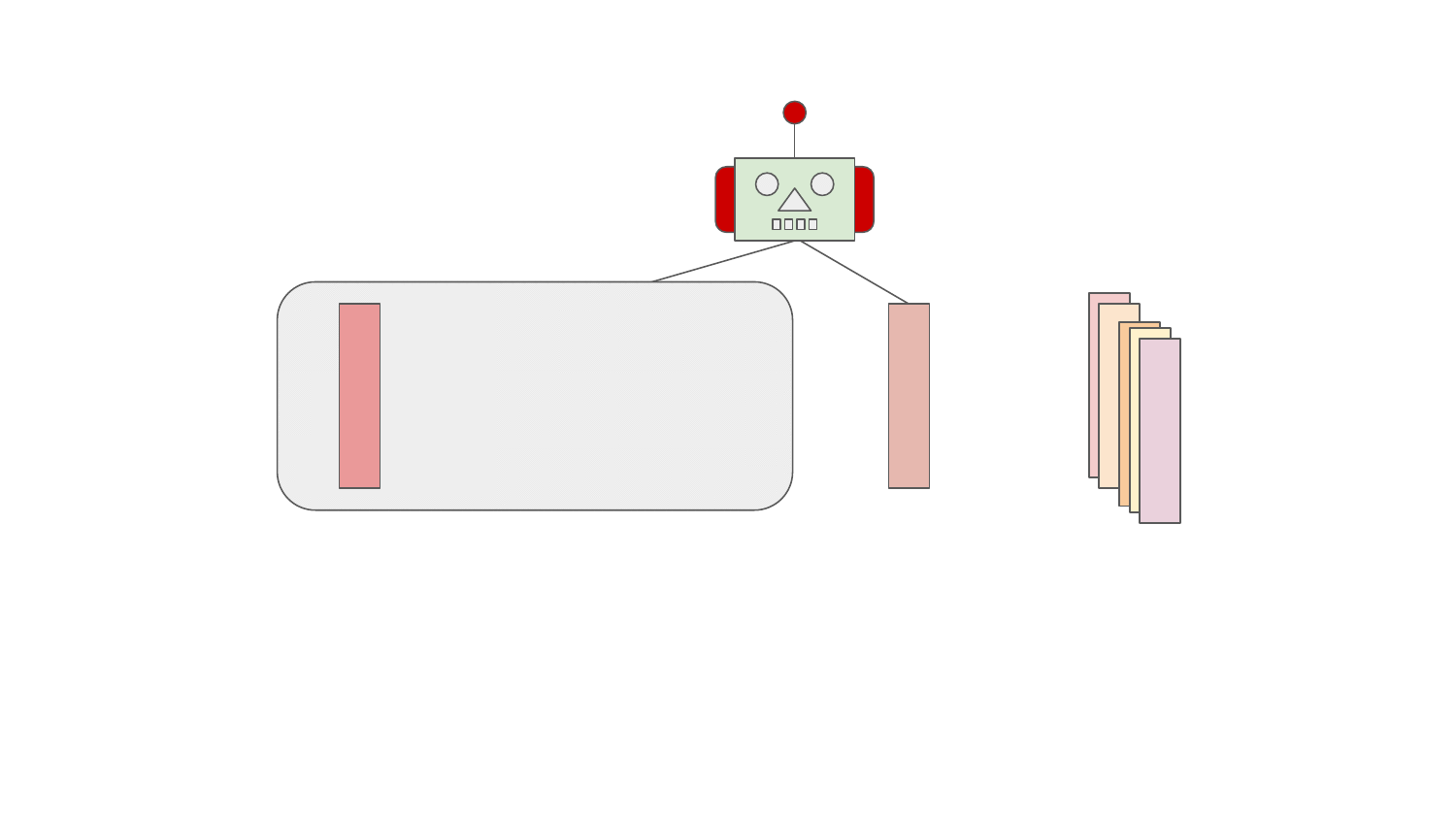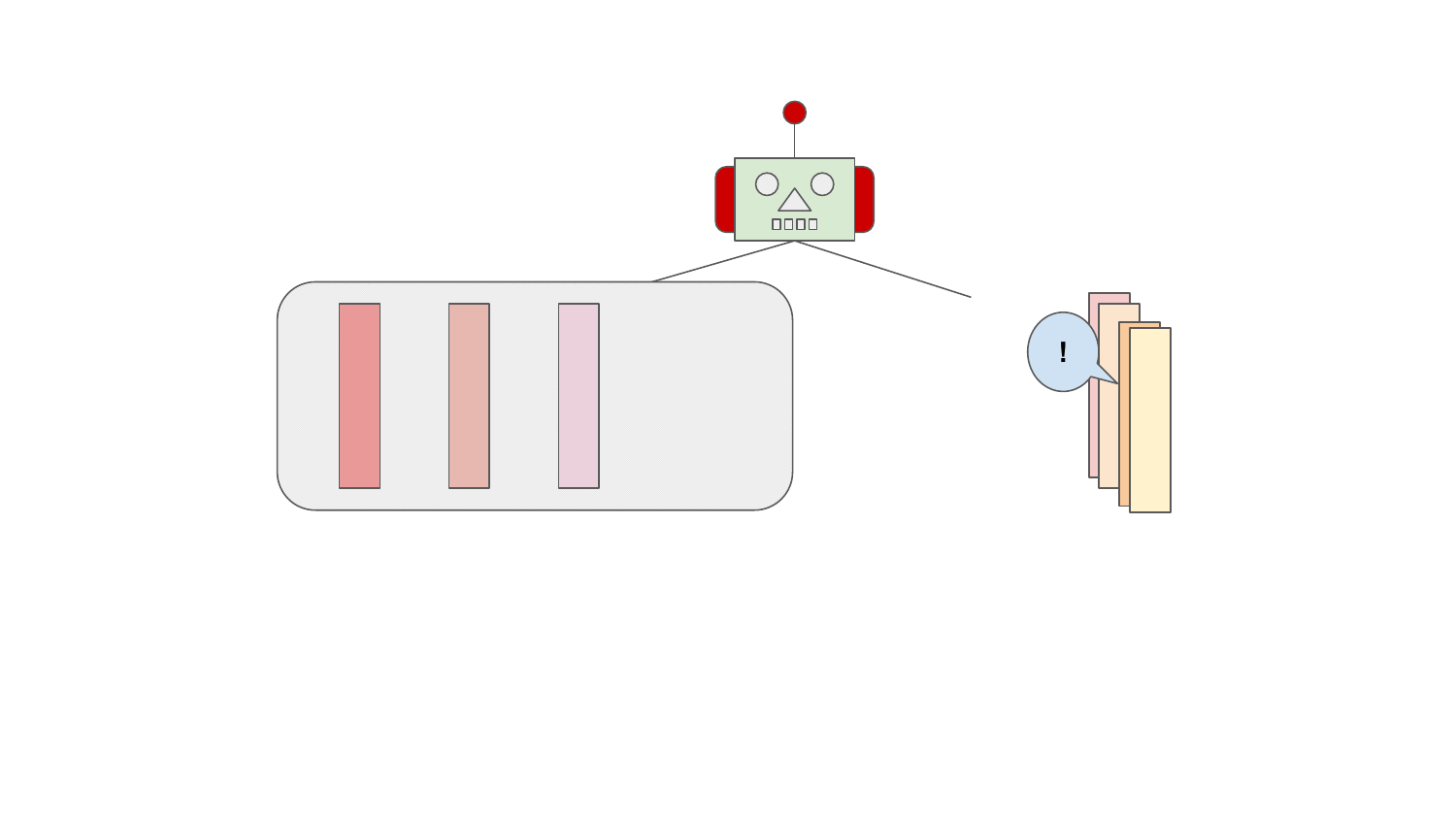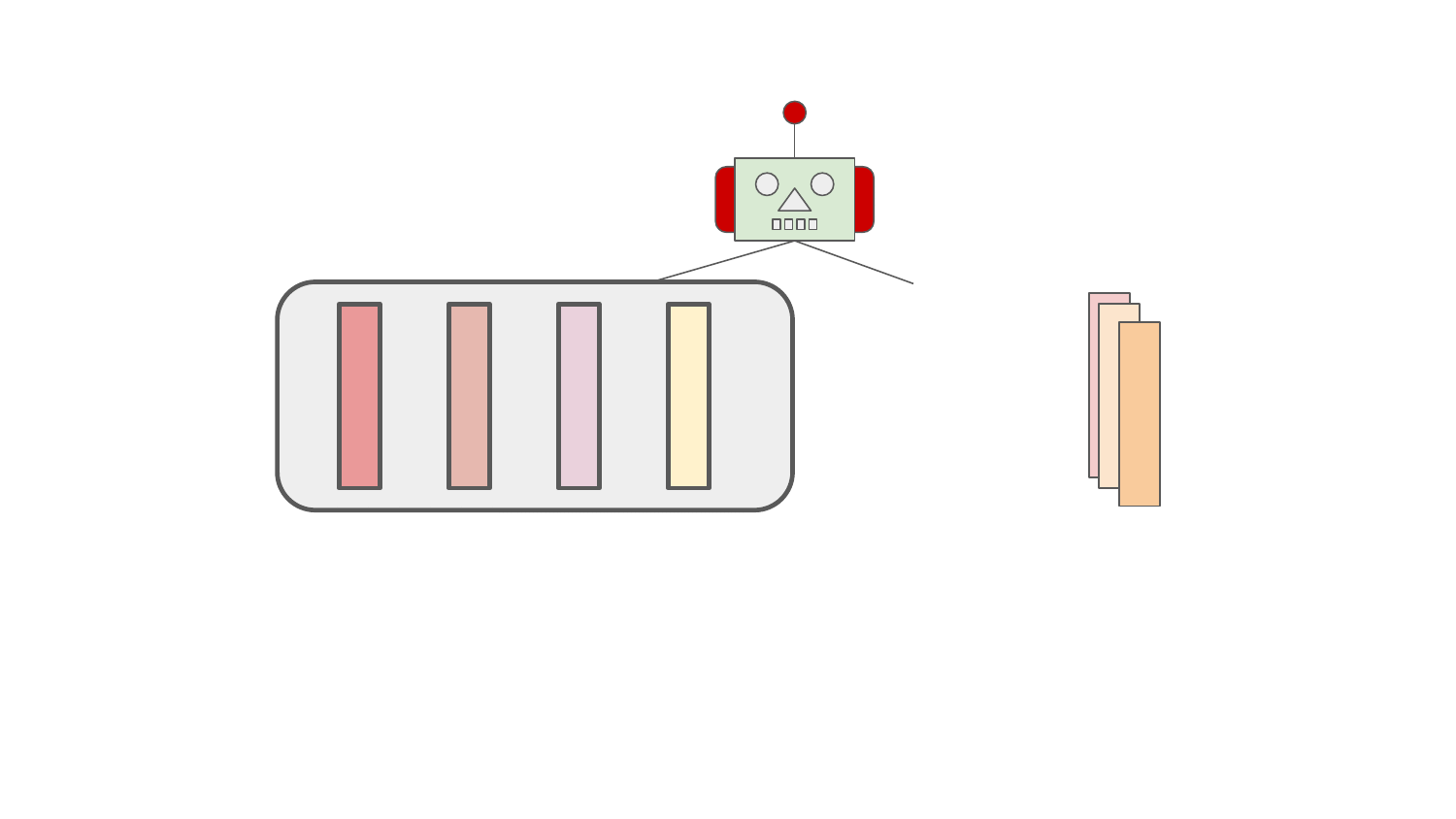
As can be seen in the animation shown above, the pipeline units that form the software stack resolution pipeline are included in the pipeline dynamically on the pipeline creation. A set of units included form a pipeline configuration.
The pipeline configuration is built by "pipeline builder" which asks each pipeline unit for inclusion in the pipeline configuration. Each pipeline unit can decide when and whether it should be included in the pipeline configuration considering aspects for the user software stacks, such as:
- hardware available in the runtime environment when running the application (e.g. CPU, GPU)
- operating system and it's version used in the runtime environment where the application is supposed to be run
- software provided by the operating system, such as Python interpreter version, CUDA version (for GPU computation) and other native dependencies (e.g. glibc version, Intel MKL libraries, ...) and their ABI
- user's intention with the software built - e.g. building a computational intensive application, an application which should be secure for production environments, latest-greatest software, ...
- type of inspections for the software quality checks - Dependency Monkey scenario
- ...
All these vectors stated above form a "context" for pipeline builder (the robot in the animation) that creates the pipeline configuration (a set of pipeline units).
See also:
- dev.to: How to beat Python’s pip: Software stack resolution pipelines
- YouTube: Pipeline units in a software stack resolution process
- Jupyter Notebook: Pipeline units in a software stack resolution process
Once the pipeline configuration is constructed, it is used to resolve software stacks meeting desired quality and purpose.
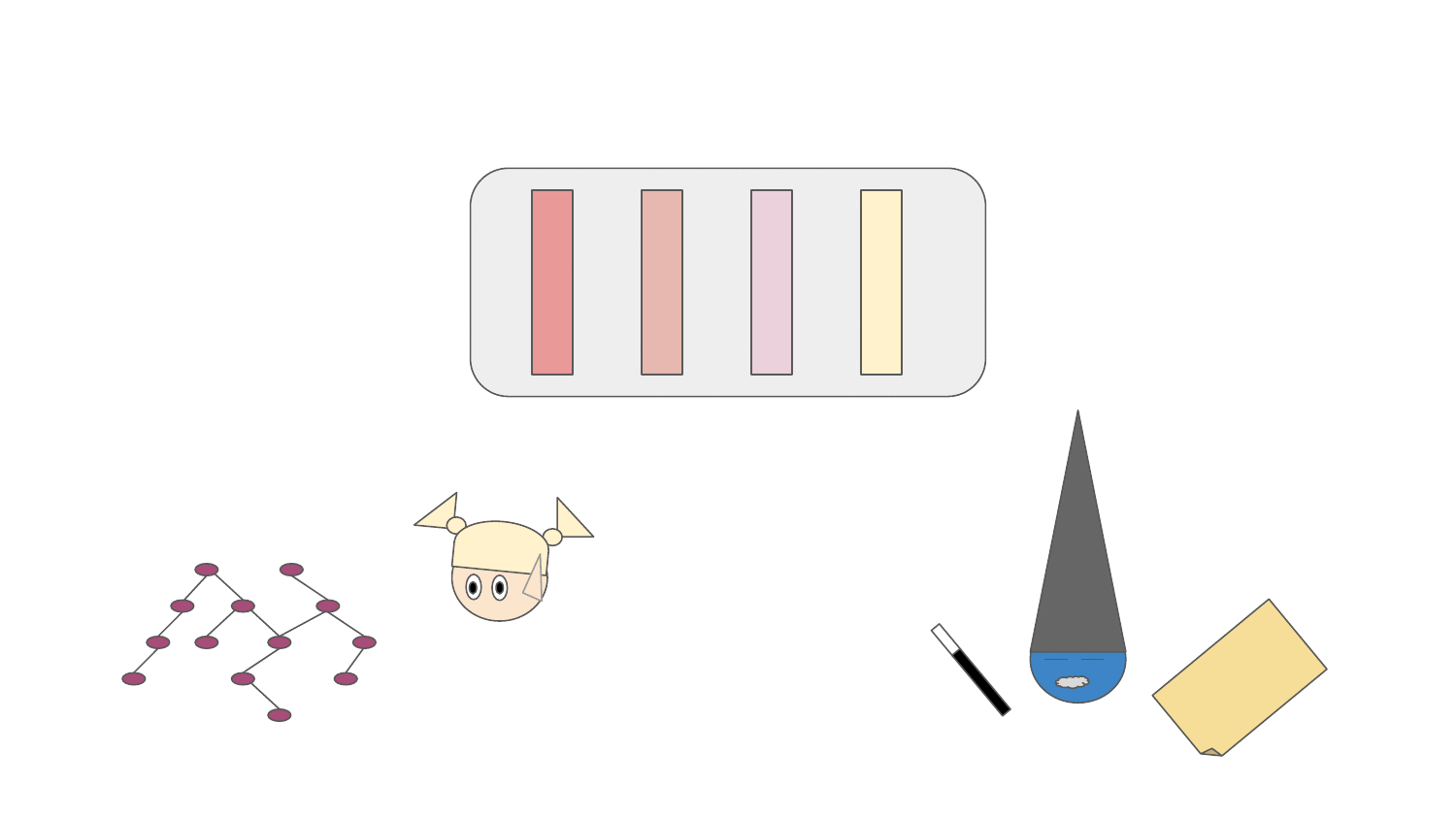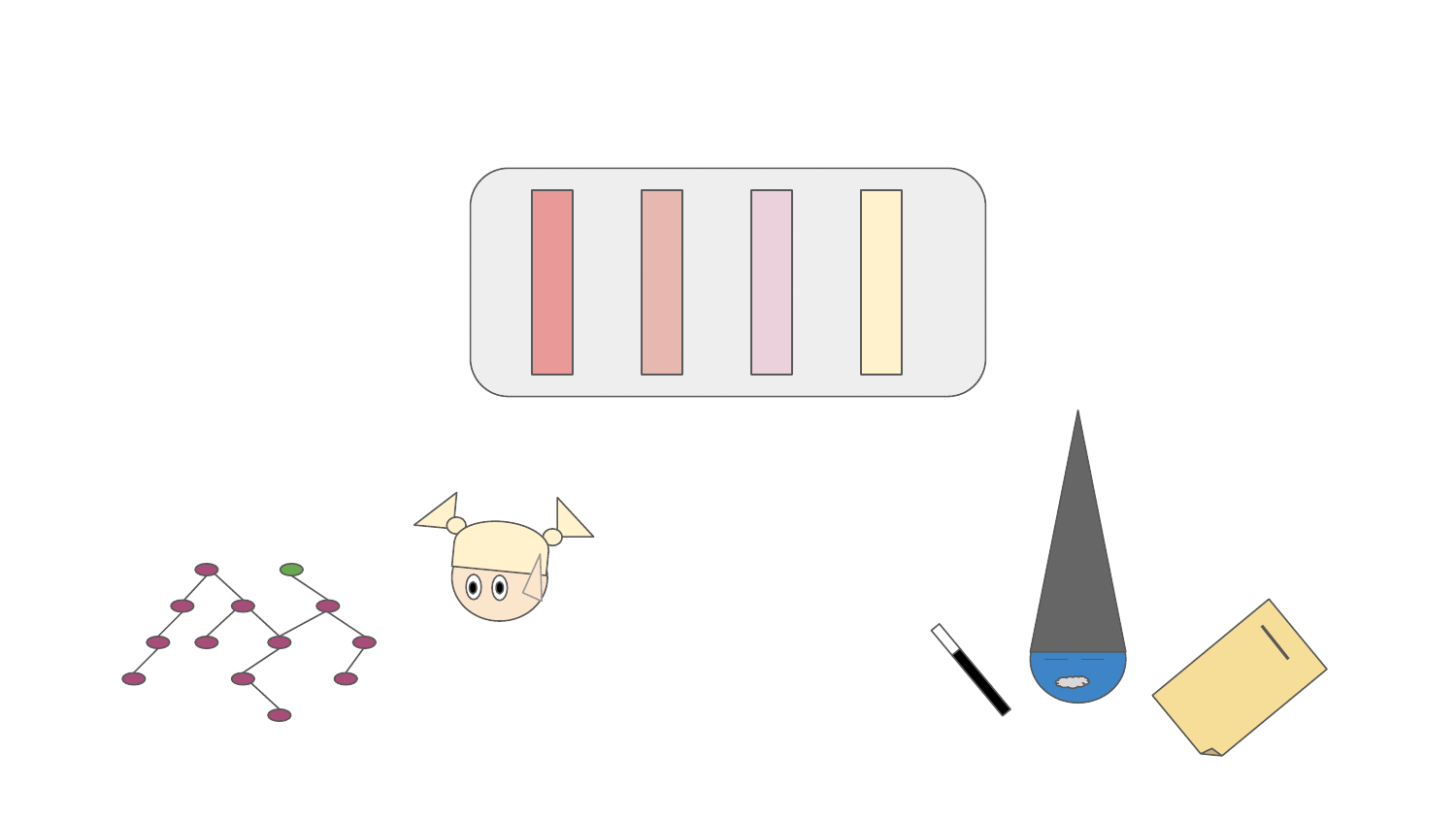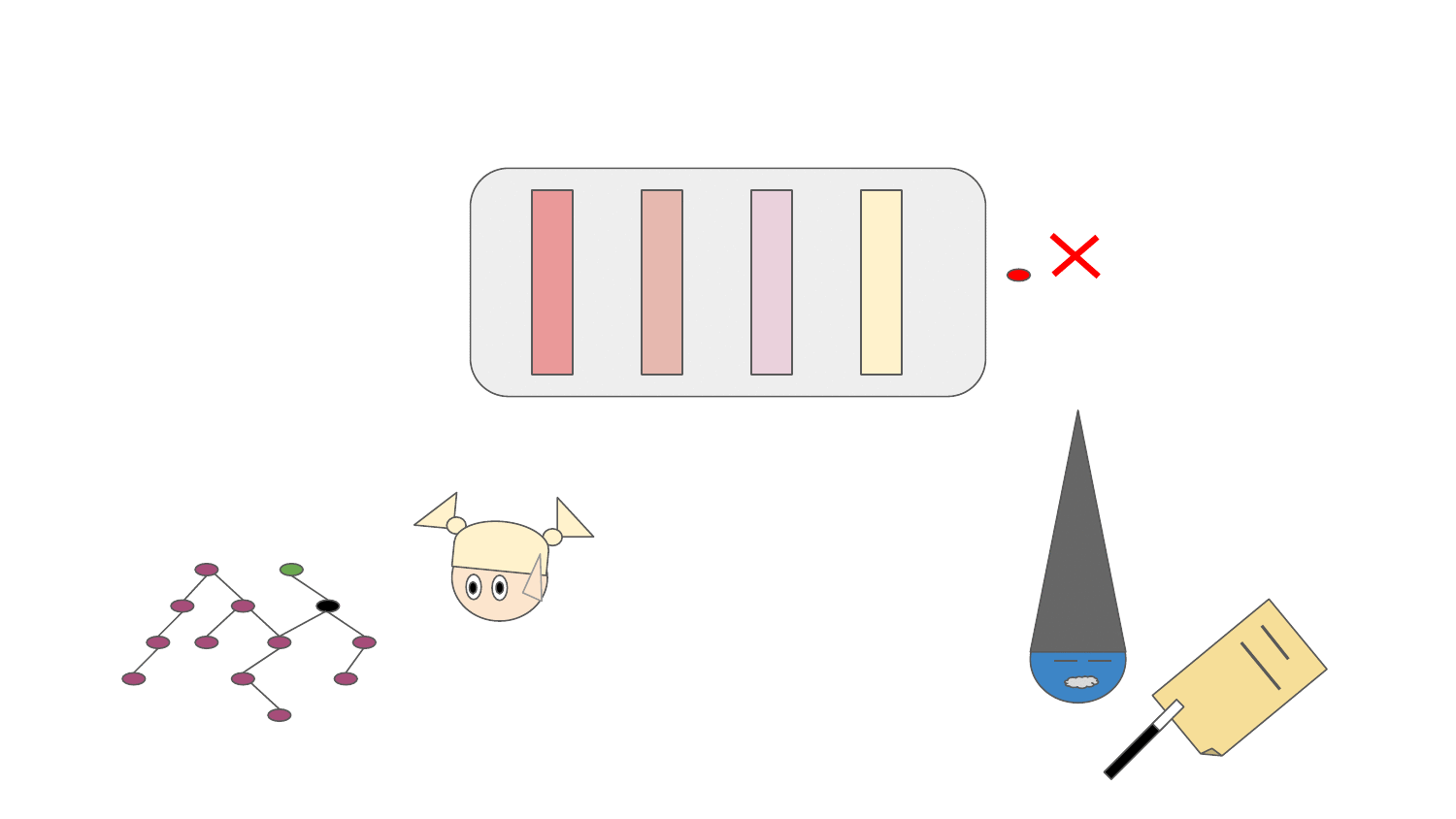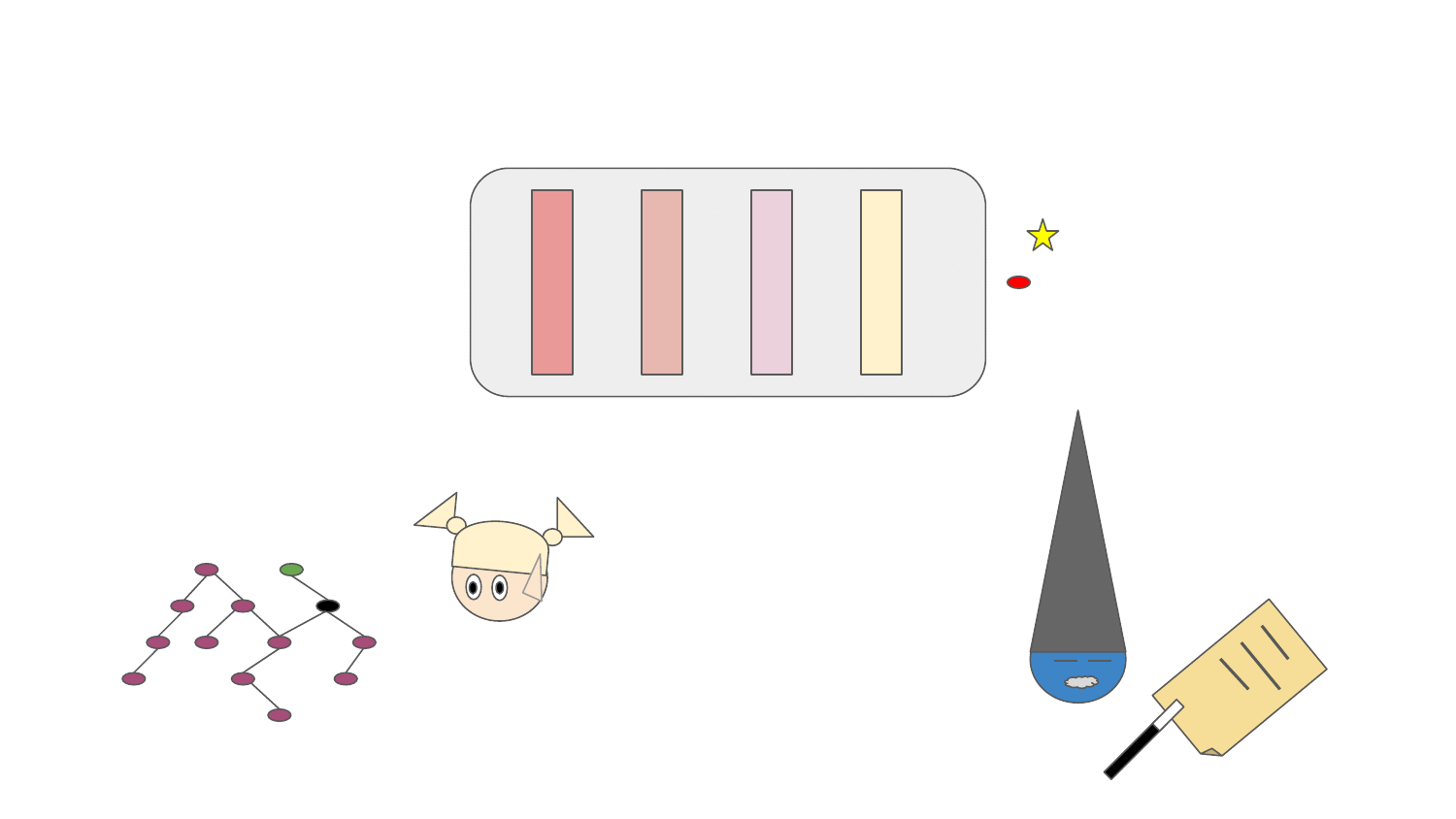
Resolver (the fairy in the animation) can resolve and walk through the dependency graph respecting Python packaging based on the pre-aggregated data from dependency solver runs. The resolution process is guided by an abstraction called "Predictor" (shown as a magician in the animation). Predictor decides which packages in the dependency graph should be resolved by Resolver and thus be included in the resulting software stacks. Packages that are resolved go through the software stack resolution pipeline which scores packages (positively, negatively or completely discard a package from a software stack resolved). The resolution pipeline can:
- inject new packages or new package versions to the dependency graph based on packages resolved (e.g. a package accidentally not stated as a dependency of a library, dependency underpinning issues, ...)
- remove a dependency in a specific version or the whole dependency from the dependency graph (e.g. a package accidentally stated a a dependency, missing ABI symbols in the runtime environment, dependency overpinning issues, ...)
- score a package occurring in the dependency graph positively - prioritize resolution of a specific package in the dependency graph (e.g. positive performance aspect of a package in a specific version/build)
- score a package in a specific version occurring in the dependency graph negatively - prioritize resolution of other versions (e.g. a security vulnerability present in a specific release)
- prevent resolving a specific package in a specific version so that resolver tries to find a different resolution path, if any (e.g. buggy package releases)
The pipeline units present in the pipeline configuration can take into account "context" as stated above - pipeline units can take into account characteristics of the runtime environment used (software and hardware available), purpose of the application, ...
Pipeline units are of different types - Boots, Pseudonyms, Sieves, Steps, Strides and Wraps. Follow the online documentation for more info.
Predictor can be switched and the type of predictor can help with the desired resolution process. For recommending high quality software stacks, reinforcement learning algorithms, such as MCTS or TD-learning are used.
See also:
- dev.to: How to beat Python’s pip: Reinforcement learning-based dependency resolution
- YouTube: Reinforcement learning-based dependency resolution
The whole resolution process can be modeled as a Markov Decision Process (MDP) thus the reinforcement learning (RL) principles stated above can apply. Recommending the best possible set of packages than corresponds to solving the given MDP. See Thoth's documentation for more info.
To obey terms often used in the reinforcement learning terminology, Predictor can be seen as an agent. Resolver and Software stack resolution pipeline can be seen as entities that interact with the environment. Names used in Thoth intentionally do not correspond to RL terminology as RL based resolution is just one of the possible resolutions that can be implemented (others can be hill-climbing, random walks in the dependency graph, ...).
See also:
- dev.to: How to beat Python’s pip: Reinforcement learning-based dependency resolution
- YouTube: Reinforcement learning-based dependency resolution
See the following article for in-depth explanation with a video.
The primary use-case for Dependency Monkey is to generate software stacks that are subsequently validated and scored in the Amun service. Simply, when generating all the possible software stacks, we can find the best software stack for an application by validating it in a CI (or Amun in case of Thoth), running the application in the specific runtime environment (e.g. Fedora 33 with installed native packages - RPMs) on some specific hardware configuration. Generating and scoring all the possible software stacks is, however, most often not doable in a reasonable time. For this purpose, Dependency Monkey can create a sample of software stacks that can be taken as representatives. These representatives are scored and aggregated data are used for predicting the best application stack (again, generated and run through CI/Amun to make predictions more accurate by learning over time).
See Dependency Monkey documentation for more info.
See also:
- Resolve Python dependencies with Thoth Dependency Monkey
- Developers Red Hat: AI software stack inspection with Thoth and TensorFlow
- dev.to: How to beat Python’s pip: Inspecting the quality of machine learning software
- YouTube: Thoth Amun API: Inspecting the quality of software
- dev.to: How to beat Python’s pip: Dependency Monkey inspecting the quality of TensorFlow dependencies
- YouTube: Dependency Monkey inspecting Python dependencies of TensorFlow
In Thoth's terminology, advises and recommendations are the same. Based on the aggregated knowledge stored in the database, provide the best application stack with reasoning on why the given software stack is used. Pipeline units present in the pipeline configuration score packages resolved and provide such reasoning. The reasoning is called "justification" in Thoth's terminology. See Thoth's pages to see some of them.
As Thoth aggregates information about packages available, it can verify a user's stack against its knowledge base. See Provenance Checks for more info.
Adviser is built using OpenShift Source-to-Image and deployed automatically with Thoth's deployment available in the thoth-station/thoth-application repository.
In a Thoth deployment, adviser is run based on requests coming to the user API - each deployed adviser is run per a user request. You can run adviser locally as well by installing it and using its command line interface:
pip3 install thoth-adviser thoth-adviser --help # Or use git repo directly for the latest code: # pip3 install git+https://github.com/thoth-station/adviser
Note a database needs to be available. See thoth-storages repository on how to run Thoth's knowledge graph locally and example notebooks with experiments.
When thoth-adviser is scheduled in a deployment, it is actually executed as a CLI with arguments passed via environment variables.
Adviser also considers environment variable THOTH_ADVISER_BLOCKED_UNITS that
states a comma separated list of pipeline units that should not be added to
the pipeline. This can be handy if an issue with a unit arises in a deployment
- Thoth operator can remove pipeline unit by adjusting environment variable in
the adviser deployment manifest and provide this configuration without a need
to deploy a new version of adviser.
For prod-like deployments, you can disable pipeline unit validation. By doing
so, the pipeline unit configuration can be constructed faster. Provide
THOTH_ADVISER_VALIDATE_UNIT_CONFIGURATION_SCHEMA=0 environment variable to
disable pipeline unit configuration validation.
Often, it is useful to run adviser locally to experiment or verify your changes in implementation. You can do so easily by running:
pipenv install --dev
PYTHONPATH=. pipenv run ./thoth-adviser --helpThis command will run adviser locally - adviser will try to connect to a local PostgreSQL instance and compute recommendations. Browse docs here to see how to setup a local PostgreSQL instance. Also, follow the developer's guide to get more information about developer's setup.