DenseNet
- 최대한의 정보 흐름을 보장하기 위해서, 모든 layer를 각각 직접 연결
- L(L+1)/2번의 direct connections이 이루어짐
✔️ information preservation
-
ResNet은 identity transformation을 더해서(summation) later layer로부터 early layer로의 gradient flow가 직접 연결된다는 장점이 있지만, identity transformation과 출력 H(x−1)이 summation됨에 따라 information flow를 방해할 수 있다.
-
gradient가 흐르게 된다는 점은 도움이 되지만, forward pass에서 보존되어야 하는 정보들이 summation을 통해 변경되어 보존되지 못할 수 있다는 의미이다. (DenseNet은 concatenation을 통해 그대로 보존)
-
DenseNet은 feature map을 그대로 보존하면서, feature map의 일부를 layer에 concatenation → 네트워크에 더해질 information과 보존되어야 할 information을 분리해서 처리 → information 보존
✔️ improved flow of information and gradient
- 모든 layer가 이전의 다른 layer들과 직접적으로 연결되어 있기 때문에, loss function이나 input signal의 gradient에 직접적으로 접근 가능 + gradient vanishing이 없어짐 → 네트워크를 깊은 구조로 만드는 것이 가능
✔️ regularizing effect
- 많은 connection으로 depth가 짧아지는 효과 → regularization 효과 (overfitting 방지)
- 상대적으로 작은 train set을 이용하여도 overfitting 문제에서 자유로움

Resdual 블록: skip connection을 통해서 전달된 x(identity) mapping을 더함 & 직전 블록의 정보 받음
Dense 블록: channel 축 기준으로 concatenation & 직전 블록/훨씬 이전 블록의 정보도 넘겨받음
resdual 블록에서의 + vs. Dense 블록에서의 concatenation
- summation(+) 연산: 두 신호를 합침
- concatenation 연산: (channel은 늘어나지만) 신호가 보존되어있음. 따라서 하위 정보 이용시 용이

Dense Connectivity


- ResNet은 gradient가 identity function을 통해 직접 earlier layer에서 later layer로 흐를 수 있으나, identity function과 output을 더하는(summation) 과정에서 information flow를 방해할 수 있음 → L번의 connections

- DenseNet은 summation으로 layer 사이를 연결하는 대신에, concatenation으로 layer 사이를 직접 연결 → L(L+1)/2번의 connections ⇒ dense connectivity라서 DenseNet(Dense Convolutional Network)으로 명명

Pooling layers

-
feature map의 크기가 변경될 경우, concatenation 연산을 수행할 수 없음 (∵ 평행하게 합치는 것이 불가능) ↔ CNN은 down-sampling은 필수이므로, layer마다 feature map의 크기가 달라질 수 밖에 없음
-
DenseNet은 네트워크 전체를 몇 개의 dense block으로 나눠서 같은 feature map size를 가지는 레이어들은 같은 dense block내로 묶음
-
위 그림에서는 총 3개의 dense block으로 나눔
-
같은 블럭 내의 레이어들은 전부 같은 feature map size를 가짐 ⇒ concatenation 연산 가능
-
transition layer(빨간 네모를 친 pooling과 convolution 부분) ⇒ down-sampling 가능
- Batch Normalization(BN)
- 1×1 convolution → feature map의 개수(= channel 개수)를 줄임
- 2×2 average pooling → feature map의 가로/세로 크기를 줄임
-
ex. dense block1에서 100x100 size의 feature map을 가지고 있었다면 dense block2에서는 50x50 size의 feature map
-
-
위 그림에서 가장 처음에 사용되는 convolution 연산 → input 이미지의 사이즈를 dense block에 맞게 조절하기 위한 용도로 사용됨 → 이미지의 사이즈에 따라서 사용해도 되고 사용하지 않아도 됨
Bottleneck layers

- output의 feature map 수(= channel 개수)를 조절하는 bottleneck layer를 사용
- 본 논문에서 H()에 bottleneck layer를 사용한 모델을 DenseNet-B로 표기
- Batch Norm → ReLU → Conv (1×1) → Batch Norm → ReLU → Conv (3×3)
- 본 논문에서, 각 1×1 Conv는 4k개의 feature map을 출력 (단, 4 * growth rate의 4배 라는 수치는 hyper-parameter이고 이에 대한 자세한 설명은 하고 있지 않음)
- 1x1 convolution → channel 개수 줄임 ⇒ 학습에 사용되는 3x3 convolution의 parameter 개수 줄임

-
ResNet은
Bottleneck구조를 만들기 위해서- 1x1 convolution으로 dimension reduction을 한 다음 + 다시 1x1 convolution을 이용하여 expansion
-
DenseNet은
Bottleneck구조를 만들기 위해서- 1x1 convolution으로 dimension reduction + but, expansion은 하지 않음
- 대신에 feature들의
concatenation을 이용하여 expansion 연산과 같은 효과를 만듦- (생각) feature들의 concatenation으로 채널 개수 expansion → ex. 6 + 4 + ... + 4
-
(공통점) 3x3 convolution 전에 1x1 convolution을 거쳐서 input feature map의 channel 개수를 줄임
-
(차이점) 다시 input feature map의 channel 개수 만큼 생성(ResNet)하는 대신 growth rate 만큼의 feature map을 생성(DenseNet) ⇒ 이를 통해 computational cost를 줄일 수 있음
✔️ Growth rate

-
input의 채널 개수 k_0와 이전 (l-1)개의 layer → H(x) → output으로, k feature maps (단, k_0 : input layer의 channel 개수)
- input : k_0+k*(l-1)
- output : k
-
Growth rate(= hyperparameter k) → 각 layer의 feature map의 channel 개수
-
각 feature map끼리 densely connection 되는 구조이므로 자칫 feature map의 channel 개수가 많을 경우, 계속해서 channel-wise로 concatenate 되면서 channel이 많아질 수 있음 ⇒ DenseNet에서는 각 layer의 feature map의 channel 개수로 작은 값을 사용
-
concatenation 연산을 하기 위해서 각 layer 에서의 output 이 똑같은 channel 개수가 되는 것이 좋음 → 1x1 convolution으로 growth rate 조절
-
위의 그림 1은 k(growth rate) = 4 인 경우를 의미
- 6 channel feature map인 input이 dense block의 4번의 convolution block을 통해 (6 + 4 + 4 + 4 + 4 = 22) 개의 channel을 갖는 feature map output으로 계산이 되는 과정
- DenseNet의 각 dense block의 각 layer마다 feature map의 channel 개수 또한 간단한 등차수열로 나타낼 수 있음
-
DenseNet은 작은 k를 사용 → (다른 모델에 비해) 좁은 layer로 구성 ⇒ 좁은 layer로 구성해도 DenseNet이 좋은 성능을 보이는 이유?
- Dense block내에서 각 layer들은 모든 preceding feature map에 접근 가능 (= 네트워크의 “collective knowledge”에 접근)
⇒ (생각) preceding feature map = 네트워크의 global state - growth rate k → 각 layer가 global state에 얼마나 많은 새로운 정보를 contribute할 것인지를 조절
- ⇒ 모든 layer가 접근할 수 있는 global state로 인해 DenseNet은 기존의 네트워크들과 같이 layer의 feature map을 복사해서 다른 layer로 넘겨주는 등의 작업을 할 필요가 없음 (= feature reuse)
- Dense block내에서 각 layer들은 모든 preceding feature map에 접근 가능 (= 네트워크의 “collective knowledge”에 접근)
✔️ Compression
-
Compression은 pooling layer(Transition layer)의 1x1 Convolution layer 에서 channel 개수(= feature map의 개수)를 줄여주는 비율 (hyperparameter θ)
- 본 논문에서는 θ=0.5로 설정 → transition layer를 통과하면 feature map의 개수(channel)이 절반으로 줄어들고, 2x2 average pooling layer를 통해 feature map의 가로 세로 크기 또한 절반으로 줄어듦
- θ=1로 설정 시 → feature map의 개수를 그대로 사용
1. 기울기 소실 문제(gradient vanishing) 완화

- 위 그림과 같이 DenseNet 또한 ResNet 처럼 gradient를 다양한 경로를 통해서 받을 수 있기 때문에 학습하는 데 도움이 됩니다.
2. feature propagation 강화

- 위 그림을 보면 앞단에서 만들어진 feature를 그대로 뒤로 전달을 해서 concatenation 하는 방법을 사용을 합니다. 따라서 feature를 계속해서 끝단 까지 전달하는 데 장점이 있습니다.
3. feature reuse
📎 Feature reuse
Feature reuse

-
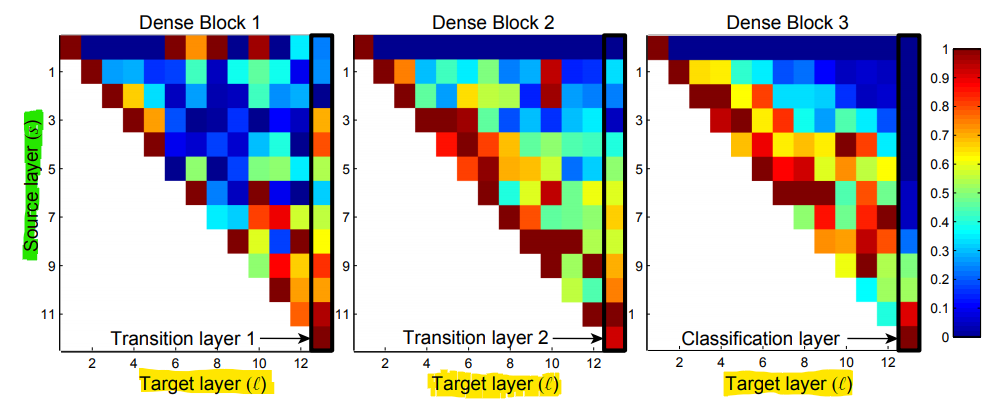
학습된 DenseNet의 각 layer가 실제로 preceding layer들의 feature map을 활용하는지를 실험
- 학습한 네트워크의 각 dense block에서, ℓ번째 convolution layer에서 s번째 layer로의 할당된 average absolute weight를 계산 (absolute는 음의 값을 갖는 weight를 고려한 것으로 보임)
-
위 그림은 dense block 내부에서 convolution layer들의 weight의 평균이 어떻게 분포되어있는지 보여줌
-
Pixel (s,ℓ)의 색깔은 dense block 내의 conv layer s와 ℓ을 연결하는 weight의 average L1 norm으로 인코딩 한 것 ⇒ 각 dense block의 weight들이 가지는 그 크기 값을 0 ~ 1 사이 범위로 normalization 한 결과
- 빨간색인 1에 가까울 수록 큰 값 ↔ 파란색인 0에 가까울수록 작은 값
-
실험 결과
-
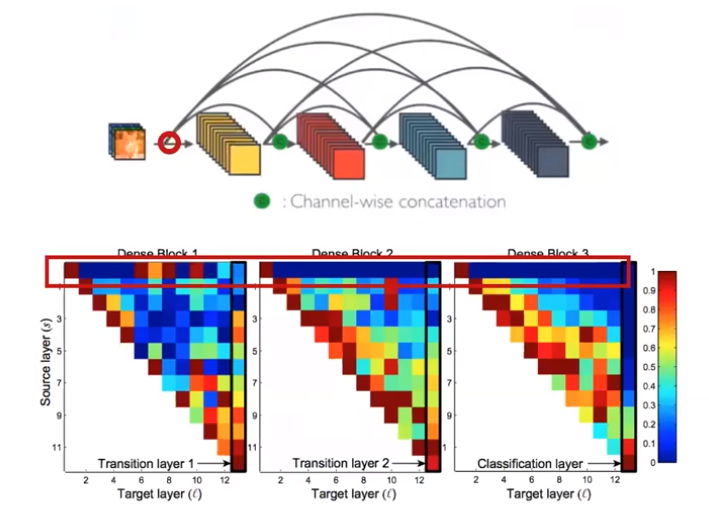
각 layer들이 동일한 block 내에 있는 preceding layer들에 weight를 분산 시킴 (∵ 각 열에서 weight가 골고루 spread되어 있음
- ⇒ Dense block 내에서, 실제로 later layer는 early layer의 feature map을 사용하고 있음
-
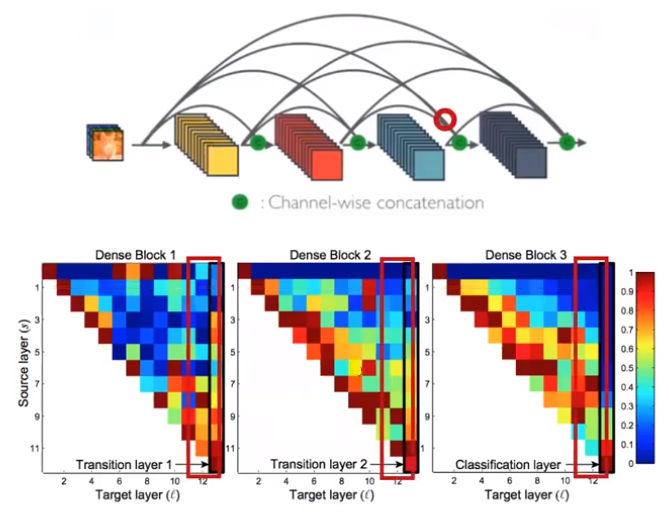
Transition layer도 preceding layer들에 weight를 분산 시킴 (∵ 가장 오른쪽 열에서 weight가 골고루 spread 되어 있음)
- ⇒ Dense block 내에서, 1번째 layer에서 가장 마지막 layer까지 information flow가 형성되어 있음
-
2, 3번째 dense block은 transition layer의 output에 매우 적은 weight를 일관되게 할당 (∵ 2, 3번째 dense block의 첫번째 행에서 weight가 거의 0에 가까움)
- ⇒ 2, 3번째 dense block의 transition layer output은 redundant features가 많아서 매우 적은 weight를 할당(중복된 정보들이 많아 모두 사용하지 않아도 된다는 의미)
- ⇒ DenseNet-BC에서 compression θ로 이러한 redundant feature들을 compress하는 현상과 일치
- (생각) Compression은 pooling layer(Transition layer)의 1x1 Convolution layer 에서 channel 개수(= feature map의 개수)를 줄여주는 비율 (hyperparameter θ)이므로, 중복된 정보들이 transition layer에서 제거된다는 의미 → channel 개수 감소
-
마지막 classification layer는 전체 dense block의 weight를 사용하긴 하지만, early layer보다 later layer의 feature map을 더 많이 사용함 (∵ 3번째 dense block의 가장 마지막 열에서 weight가 아래쪽으로 치우쳐 있음)
- ⇒ High-level feature가 later layer에 더 많이 존재함
-
참고 : DenseNet (Densely connected convolution networks) - gaussian37
- 위 그림은 각 source → target으로 propagation된 weight의 값 분포를 나타냄
- 세로축
Source layer→ layer가 propagation 할 때, 그 Source에 해당하는 layer가 몇번째 layer인 지 나타냄 - 가로축
Target layer→ Source에서 부터 전파된 layer의 목적지가 어디인지 나타냄 - ex. dense block 1의 세로축(5), 가로축 (8)에 교차하는 작은 사각형이 의미하는 것은 dense block 1에서 5번째 layer에서 시작하여 8번째 layer로 propagation 된
weight
- ex. 각 dense block의 Source가 1인 부분들을 살펴 보면 각 Block의 첫 layer에서 펼쳐진 propagation에 해당 (위 그림에서 빨간색 동그라미에 해당하는 부분)
- ex. 각 dense block의 Target이 12인 부분들을 살펴 보면 다양한 Source에서 weight들이 모이게 된 것을 볼 수 있음 (위 그림에서 빨간색 동그라미에 해당하는 부분)
-
4. parameter 개수 줄임
1. channel이 늘어남으로써 메모리와 computational complexity 증가
📎 Experiments
-
CIFAR
- 32 x 32 pixels
- CIFAR-10 : 10 classes / CIFAR-100 : 100 classes
- training set : 50,000 images / test set : 10,000 images / validations set : 5,000 training images
- data augmentation : mirroring / shifting
- preprocessing : normalize the data using channel means + standard deviations
-
SVHN
- 32 x 32 digit images
- training set : 73,257 images / test set : 26,032 images / validation set : 6,000 images
- additional training set : 531,131 images
-
ImageNet
- training set : 1,2 million images / validation set : 50,000 images
- 1000 classes
- data augmentation + 10-crop/single-crop
- 224 x 224 images
-
stochastic gradient descent (SGD)로 train
-
weight decay : 10^{-4}
-
Nesterov momentum : 0.9 without dampening
-
CIFAR, SVHN
- batch size : 64
- 300 or 40 epochs
- learning rate : 0.1 → training epoch가 50%, 75%일 때 0.1배
-
ImageNet
- batch size : 256
- 90 epochs
- learning rate : 0.1 → 30 epochs, 60 epochs마다 0.1배
❔momentum : parameter를 update할 떄, 현재 gradient에 과거에 누적했던 gradient를 어느정도 보정해서 과거의 방향을 반영하는 것

Accuracy
- DenseNet-BC with {L=190, k=40} → C10+, C100+에 대해 성능 좋음
- C10/C100에 대해, FractalNet with drop path-regularization 과 비교해서 error가 30% 적음
- DenseNet-BC with {L=100, k=24} → C10, C100, SVHN에 대해 성능 좋음
- SVHN이 비교적 쉬운 task이기 때문에, 깊은 모델은 overfitting할 수 있어서, DenseNet-BC with {L=250, k=24} 는 더 이상 성능이 개선되지 않음
Capacity
- compression과 bottleneck layer가 없을 때, L과 k가 커질수록 → DenseNet의 성능이 좋아짐
- 모델이 더 크고(k) 더 깊어질수록(L) 더 많고 풍부한 representation을 학습 가능
- paramter 개수가 늘어날수록 → error 줄어듦
- Error : 5.24% → 4.10% → 3.74%
- Number of parameters : 1.0M → 7.0M → 27.2M
- Overfitting이나 optimization(= parameter update) difficulty가 나타나지 않음
Parameter Efficiency
- DenseNet-BC with bottleneck structure + transition layer에서의 차원 축소(dimension reduction)는 parameter의 효율성을 높임
- FractalNet과 Wide ResNets는 30M parameter이고, 250-layer DenseNet은 15.3M parameter 인데, DenseNet의 성능이 더 좋음
Overfitting

- DenseNet은 overfitting 될 가능성이 적음
- DenseNet-BC with bottleneck structure와 compression layer가 overfitting을 방지하는데 도움
-
ResNet-1001과 DenseNet-BC(L=100,k=12)의 error를 비교 (맨 오른쪽 그래프)
- ResNet-1001은 DenseNet-BC에 비해 training loss는 더 낮지만, test error는 비슷한 것을 알 수 있는데, 이는 DenseNet이 ResNet보다 overfitting이 일어나는 경향이 더 적다는 것을 보여줌

- Table 3(왼쪽 표)은 DenseNet의 ImageNet에서의 single crop, 10-crop validation error
- Figure 3(오른쪽 그림)는 DenseNet과 ResNet의 single crop top-1 validation error를 parameter 개수와 flops를 기준으로 나타냄
- DenseNet-201 with 20M parameters와 101-layer ResNet with more than 40 parameter가 비슷한 성능
reference
논문 | https://arxiv.org/abs/1608.06993
참고자료 | https://csm-kr.tistory.com/10