
日本人用顔認証学習モデル
- ここに置いてある学習モデルについて。
- 日本人の顔認証を目的としています。
- 無料でお使いいただけます。ご使用時に著作権表示をして下さい。
- 商用利用されたい場合はライセンスが必要です。
顔認識技術は、スマートフォンのロック解除から空港のシステムまで、私たちの生活のあらゆる面で使用されています。しかしOSSの既存顔認識モデルであるDlibのdlib_face_recognition_resnet_model_v1.datは、白人の顔に対する精度は高いものの、それ以外の人種、とくに若年日本人女性の顔に対する精度が低いという問題があります。
Dlibは、元々はC++で書かれた機械学習とデータ解析のためのオープンソースライブラリです。2002年にDavis Kingによって開発が始まりました。Dlibは、顔認証の分野でよく知られていますが、その機能はそれだけにとどまりません。このライブラリは、画像処理、機械学習、自然言語処理、数値最適化といった多様なタスクに対応しています。C++で開発された本ライブラリはPythonバインディングも提供しています。dlib(GitHub)で、現在も開発が続けられています。
このモデルは、ResNetベースの深層学習モデルで、非常に高い精度で顔認証が可能です。2017年に提供が開始されました。 Labeled Faces in the Wild (LFW) データセットでの精度は99.38%と報告されています。このような高い精度が、Dlibとその顔認証モデルが広く採用される一因です。
しかしこのモデルは白人に対する精度は高いものの、それ以外の人種、とくに若年日本人女性に対する精度は低いという問題がありました。そのため、これまでは認識精度を向上させるためにしきい値を調整するなどの対策が必要でした。またしきい値を調整してもなおFalse Positive (偽陽性)が一定値存在する問題が残っていました。

Dlibが偽陽性を出す例
そこで、日本人の顔データセットを使用して新たな顔認識モデルを開発することにしました。
結果として新たに開発した学習モデルは26MBと、既存のdlibモデル(22.5MB)よりわずかに大きいサイズとなりましたが、同等の計算リソースでより高精度な日本人の顔認証が可能となりました。
大規模な画像データセットであるImageNetで事前学習されたEfficientNetV2を、ArcFaceを使い、日本人の顔データセットでファインチューニングしました。
これにより、特徴空間での分離を改善し、日本人の顔認識精度を大幅に向上できました。
- EfficientNetV2: Smaller Models and Faster Training
- ArcFace: Additive Angular Margin Loss for Deep Face Recognition
- pytorch-image-models
UMAPによる可視化結果

これら顔学習モデルの性能を比較・評価するために、以下の検証を行いました。なお、使用する顔データセットは、JAPANESE FACE v1の作成に使用したデータセットには含まれていません。
著名日本人の顔画像データベースから、ランダムに300枚の画像を選択し、一般日本人の顔画像データセットを作成しました。このデータセットに対して、dlib_face_recognition_resnet_model_v1.datを用いて顔認証を行い、ROC-AUCを計算しました。その結果が以下になります。

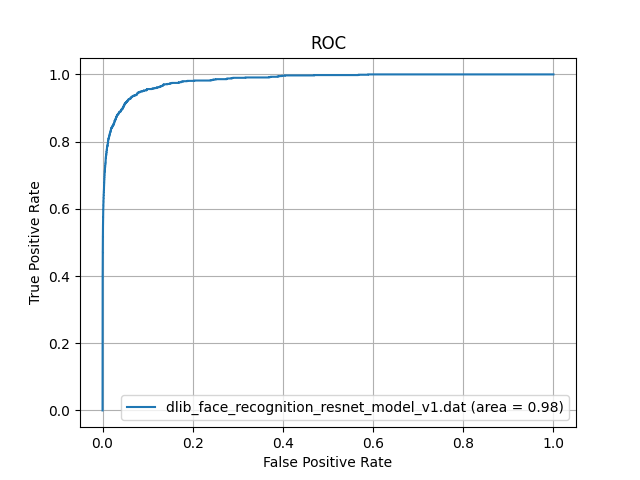 一般日本人に対して、
一般日本人に対して、dlib_face_recognition_resnet_model_v1.datのAUCは0.98であり、非常に高い精度を示しています。
今度は、著名日本人の顔画像データベースから、とくに若年女性の顔画像をランダムに300枚選択し、若年日本人女性の顔画像データセットを作成しました。このデータセットに対して、dlib_face_recognition_resnet_model_v1.datを用いて顔認証を行い、ROC-AUCを計算しました。その結果が以下になります。

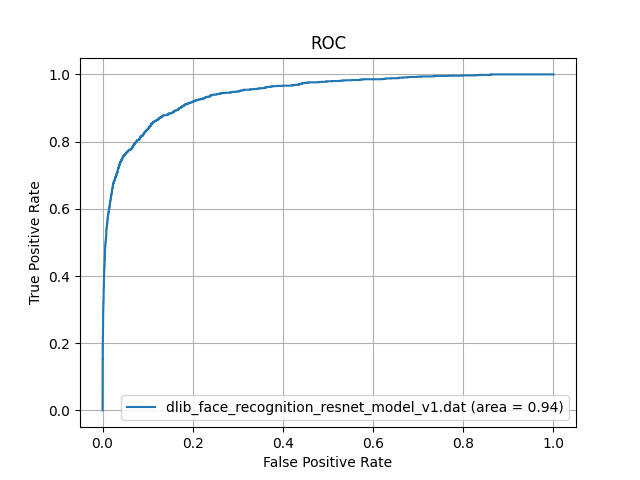 一般日本人に対して、若年日本人女性の顔画像を用いて性能評価をしたところ、AUCが0.98から0.94に低下しました。
これはDlibの顔学習モデルが、face scrub datasetやVGGデータセットを主に使用しているところが原因と考えられます。これらのデータセットには、若年日本人女性の顔画像がほとんど含まれていないため、若年日本人女性の顔画像に対しては、性能が低下すると考えられます。(High Quality Face Recognition with Deep Metric Learningを参照)
一般日本人に対して、若年日本人女性の顔画像を用いて性能評価をしたところ、AUCが0.98から0.94に低下しました。
これはDlibの顔学習モデルが、face scrub datasetやVGGデータセットを主に使用しているところが原因と考えられます。これらのデータセットには、若年日本人女性の顔画像がほとんど含まれていないため、若年日本人女性の顔画像に対しては、性能が低下すると考えられます。(High Quality Face Recognition with Deep Metric Learningを参照)
この問題を解決するため、独自の日本人顔データセットを用いて学習したモデルがJAPANESE FACE v1です。このモデルはEfficientNetV2にArcFaceLossを適用して作成されました。作成の詳細は、日本人顔認識のための新たな学習モデルを作成 ~ EfficientNetV2ファインチューニング ~という記事で詳しく解説しています。
このモデルを使って、Dlibの学習モデルと比較した結果を以下に示します。
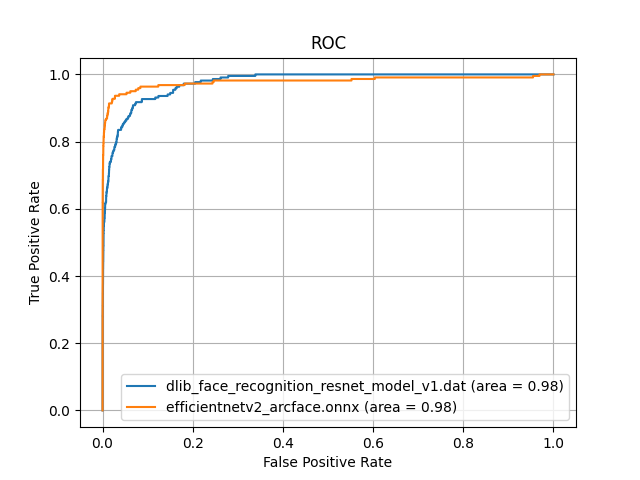 Dlibの学習モデルと比較して、AUCが0.98であり、同等の性能を示しています。ROC曲線をみると、
Dlibの学習モデルと比較して、AUCが0.98であり、同等の性能を示しています。ROC曲線をみると、JAPANESE FACE v1の方がdlibよりも、左上の部分が凸となっており、性能が高いことがわかります。
 若年日本人女性の顔画像に対しては、DlibのAUCが0.94に対し、
若年日本人女性の顔画像に対しては、DlibのAUCが0.94に対し、JAPANESE FACE v1は0.98を維持しています。
続いてF1-scoreを比較します。こちらは若年日本人女性のデータセットのみを比較します。
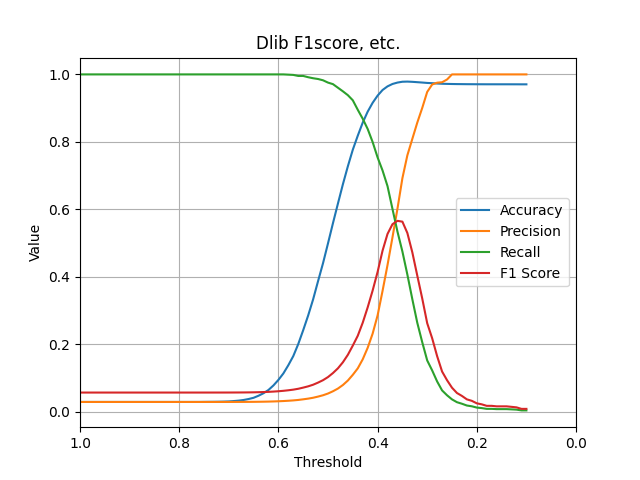 Dlibのブログでは「The network training started with randomly initialized weights and used a structured metric loss that tries to project all the identities into non-overlapping balls of radius 0.6.」と書いてあるとおり、閾値を0.6としています。しかし、若年日本人女性のデータセットを対象とした場合、0.35が最適な閾値ということが、グラフから分かります。
この場合でも、F1-scoreは0.55程度の、あまり高い値とは言えない結果となりました。
Dlibのブログでは「The network training started with randomly initialized weights and used a structured metric loss that tries to project all the identities into non-overlapping balls of radius 0.6.」と書いてあるとおり、閾値を0.6としています。しかし、若年日本人女性のデータセットを対象とした場合、0.35が最適な閾値ということが、グラフから分かります。
この場合でも、F1-scoreは0.55程度の、あまり高い値とは言えない結果となりました。
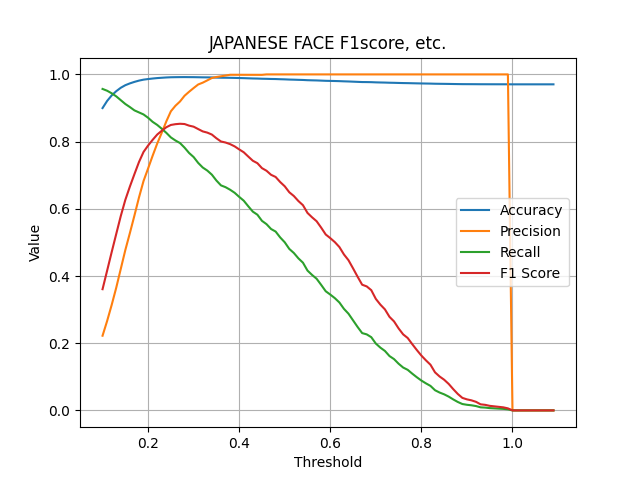 こちらのモデルでは、F1-scoreが0.8を超えています。これは、
こちらのモデルでは、F1-scoreが0.8を超えています。これは、JAPANESE FACE v1が若年日本人女性のデータセットを用いて学習されているため、高い精度が出ていると考えられます。
https://github.com/yKesamaru/FACE01_SAMPLE
上記URLからFACE01をインストールしてください。
setup.pyによる一括インストールや、Dockerでの使用ができます。
インストールが終わったら、以下のコードを実行してください。
# 仮想環境のアクティベート
$ source ./bin/activate
# Exampleコードの実行
$ python example/simple_efficientnetv2_arcface.pydlib_face_recognition_resnet_model_v1.datを用いた場合全て同一人物と判断されてしまう例 (不正解) を、新しく作成した学習モデルで検証しました。新しいモデルでは全て別人と判断 (正解) されました。
import glob
import os
import sys
from itertools import combinations
import numpy as np
sys.path.append('FACE01')
from face01lib.Calc import Cal
from face01lib.utils import Utils
Utils_obj = Utils()
Cal_obj = Cal()
# 画像の読み込みと類似度の計算
image_dir = "predict_test"
# 画像ファイルのパスを取得
image_paths = glob.glob(os.path.join(image_dir, "*.png"))
embeddings = []
for image_path in image_paths:
embedding = Utils_obj.get_face_encoding(image_path)
embeddings.append(embedding)
# 類似度の計算
pairs = list(combinations(range(len(embeddings)), 2))
for i, j in pairs:
distance = np.linalg.norm(embeddings[i] - embeddings[j])
percent = round(Cal_obj.to_percentage(distance), 2)
print(f'{image_paths[i]}, {image_paths[j]}, {percent}%')- 新井浩文, 大森南朋

- 新しい学習モデル (
efficientnetv2_arcface.onnx)predict_test/新井浩文.png_align_resize.png, predict_test/大森南朋.png_align_resize.png, False, 87.98%- 判定; 別人 (正解:o:)
- 既存の学習モデル (
dlib_face_recognition_resnet_model_v1.dat)predict_test/新井浩文.png_align_resize.png, predict_test/大森南朋.png_align_resize.png, 98.97%- 判定: 同一人物 (不正解:x:)

- 新川優愛, 内田理央

- 新しい学習モデル (
efficientnetv2_arcface.onnx)predict_test/新川優愛.png, predict_test/内田理央.png, False, 81.46%- 判定; 別人 (正解:o:)
- 既存の学習モデル (
dlib_face_recognition_resnet_model_v1.dat)predict_test/内田理央.png_align_resize.png, predict_test/新川優愛.png_align_resize.png, 99.27%- 判定: 同一人物 (不正解:x:)

- 金正恩, 馬場園梓

- 新しい学習モデル (
efficientnetv2_arcface.onnx)predict_test/金正恩.png_align_resize.png, predict_test/馬場園梓.png_align_resize.png, False, 79.87%- 判定; 別人 (正解:o:)
- 既存の学習モデル (
dlib_face_recognition_resnet_model_v1.dat)predict_test/金正恩.png_align_resize.png, predict_test/馬場園梓.png_align_resize.png, 99.44%- 判定: 同一人物 (不正解:x:)

- 池田清彦, 西村康稔

- 新しい学習モデル (
efficientnetv2_arcface.onnx)predict_test/池田清彦.png_align_resize.png, predict_test/西村康稔.png_align_resize.png, False, 72.26%- 判定; 別人 (正解:o:)
- 既存の学習モデル (
dlib_face_recognition_resnet_model_v1.dat)predict_test/池田清彦.png_align_resize.png, predict_test/西村康稔.png_align_resize.png, 98.87%- 判定: 同一人物 (不正解:x:)

- 金正恩, 畑岡奈紗

- 新しい学習モデル (
efficientnetv2_arcface.onnx)predict_test/金正恩.png_align_resize.png, predict_test/畑岡奈紗.png_align_resize.png, False, 77.82%- 判定; 別人 (正解:o:)
- 既存の学習モデル (
dlib_face_recognition_resnet_model_v1.dat)predict_test/金正恩.png_align_resize.png, predict_test/畑岡奈紗.png_align_resize.png, 99.37%- 判定: 同一人物 (不正解:x:)

- 有働由美子, 椎名林檎

- 新しい学習モデル (
efficientnetv2_arcface.onnx)predict_test/有働由美子.png_align_resize.png, predict_test/椎名林檎.png_align_resize.png, False, 82.17%- 判定; 別人 (正解:o:)
- 既存の学習モデル (
dlib_face_recognition_resnet_model_v1.dat) -predict_test/有働由美子.png_align_resize.png, predict_test/椎名林檎.png_align_resize.png, 99.16%- 判定: 同一人物 (不正解:x:)

- 波瑠, 入山杏奈

- 新しい学習モデル (
efficientnetv2_arcface.onnx)predict_test/波瑠.png_align_resize.png, predict_test/入山杏奈.png_align_resize.png, False, 81.46%- 判定; 別人 (正解:o:)
- 既存の学習モデル (
dlib_face_recognition_resnet_model_v1.dat)predict_test/波瑠.png_align_resize.png, predict_test/入山杏奈.png_align_resize.png, 99.07%- 判定: 同一人物 (不正解:x:)

- 浅田舞, 浅田真央

- 新しい学習モデル (
efficientnetv2_arcface.onnx)predict_test/浅田舞.png_align_resize.png, predict_test/浅田真央.png_align_resize.png, False, 83.06%- 判定; 別人 (正解:o:)
- 既存の学習モデル (
dlib_face_recognition_resnet_model_v1.dat)predict_test/浅田舞.png_align_resize.png, predict_test/浅田真央.png_align_resize.png, 99.27%- 判定: 同一人物 (不正解:x:)

この記事では日本人の顔認識の精度を向上させるために、EfficientNetV2とArcFaceを用いた新たなモデルの開発について説明しました。
この新たなモデルは日本人の顔認識において、既存のモデル( dlib_face_recognition_resnet_model_v1.dat) よりも優れた性能を示しました。これにより顔認識技術がさらに多様なシチュエーションに対応できるようになり、その応用範囲が広がることが期待されます。
- FACE01
- Face recognition library that integrates various functions and can be called from Python.